

0.11.0
Summary
Apache Pinot 0.11.0 has introduced many new features to extend the query abilities, e.g. the Multi-Stage query engine enables Pinot to do distributed joins, more sql syntax(DML support), query functions and indexes(Text index, Timestamp index) supported for new use cases. And as always, more integrations with other systems(E.g. Spark3, Flink).
Note: there is a major upgrade for Apache Helix to 1.0.4, so make sure you upgrade the system in the order of:
Helix Controller -> Pinot Controller -> Pinot Broker -> Pinot server
Multi-Stage Query Engine
The new multi-stage query engine (a.k.a V2 query engine) is designed to support more complex SQL semantics such as JOIN, OVER window, MATCH_RECOGNIZE and eventually, make Pinot support closer to full ANSI SQL semantics. More to read: https://docs.pinot.apache.org/developers/advanced/v2-multi-stage-query-engine
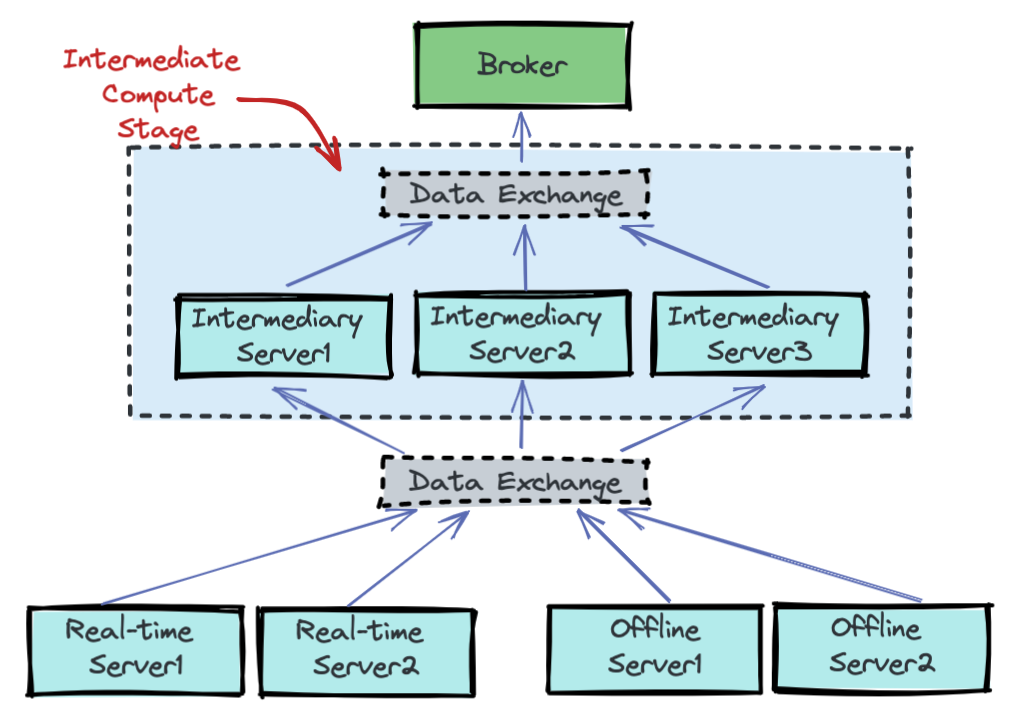
Pause Stream Consumption on Apache Pinot
Pinot operators can pause real-time consumption of events while queries are being executed, and then resume consumption when ready to do so again.\
More to read: https://medium.com/apache-pinot-developer-blog/pause-stream-consumption-on-apache-pinot-772a971ef403
Gap-filling function
The gapfilling functions allow users to interpolate data and perform powerful aggregations and data processing over time series data. More to read: https://www.startree.ai/blog/gapfill-function-for-time-series-datasets-in-pinot
Add support for Spark 3.x (#8560)
Long waiting feature for segment generation on Spark 3.x.
Add Flink Pinot connector (#8233)
Similar to the Spark Pinot connector, this allows Flink users to dump data from the Flink application to Pinot.
Show running queries and cancel query by id (#9171)
This feature allows better fine-grained control on pinot queries.
Timestamp Index (#8343)
This allows users to have better query performance on the timestamp column for lower granularity. See: https://docs.pinot.apache.org/basics/indexing/timestamp-index
Native Text Indices (#8384)
Wanna search text in real time? The new text indexing engine in Pinot supports the following capabilities:
New operator: LIKE
New operator: CONTAINS
Native text index, built from the ground up, focusing on Pinot’s time series use cases and utilizing existing Pinot indices and structures(inverted index, bitmap storage).
Real Time Text Index
Read more: https://medium.com/@atri.jiit/text-search-time-series-style-681af37ba42e
Adding DML definition and parse SQL InsertFile (#8557)
Now you can use INSERT INTO [database.]table FROM FILE dataDirURI OPTION ( k=v ) [, OPTION (k=v)]* to load data into Pinot from a file using Minion. See: https://docs.pinot.apache.org/basics/data-import/from-query-console
Deduplication (#8708)
This feature supports enabling deduplication for real-time tables, via a top-level table config. At a high level, primaryKey (as defined in the table schema) hashes are stored into in-memory data structures, and each incoming row is validated against it. Duplicate rows are dropped.
The expectation while using this feature is for the stream to be partitioned by the primary key, strictReplicaGroup routing to be enabled, and the configured stream consumer type to be low level. These requirements are therefore mandated via table config API's input validations.
Functions support and changes:
Add support for functions arrayConcatLong, arrayConcatFloat, arrayConcatDouble (#9131)
Add support for regexpReplace scalar function (#9123)
Add support for Base64 Encode/Decode Scalar Functions (#9114)
Optimize like to regexp conversion to do not include unnecessary ^._ and ._$ (#8893)
Support DISTINCT on multiple MV columns (#8873)
Support DISTINCT on single MV column (#8857)
Add histogram aggregation function (#8724)
Optimize dateTimeConvert scalar function to only parse the format once (#8939)
Support conjugates for scalar functions, add more scalar functions (#8582)
Add PercentileSmartTDigestAggregationFunction (#8565)
Simplify the parameters for DistinctCountSmartHLLAggregationFunction (#8566)
add scalar function for cast so it can be calculated at compile time (#8535)
Scalable Gapfill Implementation for Avg/Count/Sum (#8647)
Add commonly used math, string and date scalar functions in Pinot (#8304)
Datetime transform functions (#8397)
Scalar function for url encoding and decoding (#8378)
Add support for IS NULL and NOT IS NULL in transform functions (#8264)
Support st_contains using H3 index (#8498)
The full list of features introduced in this release
add query cancel APIs on controller backed by those on brokers (#9276)
Add an option to search input files recursively in ingestion job. The default is set to true to be backward compatible. (#9265)
Adding endpoint to download local log files for each component (#9259)
Add metrics to track controller segment download and upload requests in progress (#9258)
add a freshness based consumption status checker (#9244)
Force commit consuming segments (#9197)
Adding kafka offset support for period and timestamp (#9193)
Make upsert metadata manager pluggable (#9186)
Adding logger utils and allow change logger level at runtime (#9180)
Proper null handling in equality, inequality and membership operators for all SV column data types (#9173)
support to show running queries and cancel query by id (#9171)
Enhance upsert metadata handling (#9095)
Proper null handling in Aggregation functions for SV data types (#9086)
Add support for IAM role based credentials in Kinesis Plugin (#9071)
Task genrator debug api (#9058)
[colocated-join] Adds Support for instancePartitionsMap in Table Config (#8989)
Support pause/resume consumption of real-time tables (#8986)
Add Protocol Buffer Stream Decoder (#8972)
Update minion task metadata ZNode path (#8959)
add /tasks/{taskType}/{tableNameWithType}/debug API (#8949)
Defined a new broker metric for total query processing time (#8941)
Proper null handling in SELECT, ORDER BY, DISTINCT, and GROUP BY (#8927)
fixing REGEX OPTION parser (#8905)
Enable key value byte stitching in PulsarMessageBatch (#8897)
Add property to skip adding hadoop jars to package (#8888)
Support DISTINCT on multiple MV columns (#8873)
Implement Mutable FST Index (#8861)
Support DISTINCT on single MV column (#8857)
Add controller API for reload segment task status (#8828)
Spark Connector, support for TIMESTAMP and BOOLEAN fields (#8825)
allow up to 4GB per bitmap index (#8796)
Deprecate debug options and always use query options (#8768)
Streamed segment download & untar with rate limiter to control disk usage (#8753)
Improve the Explain Plan accuracy (#8738)
allow to set https as the default scheme (#8729)
Add histogram aggregation function (#8724)
Allow table name with dots by a PinotConfiguration switch (#8713)
Disable Groovy function by default (#8711)
Deduplication (#8708)
Add pluggable client auth provider (#8670)
Adding pinot file system command (#8659)
Allow broker to automatically rewrite expensive function to its approximate counterpart (#8655)
allow to take data outside the time window by negating the window filter (#8640)
Support BigDecimal raw value forward index; Support BigDecimal in many transforms and operators (#8622)
Ingestion Aggregation Feature (#8611)
Enable uploading segments to real-time tables (#8584)
Package kafka 0.9 shaded jar to pinot-distribution (#8569)
Simplify the parameters for DistinctCountSmartHLLAggregationFunction (#8566)
Add PercentileSmartTDigestAggregationFunction (#8565)
Add support for Spark 3.x (#8560)
Adding DML definition and parse SQL InsertFile (#8557)
endpoints to get and delete minion task metadata (#8551)
Add query option to use more replica groups (#8550)
Only discover public methods annotated with @ScalarFunction (#8544)
Support single-valued BigDecimal in schema, type conversion, SQL statements and minimum set of transforms. (#8503)
Add connection based FailureDetector (#8491)
Add endpoints for some finer control on minion tasks (#8486)
Add adhoc minion task creation endpoint (#8465)
Rewrite PinotQuery based on expression hints at instance/segment level (#8451)
Allow disabling dict generation for High cardinality columns (#8398)
add segment size metric on segment push (#8387)
Implement Native Text Operator (#8384)
Change default memory allocation for consuming segments from on-heap to off-heap (#8380)
New Pinot storage metrics for compressed tar.gz and table size w/o replicas (#8358)
add a experiment API for upsert heap memory estimation (#8355)
Timestamp type index (#8343)
Upgrade Helix to 1.0.4 in Pinot (#8325)
Allow overriding expression in query through query config (#8319)
Always handle null time values (#8310)
Add prefixesToRename config for renaming fields upon ingestion (#8273)
Added multi column partitioning for offline table (#8255)
Automatically update broker resource on broker changes (#8249)
Vulnerability fixs
Pinot has resolved all the high-level vulnerabilities issues:
Add a new workflow to check vulnerabilities using trivy (#9044)
Disable Groovy function by default (#8711)
Upgrade netty due to security vulnerability (#8328)
Upgrade protobuf as the current version has security vulnerability (#8287)
Upgrade to hadoop 2.10.1 due to cves (#8478)
Upgrade Helix to 1.0.4 (#8325)
Upgrade thrift to 0.15.0 (#8427)
Upgrade jetty due to security issue (#8348)
Upgrade netty (#8346)
Upgrade snappy version (#8494)
Bug fixs
Nested arrays and map not handled correctly for complex types (#9235)
Fix empty data block not returning schema (#9222)
Allow mvn build with development webpack; fix instances default value (#9179)
Fix the race condition of reflection scanning classes (#9167)
Fix ingress manifest for controller and broker (#9135)
Fix jvm processors count (#9138)
Fix grpc query server not setting max inbound msg size (#9126)
Fix upsert replace (#9132)
Fix the race condition for partial upsert record read (#9130)
Fix log msg, as it missed one param value (#9124)
Fix authentication issue when auth annotation is not required (#9110)
Fix segment pruning that can break server subquery (#9090)
Fix the NPE for ADLSGen2PinotFS (#9088)
Fix cross merge (#9087)
Fix LaunchDataIngestionJobCommand auth header (#9070)
Fix catalog skipping (#9069)
Fix adding util for getting URL from InstanceConfig (#8856)
Fix string length in MutableColumnStatistics (#9059)
Fix instance details page loading table for tenant (#9035)
Fix thread safety issue with java client (#8971)
Fix allSegmentLoaded check (#9010)
Fix bug in segmentDetails table name parsing; style the new indexes table (#8958)
Fix pulsar close bug (#8913)
Fix REGEX OPTION parser (#8905)
Avoid reporting negative values for server latency. (#8892)
Fix getConfigOverrides in MinionQuickstart (#8858)
Fix segment generation error handling (#8812)
Fix multi stage engine serde (#8689)
Fix server discovery (#8664)
Fix Upsert config validation to check for metrics aggregation (#8781)
Fix multi value column index creation (#8848)
Fix grpc port assignment in multiple server quickstart (#8834)
Spark Connector GRPC reader fix for reading real-time tables (#8824)
Fix auth provider for minion (#8831)
Fix metadata push mode in IngestionUtils (#8802)
Misc fixes on segment validation for uploaded real-time segments (#8786)
Fix a typo in ServerInstance.startQueryServer() (#8794)
Fix the issue of server opening up query server prematurely (#8785)
Fix regression where case order was reversed, add regression test (#8748)
Fix dimension table load when server restart or reload table (#8721)
Fix when there're two index filter operator h3 inclusion index throw exception (#8707)
Fix the race condition of reading time boundary info (#8685)
Fix pruning in expressions by max/min/bloom (#8672)
Fix GcsPinotFs listFiles by using bucket directly (#8656)
Fix column data type store for data table (#8648)
Fix the potential NPE for timestamp index rewrite (#8633)
Fix on timeout string format in KinesisDataProducer (#8631)
Fix bug in segment rebalance with replica group segment assignment (#8598)
Fix the upsert metadata bug when adding segment with same comparison value (#8590)
Fix the deadlock in ClusterChangeMediator (#8572)
Fix BigDecimal ser/de on negative scale (#8553)
Fix table creation bug for invalid real-time consumer props (#8509)
Fix the bug of missing dot to extract sub props from ingestion job filesytem spec and minion segmentNameGeneratorSpec (#8511)
Fix ChildTraceId when using multiple child threads, make them unique (#8443)
Fix the group-by reduce handling when query times out (#8450)
Fix a typo in BaseBrokerRequestHandler (#8448)
Fix TIMESTAMP data type usage during segment creation (#8407)
Fix async-profiler install (#8404)
Fix ingestion transform config bugs. (#8394)
Fix upsert inconsistency by snapshotting the validDocIds before reading the numDocs (#8392)
Fix bug when importing files with the same name in different directories (#8337)
Fix the missing NOT handling (#8366)
Fix setting of metrics compression type in RealtimeSegmentConverter (#8350)
Fix segment status checker to skip push in-progress segments (#8323)
Fix datetime truncate for multi-day (#8327)
Fix redirections for routes with access-token (#8285)
Fix CSV files surrounding space issue (#9028)
Fix suppressed exceptions in GrpcBrokerRequestHandler(#8272)
Was this helpful?