Steps for setting up a Pinot cluster and a real-time table which consumes from the GitHub events stream.
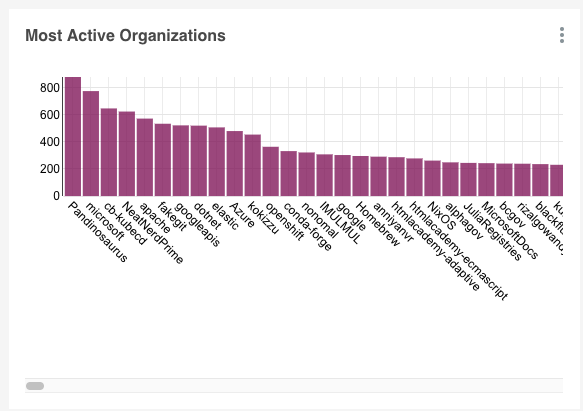
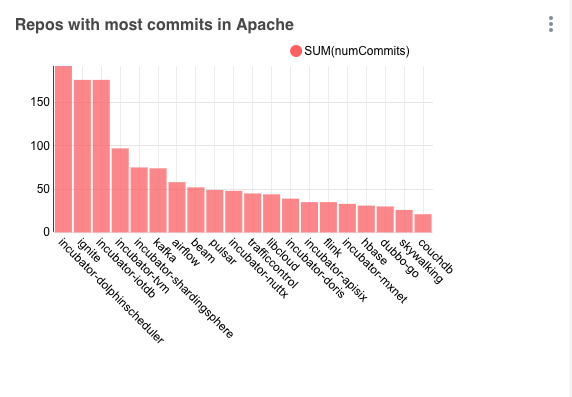
In this recipe you will set up an Apache Pinot cluster and a real-time table which consumes data flowing from a GitHub events stream. The stream is based on GitHub pull requests and uses Kafka.
In this recipe you will perform the following steps:
Set up a Pinot cluster, to do which you will:
a. Start zookeeper.
b. Start the controller.
c. Start the broker.
d. Start the server.
Set up a Kafka cluster.
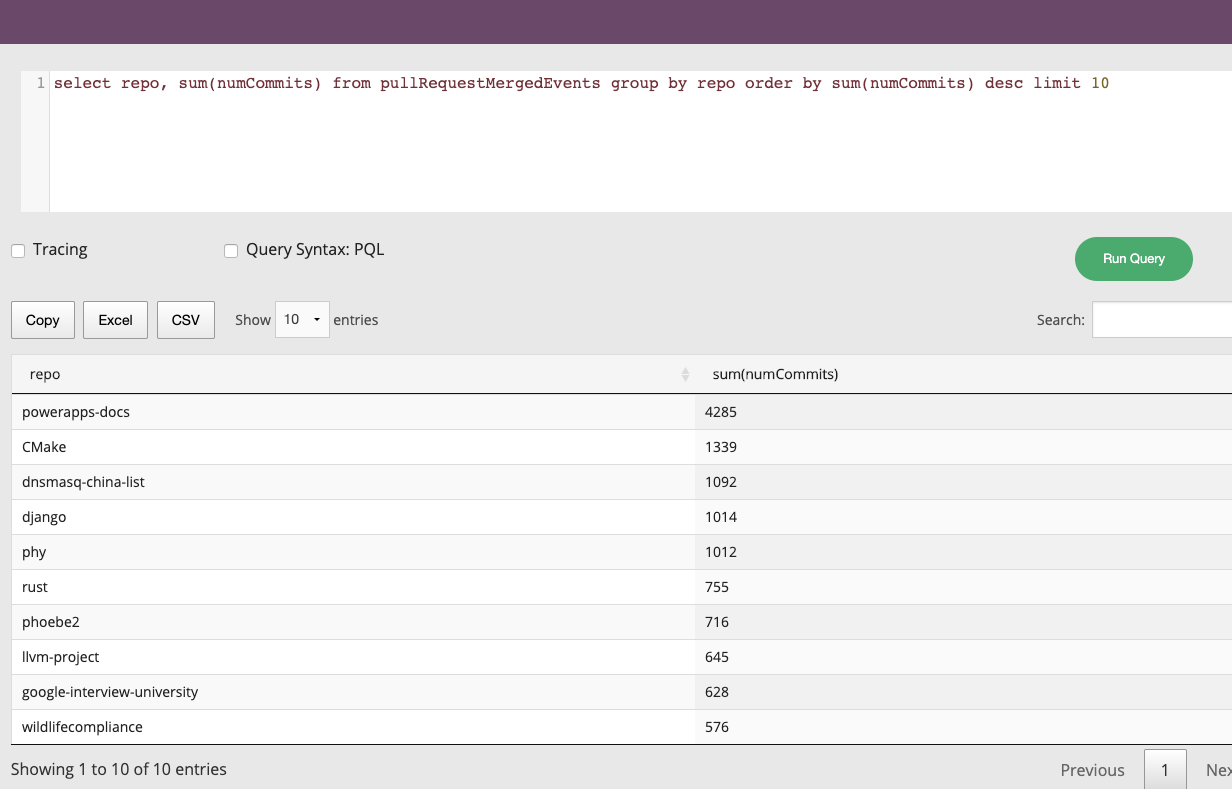
Create a Kafka topic, which will be called pullRequestMergedEvents.
Create a real-time table called pullRequestMergedEvents and a schema.
Start a task which reads from the GitHub events API and publishes events about merged pull requests to the topic.
The schema is present at examples/stream/githubEvents/pullRequestMergedEvents_schema.json and is also pasted below
The table config is present at examples/stream/githubEvents/docker/pullRequestMergedEvents_realtime_table_config.json and is also pasted below.
Note
If you're setting this up on a pre-configured cluster, set the properties stream.kafka.zk.broker.url and stream.kafka.broker.list correctly, depending on the configuration of your Kafka cluster.
Add the table and schema using the following command:
Publish events
Start streaming GitHub events into the Kafka topic:
Create a Kafka topic called pullRequestMergedEvents for the demo.
Add a Pinot table and schema
Schema can be found at /examples/stream/githubevents/ in the release, and is also pasted below:
The table config can be found at /examples/stream/githubevents/ in the release, and is also pasted below.
Note
If you're setting this up on a pre-configured cluster, set the properties stream.kafka.zk.broker.url and stream.kafka.broker.list correctly, depending on the configuration of your Kafka cluster.
Add the table and schema using the command:
Publish events
Start streaming GitHub events into the Kafka topic
If you already have a Kubernetes cluster with Pinot and Kafka (see Running Pinot in Kubernetes), first create the topic, then set up the table and streaming using