

Advanced Pinot Setup
Start Pinot components (scripts or docker images)
Set up Pinot by starting each component individually
Start Pinot Components using docker
Prerequisites
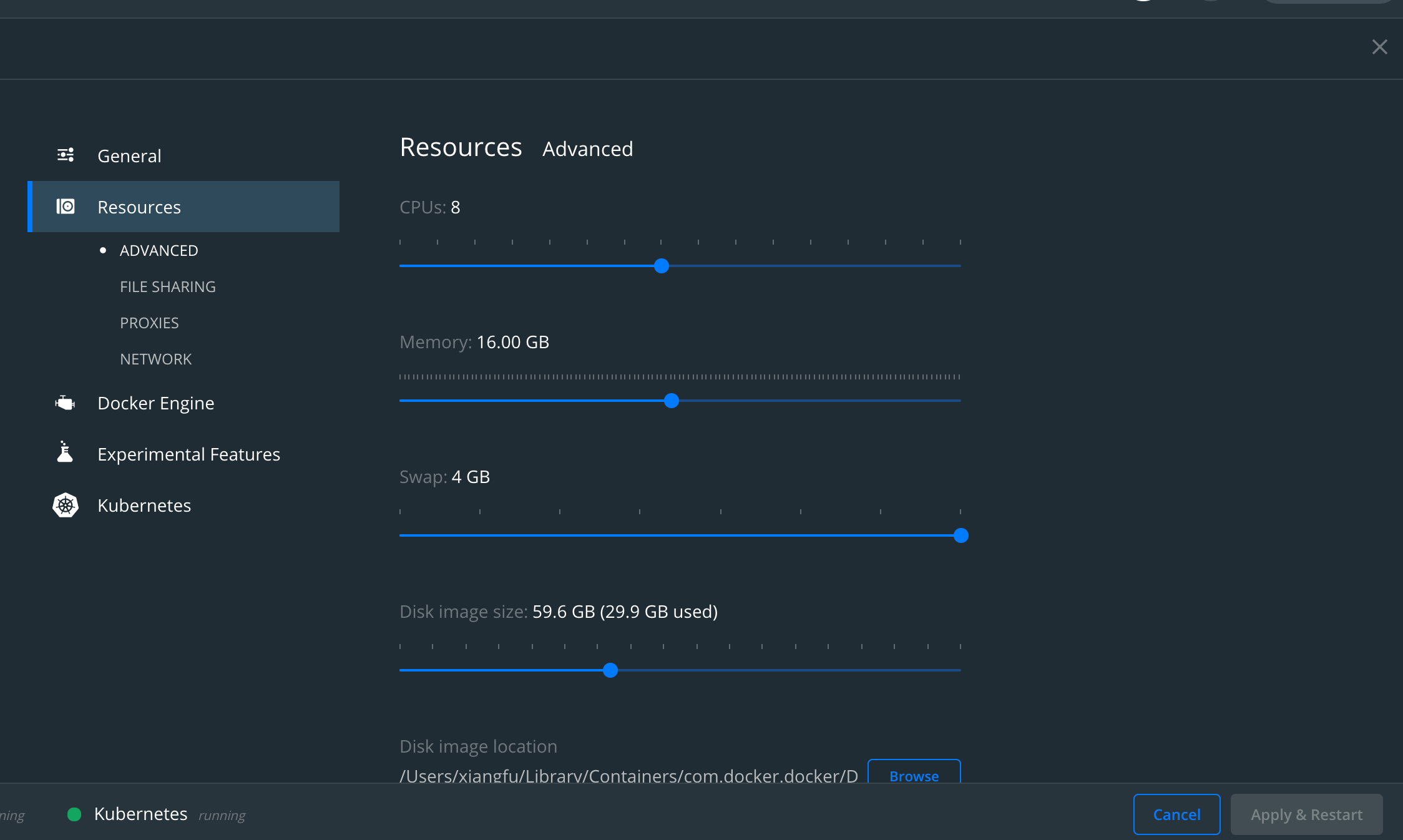
If running locally, ensure your docker cluster has enough resources, below is a sample config.
Pull Docker image
You can try out pre-built Pinot all-in-one Docker image.
(Optional) You can also follow the instructions here to build your own images.
0. Create a network
Create an isolated bridge network in Docker.
1. Start Zookeeper
Start Zookeeper in daemon.
Start ZKUI to browse Zookeeper data at http://localhost:9090.
2. Start Pinot Controller
Start Pinot Controller in daemon and connect to Zookeeper.
3. Start Pinot Broker
Start Pinot Broker in daemon and connect to Zookeeper.
4. Start Pinot Server
Start Pinot Server in daemon and connect to Zookeeper.
Now all Pinot related components are started as an empty cluster.
You can run below command to check container status.
Sample Console Output
Download Pinot Distribution from http://pinot.apache.org/download/
Start Pinot components via launcher scripts
Start Zookeeper
Start Pinot Controller
See controller page for more details .
Start Pinot Broker
Start Pinot Controller
Start Pinot Using Config Files
Often times we need to customized the setup of Pinot components. Hence user can compile a config file and use it to start Pinot components.
Below are the examples config files and sample command to start Pinot.
Pinot Controller
Below is a sample pinot-controller.conf used in HelmChart setup.
In order to run Pinot Controller, the command is:
Configure Controller
Below are some configurations you can set in Pinot Controller. You can head over to Controller for complete list of available configs.
controller.helix.cluster.name
Pinot Cluster name
PinotCluster
controller.host
Pinot Controller Host
Required if config pinot.set.instance.id.to.hostname is false.
pinot.set.instance.id.to.hostname
When enabled, use server hostname to infer controller.host
false
controller.port
Pinot Controller Port
9000
controller.vip.host
The VIP hostname used to set the download URL for segments
${controller.host}
controller.vip.port
The VIP port used to set the download URL for segments
${controller.port}
controller.data.dir
Directory to host segment data
${java.io.tmpdir}/PinotController
controller.zk.str
Zookeeper URL
localhost:2181
cluster.tenant.isolation.enable
Enable Tenant Isolation, default is single tenant cluster
true
Pinot Broker
Below is a sample pinot-broker.conf used in HelmChart setup.
In order to run Pinot Broker, the command is:
Configure Broker
Below are some configurations you can set in Pinot Broker. You can head over to Broker for complete list of available configs.
instanceId
Unique id to register Pinot Broker in the cluster.
BROKER_${BROKER_HOST}_${pinot.broker.client.queryPort}
pinot.set.instance.id.to.hostname
When enabled, use server hostname to set ${BROKER_HOST} in above config, else use IP address.
false
pinot.broker.client.queryPort
Port to query Pinot Broker
8099
pinot.broker.timeoutMs
Timeout for Broker Query in Milliseconds
10000
pinot.broker.enable.query.limit.override
Configuration to enable Query LIMIT Override to protect Pinot Broker and Server from fetch too many records back.
false
pinot.broker.query.response.limit
When config pinot.broker.enable.query.limit.override is enabled, reset limit for selection query if it exceeds this value.
2147483647
pinot.broker.startup.minResourcePercent
Configuration to consider the broker ServiceStatus as being STARTED if the percent of resources (tables) that are ONLINE for this this broker has crossed the threshold percentage of the total number of tables that it is expected to serve
100.0
Pinot Server
Below is a sample pinot-server.conf used in HelmChart setup.
In order to run Pinot Server, the command is:
Configure Server
Below are some outstanding configurations you can set in Pinot Server. You can head over to Server for complete list of available configs.
instanceId
Unique id to register Pinot Server in the cluster.
Server_${SERVER_HOST}_${pinot.server.netty.port}
pinot.set.instance.id.to.hostname
When enabled, use server hostname to set ${SERVER_HOST} in above config, else use IP address.
false
pinot.server.netty.port
Port to query Pinot Server
8098
pinot.server.adminapi.port
Port for Pinot Server Admin UI
8097
pinot.server.instance.dataDir
Directory to hold all the data
${java.io.tmpDir}/PinotServer/index
pinot.server.instance.segmentTarDir
Directory to hold temporary segments downloaded from Controller or Deep Store
${java.io.tmpDir}/PinotServer/segmentTar
pinot.server.query.executor.timeout
Timeout for Server to process Query in Milliseconds
15000
Create and Configure table
A TABLE in regular database world is represented as <TABLE>_OFFLINE and/or <TABLE>_REALTIME in Pinot depending on the ingestion mode (batch, real-time, hybrid)
See examples for all possible batch/streaming tables.
Batch Table Creation
See Batch Tables for table configuration details and how to customize it.
Sample Console Output
Automatically add an inverted index to your batch table
By default, the inverted index type is the only type of index that isn't created automatically during segment generation. Instead, they are generated when the segments are loaded on the server. But, waiting to build indexes until load time increases the startup time and takes up resources with every new segment push, which increases the time for other operations such as rebalance.
To automatically create an inverted index during segment generation, add an entry to your table index config in the table configuration file.
This setting works with batch (offline) tables.
When set to true, Pinot creates an inverted index for the columns that you specify in the invertedIndexColumns list in the table configuration.
This setting is false by default.
Set createInvertedIndexDuringSegmentGeneration to true in your table config, as follows:
When you update this setting in your table configuration, you must reload the table segment to apply the inverted index to all existing segments.
Streaming Table Creation
See Streaming Tables for table configuration details and how to customize it.
Start Kafka
Create a Kafka Topic
Create a Streaming table
Sample output
Start Kafka-Zookeeper
Start Kafka
Create stream table
Use sortedColumn with streaming tables
sortedColumn with streaming tablesFor streaming tables, you can use a sorted index with sortedColumn to sort data when generating segments as the segment is created. See Real-time tables for more information.
A sorted forward index can be used as an inverted index with better performance, but with the limitation that the search is only applied to one column per table. See Sorted inverted index to learn more.
Load Data
Now that the table is configured, let's load some data. Data can be loaded in batch mode or streaming mode. See ingestion overview page for details. Loading data involves generating pinot segments from raw data and pushing them to the pinot cluster.
Load Data in Batch
User can always generate and push segments to Pinot via standalone scripts or using frameworks such as Hadoop or Spark. See this page for more details on setting up Data Ingestion Jobs.
Below example goes with the standalone mode.
Sample Console Output
JobSpec yaml file has all the information regarding data format, input data location and pinot cluster coordinates. Note that this assumes that the controller is RUNNING to fetch the table config and schema. If not, you will have to configure the spec to point at their location. See Pinot Ingestion Job for more details.
Load Data in Streaming
Kafka
Run below command to stream JSON data into Kafka topic: flights-realtime
Run below command to stream JSON data into Kafka topic: flights-realtime
Was this helpful?