

Multi-stage query engine (v2)
An overview of the multi-stage query engine.
This document is an overview of the new multi-stage query engine (also known as v2 query engine).
What do you need to know about the multi-stage engine?
The multi-stage engine is the new query execution engine released in Pinot 1.0.0. Here are some useful links:
Get started using multi-stage engine
Find supported query syntax to query the multi-stage engine, including Window functions and JOIN features
See limitations and troubleshooting tips for the multi-stage query engine
How does the multi-stage handle nulls?
Since Pinot 1.1.0, the multi-stage query engine supports null handling if column based null storing is enabled. For more information, see the Null value support section. Before Pinot 1.1.0, the multi-stage query engine treated all columns as non-nullable.
Why use the multi-stage query engine?
You must use the multi-stage query engine (v2) to query distributed joins, window functions, and other multi-stage operators in real-time.
The multi-stage query engine is built to run real-time, complex ANSI SQL (ISO/IEC 9075). Highlights include joins and data correlations, particularly optimized for dynamic broadcast fact-dim joins, and partitioned-based or colocated table joins.
When not to use the multi-stage query engine?
Although the multi-stage query engine can generally execute any complex ANSI SQL, it's not designed to run generic ANSI SQL in the most efficient way.
Some use cases to avoid:
Large-scale, long-running queries designed to access and transform entire datasets are not recommended, as the multistage engine is a pure in-memory system.
Complex correlation, join algorithms that touch many tables or have many non-trivial join conditions are not recommended.
Long-running, complex queries such as ETL-type (extract, transform, and load) use cases are not recommended.
Multi-stage query execution model
The multi-stage query engine improves query performance over the single-stage scatter-gather query engine ( v1), effectively decoupling the data exchange layer and the query engine layer.
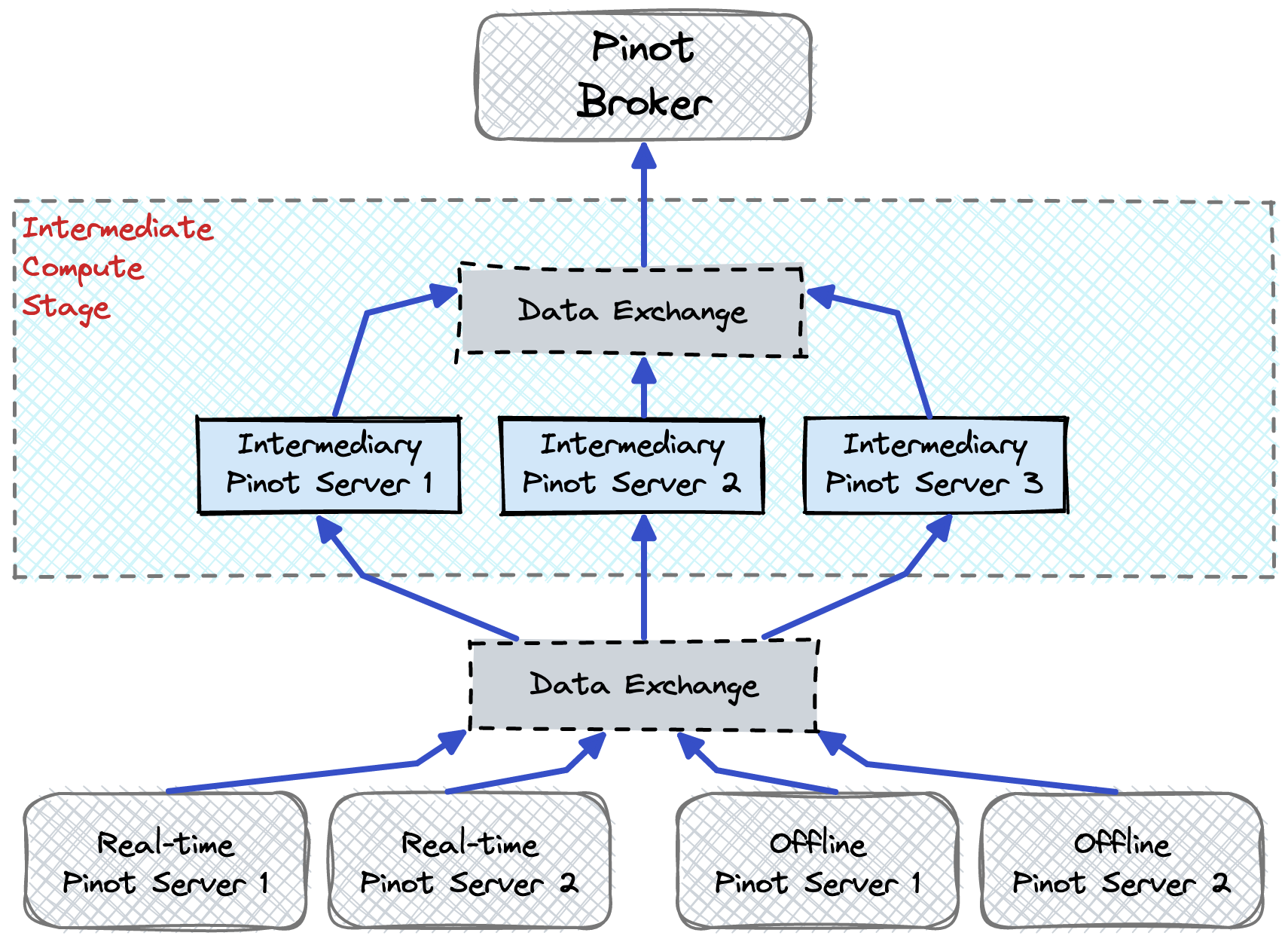
The intermediate compute stage includes a set of processing servers and a data exchange mechanism.
Processing servers in the intermediate compute stage can be assigned to any Pinot component. Multiple servers can process data in the intermediate stage; the goal being to offload the computation from the brokers. Each server in the intermediate stage executes the same processing logic, but against different sets of data.
The data exchange service coordinates the transfer of the different sets of data to and from the processing servers.
The multi-stage query engine also includes a new query plan optimizer to produce optimal process logic in each stage and minimize data shuffling overhead.
How queries are processed
With a multi-stage query engine, Pinot first breaks down the single scatter-gather query plan used in v1 into multiple query sub-plans that run across different sets of servers. We call these sub-plans “stage plans,” and refer to each execution as a “stage.”
Stages are a logical entity and are connected in a tree like structure where the output of one stage is the input to the next stage. The stages in the leaves of the plan are the ones that read from the tables and the stages in the root are the ones that send the final results to the client.
Therefore we can define three types of stages:
Leaf stages: These stages read from the tables and send the data to the next stage. Each leaf stage reads from exactly one table (although a single stage can read from the offline and real-time versions of the same hybrid table).
Intermediate stages: These stages process the data and send it to the next stage.
Root stages: These stages send the final results to the client. There is only one for each query.
As said above, stages are logical entities and they are not directly executed. Instead, Pinot Broker assigns a parallelism to each stage and defines which servers are going to execute each stage. For example, if a stage has a parallelism of 10, then 10 servers will execute that stage in parallel.
Consider the following JOIN query example, which illustrates the breakdown of a query into stages. This query joins a real-time orderStatus table with an offline customer table.
Leaf stages
In the leaf stages, the query is processed as follows:
Real-time servers execute the filter query on the
orderStatustable:
Offline servers execute the filter query offline
customertable:
The data exchange service shuffles data shuffle, so all data with the same unique customer ID is sent to the same processing server for the next stage.
Intermediate stages
On each processing server, an inner JOIN is performed.
Each intermediary servers (shown in Figure 1: Multi-stage query execution model) performs a local join, and runs the same join algorithm, but on different
uids.The result of these joins is sent to the next stage, which in this case is the root stage.
Root stage
After the join algorithm completes, the results are sent back to the broker, and then sent to clients.
How to optimize multi-stage queries
Multi-stage queries are more expressive than single-stage queries, allowing to execute more complex logic in Pinot. However, this flexibility comes with a cost: the more complex the query, the more resources it will consume.
In order to optimize multi-stage queries, you can follow these guidelines:
Study the explain plan.
Execute the query and analyze the stage stats.
Last updated
Was this helpful?