

Pinot managed Offline flows
The Pinot managed offline flows feature allows a user to simply set up a REALTIME table, and let Pinot manage populating the OFFLINE table. For complete motivation and reasoning, refer to the design doc above.
When to use
There are 3 kinds of tables in Pinot
OFFLINE only - this feature is not relevant for this mode.
REALTIME only - this feature is built for this mode. While having a real-time-only table setup (versus a hybrid table setup) is certainly lightweight and lesser operations, you lose some of the flexibility that comes with having a corresponding OFFLINE table.
For example, in real-time only mode, it is impossible to backfill a specific day's data, even if you have that data available offline somewhere, whereas you could've easily run a one off backfill job to correct data in an OFFLINE table.
It is also not possible to re-bootstrap the table using some offline data, as data for the REALTIME table strictly must come in through a stream. In OFFLINE tables, it is very easy to run jobs and replace segments in the table.
In REALTIME tables, the data often tends to be highly granular and we achieve very little aggregations. OFFLINE tables let you look at bigger windows of data hence achieving rollups for time column, aggregations across common dimensions, better compression and even dedup.
This feature will automatically manage the movement of the data to a corresponding OFFLINE table, so you don't have to write any offline jobs.
HYBRID table - If you already have a hybrid table this feature again may not be relevant to you. But you could explore using this to replace your offline push jobs, and simply keep them for backfills.
How this works
The Pinot managed offline flows feature will move records from the REALTIME table to the OFFLINE table, one time window at a time. For example, if the REALTIME table has records with timestamp starting 10-24-2020T13:56:00, then the Pinot managed offline flows will move records for the time window [10-24-2020, 10-25-2020) in the first run, followed by [10-25-2020, 10-26-2020) in the next run, followed by [10-26-2020, 10-27-2020) in the next run, and so on. This window length of 1d is just the default, and it can be configured to any length of your choice.
Note
Only completed (ONLINE) segments of the real-time table are used for movement. If the window's data falls into the CONSUMING segment, that run will be skipped. That window will be processed in a future run when all data has made it to the completed segments.
This feature uses the pinot-minions and the Helix Task Executor framework. This feature consists of 2 parts
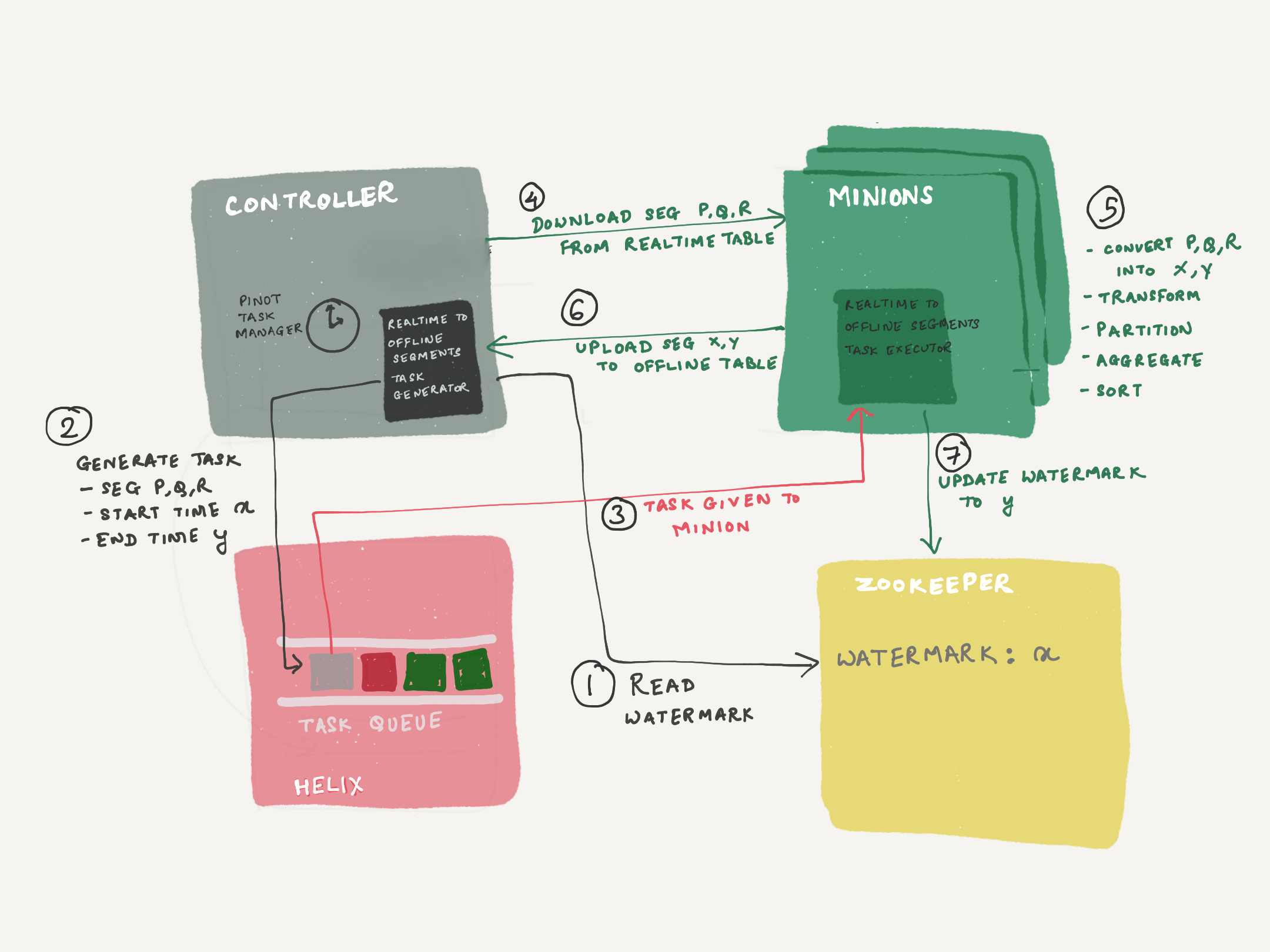
RealtimeToOfflineSegmentsTaskGenerator - This is the minion task scheduler, which schedules tasks of type "RealtimeToOfflineSegmentsTask". This task is scheduled by the controller periodic task - PinotTaskManager. A watermark is maintained in zookeeper, which is the end time of the time window last successfully processed. The task generator refers to this watermark, to determine the start of the time window, for the next task it generates. The end time is calculated based on the window length (configurable, 1d default). The task generator will find all segments which have data in [start, end), and set it into the task configs, along with the start and end. The generator will not schedule a new task, unless the previous task has COMPLETED (or been stuck for over 24h). This is to ensure that we always move records in sequential time windows (exactly mimicking offline flows), because out-of-order data pushes will mess with the time boundary calculation of the hybrid table.
RealtimeToOfflineSegmentsTaskExecutor - This is a minion task executor to execute the RealtimeToOfflineSegmentsTask generated by the task generator. These tasks are run by the pinot-minion component. The task executor will download all segments from the REALTIME table, as indicated in the task config. Using the SegmentProcessorFramework, it will extract data for [start, end), build the segments, and push them to the OFFLINE table. The segment processor framework will do any required partitioning & sorting based on the OFFLINE table config. Before exiting from the task, it will update the watermark in zookeeper, to reflect the end time of the time window processed.
Config
Step 0: Start a pinot-minion
Step 1: Set up your REALTIME table. Add "RealtimeToOfflineSegmentsTask" in the task configs
Step 2: Create the corresponding OFFLINE table
Step 3: Enable PinotTaskManager
The PinotTaskManager periodic task is disabled by default. Enable this using one of the 2 methods described in Auto-Schedule section. Set the frequency to some reasonable value (frequently is better, as extra tasks will not be scheduled unless required). Controller will need a restart after setting this config.
Step 4: Advanced configs
If needed, you can add more configs to the task configs in the REALTIME table, such as
where,
bucketTimePeriod
Time window size for each run. Adjust this to change the time window. E.g. if set to 1h, each task will process 1h data at a time.
1d
bufferTimePeriod
Buffer time. Will not schedule tasks unless time window is older than this buffer. Configure this according to how late you expect your data. E.g. if your system can emit events later than 3d, set this to 3d to make sure those are included.
Note: Once a given time window has been processed, it will never be processed again.
2d
roundBucketTimePeriod
(supported since release 0.8.0)
Round the time value before merging the rows. This is useful if time column is highly granular in the REALTIME table and is not needed by the application. In the OFFLINE table you can rollup the time values (e.g. milliseconds granularity in REALTIME table, but okay with minute level granularity in the application - set to 1m
None
mergeType
(supported since release 0.8.0)
Allowed values are concat - no aggregations rollup - perform metrics aggregations across common dimensions + time dedup - deduplicates rows with the same values
concat
{metricName}.aggregationType
Aggregation function to apply to the metric for aggregations. Only applicable for rollup case. Allowed values are sum, max, min
sum
maxNumRecordsPerSegment
Control the number of records you want in a segment generated. Useful if the time window has many records, but you don't want them all in the same segment.
5,000,000
The following properties are deprecated/removed in release 0.8.0
timeColumnTransformFunction (removed): Use ingestion transforms or roundBucketTimePeriod instead
collectorType (deprecated): Replaced by mergeType
Limitations & possible enhancements
Late data problem
Once the time window has moved forward, it will never be processed again. If some data arrives into your stream after the window has moved on, that data will never be processed. Set the "bufferTimePeriod" accordingly, to account for late data issues in your setup. We will potentially consider ability to schedule ad hoc one-off tasks. For example, user can specify "rerun for day 10/23", which would sweep all segments again and collect data, replacing the old segments. This will help resolve the problem of data arriving very late.
Backfill/bootstrap
This feature automates the daily/hourly pushes to the offline counterpart of your hybrid table. And since you now have an OFFLINE table created, it opens up the possibility of doing an ad hoc backfill or re-bootstrap. However, there are no mechanisms for doing an automated backfill/re-bootstrap from some offline data. You still have to write your own flows for such scenarios.
Memory constraints
The segments download, data extraction, transformation, aggregations, sorting all happens on a single minion node for every run. You will need to be mindful of the memory available on the minion machine. Adjust the bucketSize and maxNumRecordsPerSegment if you are running into memory issues.
We will potentially introduce smarter config adjustments based on memory, or consider using Spark/Hadoop MR.
\
Was this helpful?