Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
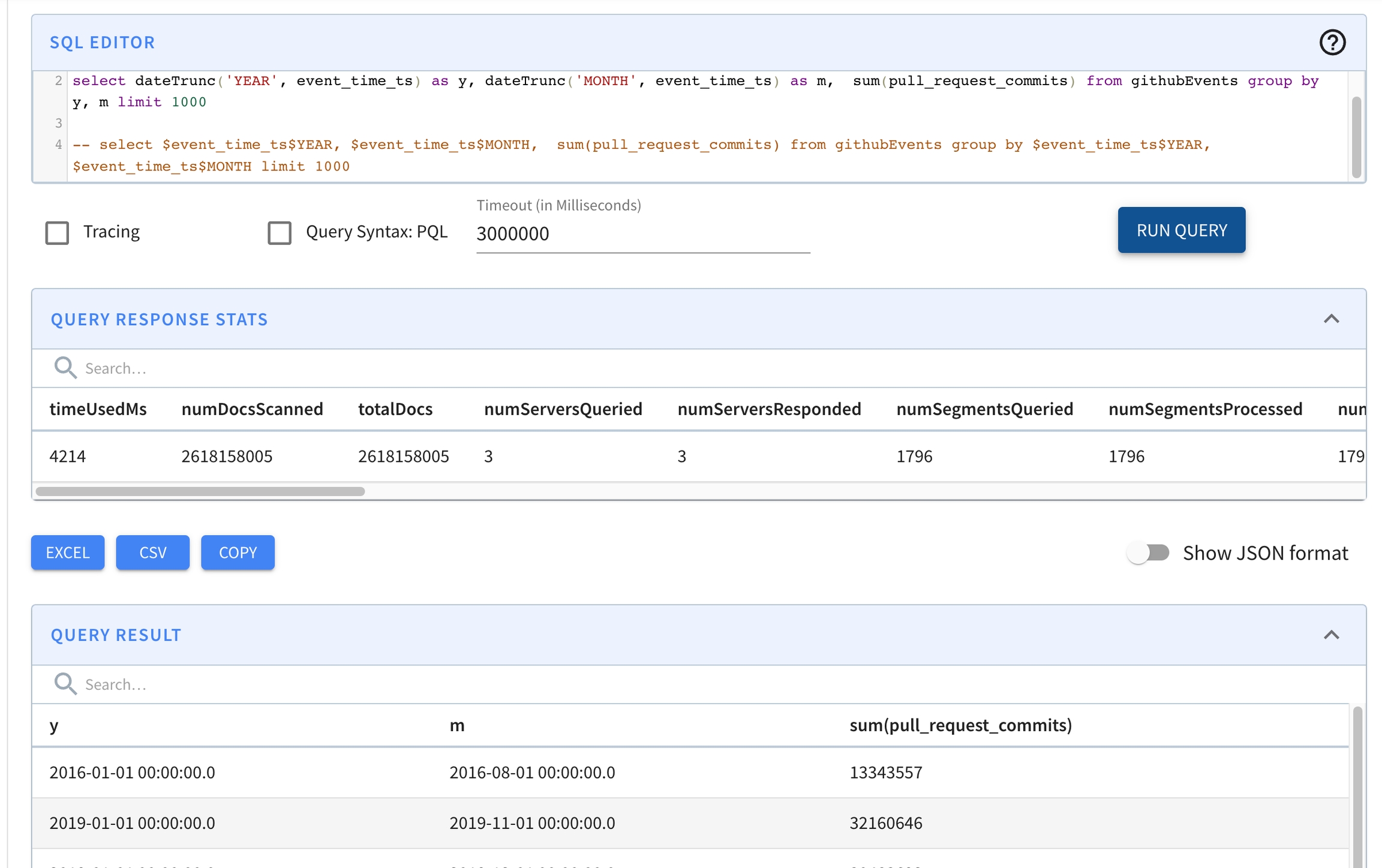
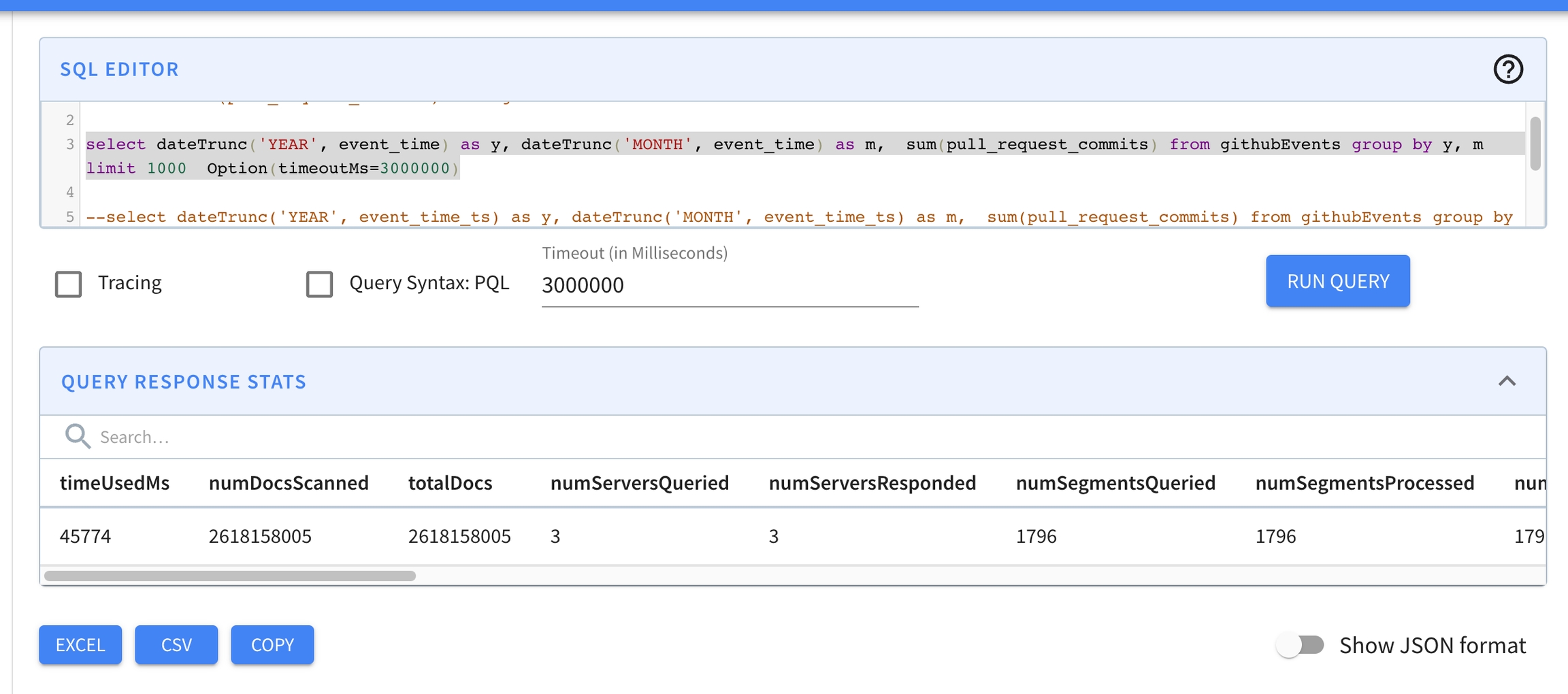
Apache Pinot, a real-time distributed OLAP datastore, purpose-built for low-latency high throughput analytics, perfect for user-facing analytical workloads.
SELECT sum(clicks), sum(impressions) FROM AdAnalyticsTable
WHERE
((daysSinceEpoch >= 17849 AND daysSinceEpoch <= 17856)) AND
accountId IN (123456789)
GROUP BY
daysSinceEpoch TOP 100This page covers everything you need to know about how queries are computed in Pinot's distributed systems architecture.
//This is an example ZNode config for EXTERNAL VIEW in Helix
{
"id" : "baseballStats_OFFLINE",
"simpleFields" : {
...
},
"mapFields" : {
"baseballStats_OFFLINE_0" : {
"Server_10.1.10.82_7000" : "ONLINE"
}
},
...
}// Query: select count(*) from baseballStats limit 10
// RESPONSE
// ========
{
"resultTable": {
"dataSchema": {
"columnDataTypes": ["LONG"],
"columnNames": ["count(*)"]
},
"rows": [
[97889]
]
},
"exceptions": [],
"numServersQueried": 1,
"numServersResponded": 1,
"numSegmentsQueried": 1,
"numSegmentsProcessed": 1,
"numSegmentsMatched": 1,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 97889,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 0,
"numGroupsLimitReached": false,
"totalDocs": 97889,
"timeUsedMs": 5,
"segmentStatistics": [],
"traceInfo": {},
"minConsumingFreshnessTimeMs": 0
}This page contains multiple quick start guides for deploying Pinot to a public cloud provider.
This page has a collection of frequently asked questions with answers from the community.
Here you will find a collection of ready-made sample applications and examples for real-world data
lookUp('dimTableName', 'dimColToLookUp', 'dimJoinKey1', factJoinKeyVal1, 'dimJoinKey2', factJoinKeyVal2 ... )

This section contains quick start guides to help you get up and running with Pinot.
This guide will show you to run a Pinot Cluster using Docker.
Pinot quick start in Kubernetes
This starter guide provides a quick start for running Pinot on Microsoft Azure
This starter provides a quick start for running Pinot on Google Cloud Platform (GCP)
This guide provides a quick start for running Pinot on Amazon Web Services (AWS).
max(OfflineTime) to determine the time-boundary, and instead using an offset?{'errorCode': 410, 'message': 'BrokerResourceMissingError'}# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'spark'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner'
#segmentMetadataPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentMetadataPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: your/local/dir/stagingDimension tables in Apache Pinot.
{
"OFFLINE": {
"tableName": "dimBaseballTeams_OFFLINE",
"tableType": "OFFLINE",
"segmentsConfig": {
"schemaName": "dimBaseballTeams",
"segmentPushType": "REFRESH"
},
"metadata": {},
"quota": {
"storage": "200M"
},
"isDimTable": true
}
}{
"dimensionFieldSpecs": [
{
"dataType": "STRING",
"name": "teamID"
},
{
"dataType": "STRING",
"name": "teamName"
}
],
"schemaName": "dimBaseballTeams",
"primaryKeyColumns": ["teamID"]
}This guide shows you how to ingest a stream of records from an Apache Kafka topic into a Pinot table.
{
"tableName": "kinesisTable",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kinesis",
"stream.kinesis.topic.name": "<your kinesis stream name>",
"region": "<your region>",
"accessKey": "<your access key>",
"secretKey": "<your secret key>",
"shardIteratorType": "AFTER_SEQUENCE_NUMBER",
"stream.kinesis.consumer.type": "lowlevel",
"stream.kinesis.fetch.timeout.millis": "30000",
"stream.kinesis.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kinesis.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kinesis.KinesisConsumerFactory",
"realtime.segment.flush.threshold.rows": "1000000",
"realtime.segment.flush.threshold.time": "6h"
}
},
"metadata": {
"customConfigs": {}
}
}Upsert support in Apache Pinot.
This section contains a collection of guides that will show you how to import data from a Pinot supported input format.
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
key1 : 'value1'
key2 : 'value2'SELECT COUNT(*)
FROM baseballStats
WHERE playerID = 12345This page talks about support for text search functionality in Pinot.
SELECT COUNT(*)
FROM Foo
WHERE STRING_COL = 'ABCDCD'
AND INT_COL > 2000The following summarizes Pinot's releases, from the latest one to the earliest one.
Steps for setting up a Pinot cluster and a realtime table which consumes from the GitHub events stream.
Learn how to query Apache Pinot using SQL or explore data using the web-based Pinot query console.
Learn how to query Pinot using SQL
Learn how to write fast queries for looking up ids in a list of values.
This document contains the list of all the transformation functions supported by Pinot SQL.
Table myTable:
id INTEGER
jsoncolumn JSON
Table data:
101,{"name":{"first":"daffy"\,"last":"duck"}\,"score":101\,"data":["a"\,"b"\,"c"\,"d"]}
102,{"name":{"first":"donald"\,"last":"duck"}\,"score":102\,"data":["a"\,"b"\,"e"\,"f"]}
103,{"name":{"first":"mickey"\,"last":"mouse"}\,"score":103\,"data":["a"\,"b"\,"g"\,"h"]}
104,{"name":{"first":"minnie"\,"last":"mouse"}\,"score":104\,"data":["a"\,"b"\,"i"\,"j"]}
105,{"name":{"first":"goofy"\,"last":"dwag"}\,"score":104\,"data":["a"\,"b"\,"i"\,"j"]}
106,{"person":{"name":"daffy duck"\,"companies":[{"name":"n1"\,"title":"t1"}\,{"name":"n2"\,"title":"t2"}]}}
107,{"person":{"name":"scrooge mcduck"\,"companies":[{"name":"n1"\,"title":"t1"}\,{"name":"n2"\,"title":"t2"}]}}SELECT id, jsoncolumn
FROM myTableEXPLAIN PLAN FOR SELECT playerID, playerName FROM baseballStats
+---------------------------------------------|------------|---------|
| Operator | Operator_Id|Parent_Id|
+---------------------------------------------|------------|---------|
|BROKER_REDUCE(limit:10) | 0 | -1 |
|COMBINE_SELECT | 1 | 0 |
|SELECT(selectList:playerID, playerName) | 2 | 1 |
|TRANSFORM_PASSTHROUGH(playerID, playerName) | 3 | 2 |
|PROJECT(playerName, playerID) | 4 | 3 |
|FILTER_MATCH_ENTIRE_SEGMENT(docs:97889) | 5 | 4 |
+---------------------------------------------|------------|---------|$ curl -H "Content-Type: application/json" -X
$ curl -X POST \
-d '{"sql":"SELECT SUM(moo), MAX(bar), COUNT(*) FROM myTable"}' \
localhost:8099/query/sql -H "Content-Type: application/json"
{
"exceptions": [],
"minConsumingFreshnessTimeMs": 0,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 6,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 12,
"numGroupsLimitReached": false,
"numSegmentsMatched": 2,
"numSegmentsProcessed": 2,
"numSegmentsQueried": 2,
"numServersQueried": 1,
"numServersResponded": 1,
"resultTable": {
"dataSchema": {
"columnDataTypes": [
"DOUBLE",
"DOUBLE",
"LONG"
],
"columnNames": [
"sum(moo)",
"max(bar)",
"count(*)"
]
},
"rows": [
[
62335,
2019.0,
6
]
]
},
"segmentStatistics": [],
"timeUsedMs": 87,
"totalDocs": 6,
"traceInfo": {}
}$ curl -X POST \
-d '{"sql":"SELECT SUM(moo), MAX(bar) FROM myTable GROUP BY foo ORDER BY foo"}' \
localhost:8099/query/sql -H "Content-Type: application/json"
{
"exceptions": [],
"minConsumingFreshnessTimeMs": 0,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 6,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 18,
"numGroupsLimitReached": false,
"numSegmentsMatched": 2,
"numSegmentsProcessed": 2,
"numSegmentsQueried": 2,
"numServersQueried": 1,
"numServersResponded": 1,
"resultTable": {
"dataSchema": {
"columnDataTypes": [
"STRING",
"DOUBLE",
"DOUBLE"
],
"columnNames": [
"foo",
"sum(moo)",
"max(bar)"
]
},
"rows": [
[
"abc",
560.0,
2008.0
],
[
"pqr",
21760.0,
2010.0
],
[
"xyz",
40015.0,
2019.0
]
]
},
"segmentStatistics": [],
"timeUsedMs": 15,
"totalDocs": 6,
"traceInfo": {}
}Pinot Client for Golang
bin/quick-start-batch.shgit clone [email protected]:xiangfu0/pinot-client-go.git
cd pinot-client-go
mergeType



jsonExtractScalarlocalhost:9092bin/pinot-admin.sh StartKafka -zkAddress=localhost:2123/kafka -port 9876docker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-quickstart:2123/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper pinot-quickstart:2123/kafka \
--partitions=1 --replication-factor=1 \
--create --topic transcript-topicbin/kafka-topics.sh --create --bootstrap-server localhost:9876 --replication-factor 1 --partitions 1 --topic transcript-topichadoop.kerberos.principleconfigClassName - name of the class that implements the RecordReaderConfig interface. This class is used the parse the values mentioned in configs{
"tableIndexConfig": {
"bloomFilterColumns": [
"playerID",
...
],
...
},
...
}arg2count(*)minmaxTRANSFORM_PASSTHROUGHTRANSFORM_PASSTHROUGHFILTER_SORTED_INDEXFILTER_RANGE_INDEXFILTER_INVERTED_INDEXFILTER_JSON_INDEXcurl -X GET "http://localhost:9000/periodictask/names" -H "accept: application/json"
[
"RetentionManager",
"OfflineSegmentIntervalChecker",
"RealtimeSegmentValidationManager",
"BrokerResourceValidationManager",
"SegmentStatusChecker",
"SegmentRelocator",
"MinionInstancesCleanupTask",
"TaskMetricsEmitter"
]curl -X GET "http://localhost:9000/periodictask/run?taskname=SegmentStatusChecker&tableName=jsontypetable&type=OFFLINE" -H "accept: application/json"
{
"Log Request Id": "api-09630c07",
"Controllers notified": true
}docker run \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartController \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
-controllerPort 9000executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'examples/batch/baseballStats/rawdata'
includeFileNamePattern: 'glob:**/*.csv'
excludeFileNamePattern: 'glob:**/*.tmp'
outputDirURI: 'examples/batch/baseballStats/segments'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
tableSpec:
tableName: 'baseballStats'
schemaURI: 'http://localhost:9000/tables/baseballStats/schema'
tableConfigURI: 'http://localhost:9000/tables/baseballStats'
segmentNameGeneratorSpec:
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yamlSegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**/*.avro
inputDirURI: examples/batch/airlineStats/rawdata
jobType: SegmentCreationAndTarPush
outputDirURI: examples/batch/airlineStats/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://pinot-controller:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
pushJobSpec: {pushAttempts: 2, pushParallelism: 1, pushRetryIntervalMillis: 1000,
segmentUriPrefix: null, segmentUriSuffix: null}
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.avro.AvroRecordReader,
configClassName: null, configs: null, dataFormat: avro}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://pinot-controller:9000/tables/airlineStats/schema',
tableConfigURI: 'http://pinot-controller:9000/tables/airlineStats', tableName: airlineStats}
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Finished building StatsCollector!
Collected stats for 403 documents
Created dictionary for INT column: FlightNum with cardinality: 386, range: 14 to 7389
Using fixed bytes value dictionary for column: Origin, size: 294
Created dictionary for STRING column: Origin with cardinality: 98, max length in bytes: 3, range: ABQ to VPS
Created dictionary for INT column: Quarter with cardinality: 1, range: 1 to 1
Created dictionary for INT column: LateAircraftDelay with cardinality: 50, range: -2147483648 to 303
......
......
Pushing segment: airlineStats_OFFLINE_16085_16085_29 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16085_16085_29 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16085_16085_29 of table: airlineStats"}
Pushing segment: airlineStats_OFFLINE_16084_16084_30 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16084_16084_30 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16084_16084_30 of table: airlineStats"}bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile examples/batch/airlineStats/ingestionJobSpec.yamlinputDirURI: 'examples/batch/airlineStats/rawdata/${year}/${month}/${day}'
outputDirURI: 'examples/batch/airlineStats/segments/${year}/${month}/${day}'docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yaml
-values year=2014 month=01 day=03docker run \
--network pinot-demo \
--name=loading-airlineStats-data-to-kafka \
${PINOT_IMAGE} StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList kafka:9092 -zkAddress pinot-zookeeper:2181/kafkabin/pinot-admin.sh StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList localhost:19092 -zkAddress localhost:2191/kafkaFailed to start a Pinot [SERVER]
java.lang.RuntimeException: java.net.BindException: Address already in use
at org.apache.pinot.core.transport.QueryServer.start(QueryServer.java:103) ~[pinot-all-0.9.0-jar-with-dependencies.jar:0.9.0-cf8b84e8b0d6ab62374048de586ce7da21132906]
at org.apache.pinot.server.starter.ServerInstance.start(ServerInstance.java:158) ~[pinot-all-0.9.0-jar-with-dependencies.jar:0.9.0-cf8b84e8b0d6ab62374048de586ce7da21132906]
at org.apache.helix.manager.zk.ParticipantManager.handleNewSession(ParticipantManager.java:110) ~[pinot-all-0.9.0-jar-with-dependencies.jar:0.9.0-cf8b84e8b0d6ab62374048de586ce7da2113docker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type batch./bin/pinot-admin.sh QuickStart -type batchdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type batch_json_index./bin/pinot-admin.sh QuickStart -type batch_json_indexdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type batch_json_index./bin/pinot-admin.sh QuickStart -type batch_json_indexdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type stream./bin/pinot-admin.sh QuickStart -type streamdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type stream_json_index./bin/pinot-admin.sh QuickStart -type stream_json_indexdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type realtime_minion./bin/pinot-admin.sh QuickStart -type realtime_miniondocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type stream_complex_type./bin/pinot-admin.sh QuickStart -type stream_complex_typedocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type upsert./bin/pinot-admin.sh QuickStart -type upsertdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type upsert_json_index./bin/pinot-admin.sh QuickStart -type upsert_json_indexdocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type hybrid./bin/pinot-admin.sh QuickStart -type hybriddocker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type join./bin/pinot-admin.sh QuickStart -type joinbrew install kubernetes-clikubectl versionbrew install kubernetes-helmhelm versionbrew update && brew install azure-cliaz loginAKS_RESOURCE_GROUP=pinot-demo
AKS_RESOURCE_GROUP_LOCATION=eastus
az group create --name ${AKS_RESOURCE_GROUP} \
--location ${AKS_RESOURCE_GROUP_LOCATION}AKS_RESOURCE_GROUP=pinot-demo
AKS_CLUSTER_NAME=pinot-quickstart
az aks create --resource-group ${AKS_RESOURCE_GROUP} \
--name ${AKS_CLUSTER_NAME} \
--node-count 3AKS_RESOURCE_GROUP=pinot-demo
AKS_CLUSTER_NAME=pinot-quickstart
az aks get-credentials --resource-group ${AKS_RESOURCE_GROUP} \
--name ${AKS_CLUSTER_NAME}kubectl get nodesAKS_RESOURCE_GROUP=pinot-demo
AKS_CLUSTER_NAME=pinot-quickstart
az aks delete --resource-group ${AKS_RESOURCE_GROUP} \
--name ${AKS_CLUSTER_NAME}brew install kubernetes-clikubectl versionbrew install kubernetes-helmhelm versioncurl https://sdk.cloud.google.com | bashexec -l $SHELLgcloud initGCLOUD_PROJECT=[your gcloud project name]
GCLOUD_ZONE=us-west1-b
GCLOUD_CLUSTER=pinot-quickstart
GCLOUD_MACHINE_TYPE=n1-standard-2
GCLOUD_NUM_NODES=3
gcloud container clusters create ${GCLOUD_CLUSTER} \
--num-nodes=${GCLOUD_NUM_NODES} \
--machine-type=${GCLOUD_MACHINE_TYPE} \
--zone=${GCLOUD_ZONE} \
--project=${GCLOUD_PROJECT}gcloud compute instances listGCLOUD_PROJECT=[your gcloud project name]
GCLOUD_ZONE=us-west1-b
GCLOUD_CLUSTER=pinot-quickstart
gcloud container clusters get-credentials ${GCLOUD_CLUSTER} --zone ${GCLOUD_ZONE} --project ${GCLOUD_PROJECT}kubectl get nodesGCLOUD_ZONE=us-west1-b
gcloud container clusters delete pinot-quickstart --zone=${GCLOUD_ZONE}brew install kubernetes-clikubectl versionbrew install kubernetes-helmhelm versioncurl "https://d1vvhvl2y92vvt.cloudfront.net/awscli-exe-macos.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/installbrew tap weaveworks/tap
brew install weaveworks/tap/eksctlaws configureEKS_CLUSTER_NAME=pinot-quickstart
eksctl create cluster \
--name ${EKS_CLUSTER_NAME} \
--version 1.16 \
--region us-west-2 \
--nodegroup-name standard-workers \
--node-type t3.xlarge \
--nodes 1 \
--nodes-min 1 \
--nodes-max 1EKS_CLUSTER_NAME=pinot-quickstart
aws eks describe-cluster --name ${EKS_CLUSTER_NAME} --region us-west-2EKS_CLUSTER_NAME=pinot-quickstart
aws eks update-kubeconfig --name ${EKS_CLUSTER_NAME}kubectl get nodesEKS_CLUSTER_NAME=pinot-quickstart
aws eks delete-cluster --name ${EKS_CLUSTER_NAME}pinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.server.storage.factory.hdfs.hadoop.conf.path=/path/to/hadoop/conf/directory/
pinot.server.segment.fetcher.protocols=file,http,hdfs
pinot.server.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>
pinot.set.instance.id.to.hostname=true
pinot.server.instance.dataDir=/path/in/local/filesystem/for/pinot/data/server/index
pinot.server.instance.segmentTarDir=/path/in/local/filesystem/for/pinot/data/server/segment
pinot.server.grpc.enable=true
pinot.server.grpc.port=8090export HADOOP_HOME=/path/to/hadoop/home
export HADOOP_VERSION=2.7.1
export HADOOP_GUAVA_VERSION=11.0.2
export HADOOP_GSON_VERSION=2.2.4
export GC_LOG_LOCATION=/path/to/gc/log/file
export PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin/
export SERVER_CONF_DIR=/path/to/pinot/conf/dir/
export ZOOKEEPER_ADDRESS=localhost:2181
export CLASSPATH_PREFIX="${HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-annotations-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/hadoop-common-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/guava-${HADOOP_GUAVA_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/gson-${HADOOP_GSON_VERSION}.jar"
export JAVA_OPTS="-Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:${GC_LOG_LOCATION}/gc-pinot-server.log"
${PINOT_DISTRIBUTION_DIR}/bin/start-server.sh -zkAddress ${ZOOKEEPER_ADDRESS} -configFileName ${SERVER_CONF_DIR}/server.confcontroller.data.dir=hdfs://path/in/hdfs/for/controller/segment
controller.local.temp.dir=/tmp/pinot/
controller.zk.str=<ZOOKEEPER_HOST:ZOOKEEPER_PORT>
controller.enable.split.commit=true
controller.access.protocols.http.port=9000
controller.helix.cluster.name=PinotCluster
pinot.controller.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.controller.storage.factory.hdfs.hadoop.conf.path=/path/to/hadoop/conf/directory/
pinot.controller.segment.fetcher.protocols=file,http,hdfs
pinot.controller.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>
controller.vip.port=9000
controller.port=9000
pinot.set.instance.id.to.hostname=true
pinot.server.grpc.enable=trueexport HADOOP_HOME=/path/to/hadoop/home
export HADOOP_VERSION=2.7.1
export HADOOP_GUAVA_VERSION=11.0.2
export HADOOP_GSON_VERSION=2.2.4
export GC_LOG_LOCATION=/path/to/gc/log/file
export PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin/
export SERVER_CONF_DIR=/path/to/pinot/conf/dir/
export ZOOKEEPER_ADDRESS=localhost:2181
export CLASSPATH_PREFIX="${HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-annotations-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/hadoop-common-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/guava-${HADOOP_GUAVA_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/gson-${HADOOP_GSON_VERSION}.jar"
export JAVA_OPTS="-Xms8G -Xmx12G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:${GC_LOG_LOCATION}/gc-pinot-controller.log"
${PINOT_DISTRIBUTION_DIR}/bin/start-controller.sh -configFileName ${SERVER_CONF_DIR}/controller.confpinot.set.instance.id.to.hostname=true
pinot.server.grpc.enable=trueexport HADOOP_HOME=/path/to/hadoop/home
export HADOOP_VERSION=2.7.1
export HADOOP_GUAVA_VERSION=11.0.2
export HADOOP_GSON_VERSION=2.2.4
export GC_LOG_LOCATION=/path/to/gc/log/file
export PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin/
export SERVER_CONF_DIR=/path/to/pinot/conf/dir/
export ZOOKEEPER_ADDRESS=localhost:2181
export CLASSPATH_PREFIX="${HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-annotations-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/hadoop-common-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/guava-${HADOOP_GUAVA_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/gson-${HADOOP_GSON_VERSION}.jar"
export JAVA_OPTS="-Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:${GC_LOG_LOCATION}/gc-pinot-broker.log"
${PINOT_DISTRIBUTION_DIR}/bin/start-broker.sh -zkAddress ${ZOOKEEPER_ADDRESS} -configFileName ${SERVER_CONF_DIR}/broker.conf"tableIndexConfig": {
..
"segmentPartitionConfig": {
"columnPartitionMap": {
"column_foo": {
"functionName": "Murmur",
"numPartitions": 12 // same as number of kafka partitions
}
}
}"routing": {
"segmentPrunerTypes": ["partition"]
} {
"dataType": "STRING",
"maxLength": 1000,
"name": "textDim1"
},{
"<segment-name>": {
"segmentName": "<segment-name>",
"indexes": {
"<columnName>": {
"bloom-filter": "NO",
"dictionary": "YES",
"forward-index": "YES",
"inverted-index": "YES",
"null-value-vector-reader": "NO",
"range-index": "NO",
"json-index": "NO"
}
}
}
}select "timestamp" from myTableSELECT COUNT(*) from myTable WHERE column = 'foo'SELECT count(colA) as aliasA, colA from tableA GROUP BY colA ORDER BY aliasASELECT count(colA) as sumA, colA from tableA GROUP BY colA ORDER BY count(colA)SELECT COUNT(*) from myTable option(timeoutMs=20000){
"tableName": "pinotTable",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": "3",
...
}
..{
"tableName": "pinotTable",
"tableType": "REALTIME",
"segmentsConfig": {
"replicasPerPartition": "3",
...
}
..curl -X POST "{host}/segments/{tableNameWithType}/{segmentName}/reset"cluster.tenant.isolation.enable=falsecurl -X POST "http://localhost:9000/tenants"
-H "accept: application/json"
-H "Content-Type: application/json"
-d "{\"tenantRole\":\"BROKER\",\"tenantName\":\"foo\",\"numberOfInstances\":1}"{
"tableName": "pinotTable",
"tableType": "REALTIME",
"routing": {
"instanceSelectorType": "replicaGroup"
}
..
}studentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "transcript",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": 1,
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": 365
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
}
},
"metadata": {}
}bin/pinot-admin.sh AddTable \\
-tableConfigFile /path/to/table-config.json \\
-schemaFile /path/to/table-schema.json -execcurl -X POST -F [email protected] \
-H "Content-Type: multipart/form-data" \
"http://localhost:9000/ingestFromFile?tableNameWithType=foo_OFFLINE&
batchConfigMapStr={"inputFormat":"json"}"curl -X POST -F [email protected] \
-H "Content-Type: multipart/form-data" \
"http://localhost:9000/ingestFromFile?tableNameWithType=foo_OFFLINE&
batchConfigMapStr={
"inputFormat":"csv",
"recordReader.prop.delimiter":"|"
}"curl -X POST "http://localhost:9000/ingestFromURI?tableNameWithType=foo_OFFLINE
&batchConfigMapStr={
"inputFormat":"json",
"input.fs.className":"org.apache.pinot.plugin.filesystem.S3PinotFS",
"input.fs.prop.region":"us-central",
"input.fs.prop.accessKey":"foo",
"input.fs.prop.secretKey":"bar"
}
&sourceURIStr=s3://test.bucket/path/to/json/data/data.json"executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentMetadataPushJobRunner'
# Recommended to set jobType to SegmentCreationAndMetadataPush for production environment where Pinot Deep Store is configured
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushAttempts: 2
pushRetryIntervalMillis: 1000bin/pinot-admin.sh LaunchDataIngestionJob \\
-jobSpecFile /tmp/pinot-quick-start/batch-job-spec.yamlspark.driver.extraClassPath =>
pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:pinot-all-${PINOT_VERSION}-jar-with-dependencies.jarspark.driver.extraJavaOptions =>
-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/pluginsexport PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin
spark-submit //
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand //
--master local --deploy-mode client //
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins" //
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark/pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
-conf "spark.executor.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark/pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar -jobSpecFile /path/to/spark_job_spec.yaml# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'hadoop'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentUriPushJobRunner'
# segmentMetadataPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentMetadataPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: your/local/dir/stagingexport PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=${PINOT_ROOT_DIR}/build/
export HADOOP_CLIENT_OPTS="-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml"
hadoop jar \\
${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \\
org.apache.pinot.tools.admin.PinotAdministrator \\
LaunchDataIngestionJob \\
-jobSpecFile ${PINOT_DISTRIBUTION_DIR}/examples/batch/airlineStats/hadoopIngestionJobSpec.yamlenable.preprocessing = true
preprocess.path.to.output = <output_path>{
"OFFLINE": {
"metadata": {
"customConfigs": {
“preprocessing.operations”: “resize, partition, sort”, // To enable the following preprocessing operations
"preprocessing.max.num.records.per.file": "100", // To enable resizing
"preprocessing.num.reducers": "3" // To enable resizing
}
},
...
"tableIndexConfig": {
"aggregateMetrics": false,
"autoGeneratedInvertedIndex": false,
"bloomFilterColumns": [],
"createInvertedIndexDuringSegmentGeneration": false,
"invertedIndexColumns": [],
"loadMode": "MMAP",
"nullHandlingEnabled": false,
"segmentPartitionConfig": { // To enable partitioning
"columnPartitionMap": {
"item": {
"functionName": "murmur",
"numPartitions": 4
}
}
},
"sortedColumn": [ // To enable sorting
"actorId"
],
"streamConfigs": {}
},
"tableName": "tableName_OFFLINE",
"tableType": "OFFLINE",
"tenants": {
...
}
}
} {
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "localhost:9876",
"realtime.segment.flush.threshold.time": "3600000",
"realtime.segment.flush.threshold.rows": "50000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}docker run \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost pinot-quickstart \
-controllerPort 9000 \
-execbin/pinot-admin.sh AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-exec{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestamp":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestamp":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestamp":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestamp":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestamp":1572854400000}bin/kafka-console-producer.sh \
--broker-list localhost:9876 \
--topic transcript-topic < transcript.jsonSELECT * FROM transcript {
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "LowLevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:9876",
"schema.registry.url": "",
"security.protocol": "SSL",
"ssl.truststore.location": "",
"ssl.keystore.location": "",
"ssl.truststore.password": "",
"ssl.keystore.password": "",
"ssl.key.password": "",
"stream.kafka.decoder.prop.schema.registry.rest.url": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.location": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.location": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.type": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.type": "",
"stream.kafka.decoder.prop.schema.registry.ssl.key.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.protocol": "",
}
},
"metadata": {
"customConfigs": {}
}
} {
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "LowLevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:9876",
"stream.kafka.isolation.level": "read_committed"
}
},
"metadata": {
"customConfigs": {}
}
}"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "mytopic",
"stream.kafka.consumer.prop.auto.offset.reset": "largest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka-broker-host:9092",
"stream.kafka.schema.registry.url": "https://xxx",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.decoder.prop.schema.registry.rest.url": "https://xxx",
"stream.kafka.decoder.prop.basic.auth.credentials.source": "USER_INFO",
"stream.kafka.decoder.prop.schema.registry.basic.auth.user.info": "schema_registry_username:schema_registry_password",
"sasl.mechanism": "PLAIN" ,
"security.protocol": "SASL_SSL" ,
"sasl.jaas.config":"org.apache.kafka.common.security.scram.ScramLoginModule required username=\"kafkausername\" password=\"kafkapassword\";",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.autotune.initialRows": "3000000",
"realtime.segment.flush.threshold.segment.size": "500M"
},{
"tableName": "pulsarTable",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "pulsar",
"stream.pulsar.topic.name": "<your pulsar topic name>",
"stream.pulsar.bootstrap.servers": "pulsar://localhost:6650,pulsar://localhost:6651",
"stream.pulsar.consumer.prop.auto.offset.reset" : "smallest",
"stream.pulsar.consumer.type": "lowlevel",
"stream.pulsar.fetch.timeout.millis": "30000",
"stream.pulsar.decoder.class.name": "org.apache.pinot.plugin.inputformat.json.JSONMessageDecoder",
"stream.pulsar.consumer.factory.class.name": "org.apache.pinot.plugin.stream.pulsar.PulsarConsumerFactory",
"realtime.segment.flush.threshold.rows": "1000000",
"realtime.segment.flush.threshold.time": "6h"
}
},
"metadata": {
"customConfigs": {}
}
}"stream.pulsar.authenticationToken":"your-auth-token""stream.pulsar.tlsTrustCertsFilePath": "/path/to/ca.cert.pem"-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-plugin-to-include-1,pinot-plugin-to-include-2#CONTROLLER
pinot.controller.storage.factory.class.[scheme]=className of the pinot file systems
pinot.controller.segment.fetcher.protocols=file,http,[scheme]
pinot.controller.segment.fetcher.[scheme].class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher#SERVER
pinot.server.storage.factory.class.[scheme]=className of the pinotfile systems
pinot.server.segment.fetcher.protocols=file,http,[scheme]
pinot.server.segment.fetcher.[scheme].class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinotFSSpecs
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFSpinot.controller.storage.factory.s3.region=ap-southeast-1executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 's3://pinot-bucket/pinot-ingestion/batch-input/'
outputDirURI: 's3://pinot-bucket/pinot-ingestion/batch-output/'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'ap-southeast-1'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=s3://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=ap-southeast-1
pinot.controller.segment.fetcher.protocols=file,http,s3
pinot.controller.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.server.storage.factory.s3.region=ap-southeast-1
pinot.server.segment.fetcher.protocols=file,http,s3
pinot.server.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.minion.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.minion.storage.factory.s3.region=ap-southeast-1
pinot.minion.segment.fetcher.protocols=file,http,s3
pinot.minion.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.controller.storage.factory.class.adl2.accountName=test-userexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'abfs://path/to/input/directory/'
outputDirURI: 'abfs://path/to/output/directory/'
overwriteOutput: true
pinotFSSpecs:
- scheme: adl2
className: org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
configs:
accountName: 'my-account'
accessKey: 'foo-bar-1234'
fileSystemName: 'fs-name'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=abfs://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
pinot.controller.storage.factory.adl2.accountName=my-account
pinot.controller.storage.factory.adl2.accessKey=foo-bar-1234
pinot.controller.storage.factory.adl2.fileSystemName=fs-name
pinot.controller.segment.fetcher.protocols=file,http,adl2
pinot.controller.segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
pinot.server.storage.factory.adl2.accountName=my-account
pinot.server.storage.factory.adl2.accessKey=foo-bar-1234
pinot.controller.storage.factory.adl2.fileSystemName=fs-name
pinot.server.segment.fetcher.protocols=file,http,adl2
pinot.server.segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherstorage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
storage.factory.adl2.accountName=my-account
storage.factory.adl2.fileSystemName=fs-name
storage.factory.adl2.accessKey=foo-bar-1234
segment.fetcher.protocols=file,http,adl2
segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherexport HADOOP_HOME=/local/hadoop/
export HADOOP_VERSION=2.7.1
export HADOOP_GUAVA_VERSION=11.0.2
export HADOOP_GSON_VERSION=2.2.4
export CLASSPATH_PREFIX="${HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-annotations-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/hadoop-common-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/guava-${HADOOP_GUAVA_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/gson-${HADOOP_GSON_VERSION}.jar"curl -X POST -H "UPLOAD_TYPE:URI" -H "DOWNLOAD_URI:hdfs://nameservice1/hadoop/path/to/segment/file.executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'hdfs:///path/to/input/directory/'
outputDirURI: 'hdfs:///path/to/output/directory/'
includeFileNamePath: 'glob:**/*.csv'
overwriteOutput: true
pinotFSSpecs:
- scheme: hdfs
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
hadoop.conf.path: 'path/to/conf/directory/'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'executionFrameworkSpec:
name: 'hadoop'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentUriPushJobRunner'
extraConfigs:
stagingDir: 'hdfs:///path/to/staging/directory/'
jobType: SegmentCreationAndTarPush
inputDirURI: 'hdfs:///path/to/input/directory/'
outputDirURI: 'hdfs:///path/to/output/directory/'
includeFileNamePath: 'glob:**/*.csv'
overwriteOutput: true
pinotFSSpecs:
- scheme: hdfs
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
hadoop.conf.path: '/etc/hadoop/conf/'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=hdfs://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.controller.storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory/
pinot.controller.segment.fetcher.protocols=file,http,hdfs
pinot.controller.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>pinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.server.storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory/
pinot.server.segment.fetcher.protocols=file,http,hdfs
pinot.server.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory
segment.fetcher.protocols=file,http,hdfs
segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>pinot.controller.storage.factory.class.gs.projectId=test-projectexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'gs://my-bucket/path/to/input/directory/'
outputDirURI: 'gs://my-bucket/path/to/output/directory/'
overwriteOutput: true
pinotFSSpecs:
- scheme: gs
className: org.apache.pinot.plugin.filesystem.GcsPinotFS
configs:
projectId: 'my-project'
gcpKey: 'path-to-gcp json key file'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=gs://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.controller.storage.factory.gs.projectId=my-project
pinot.controller.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.controller.segment.fetcher.protocols=file,http,gs
pinot.controller.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.server.storage.factory.gs.projectId=my-project
pinot.server.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.server.segment.fetcher.protocols=file,http,gs
pinot.server.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.minion.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.minion.storage.factory.gs.projectId=my-project
pinot.minion.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.minion.segment.fetcher.protocols=file,http,gs
pinot.minion.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherdataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
fileFormat: 'default' #should be one of default, rfc4180, excel, tdf, mysql
header: 'columnName seperated by delimiter'
delimiter: ','
multiValueDelimiter: '-'dataFormat: 'avro'
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'dataFormat: 'json'
className: 'org.apache.pinot.plugin.inputformat.json.JSONRecordReader'dataFormat: 'thrift'
className: 'org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader'
configs:
thriftClass: 'ParserClassName'dataFormat: 'parquet'
className: 'org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader'dataFormat: 'parquet'
className: 'org.apache.pinot.plugin.inputformat.parquet.ParquetNativeRecordReader'dataFormat: 'orc'
className: 'org.apache.pinot.plugin.inputformat.orc.ORCRecordReader'dataFormat: 'proto'
className: 'org.apache.pinot.plugin.inputformat.protobuf.ProtoBufRecordReader'
configs:
descriptorFile: 'file:///path/to/sample.desc'protoc --include_imports --descriptor_set_out=/absolute/path/to/output.desc /absolute/path/to/input.proto"tableIndexConfig": {
"invertedIndexColumns": ["foo"],
...
}"tableIndexConfig": {
"invertedIndexColumns": ["foo", "bar"],
...
}curl -X POST \
"http://localhost:9000/segments/myTable/reload" \
-H "accept: application/json"{
"tableIndexConfig": {
"bloomFilterConfigs": {
"playerID": {
"fpp": 0.01,
"maxSizeInBytes": 1000000,
"loadOnHeap": true
},
...
},
...
},
...
}SELECT COUNT(*)
FROM Foo
WHERE TEXT_MATCH (<column_name>, '<search_expression>')109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-
109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
95.29.198.15 - - [12/Dec/2015:18:32:10 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
95.29.198.15 - - [12/Dec/2015:18:32:11 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
109.184.11.34 - - [12/Dec/2015:18:32:56 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
109.184.11.34 - - [12/Dec/2015:18:32:56 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
91.227.29.79 - - [12/Dec/2015:18:33:51 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'GET')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'post AND administrator AND index')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'post AND administrator AND index AND firefox')Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Java, Python, C++, Machine learning, building and deploying large scale production systems, concurrency, multi-threading, CPU processing
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
Amazon EC2, AWS, hadoop, big data, spark, building high performance scalable systems, building and deploying large scale production systems, concurrency, multi-threading, Java, C++, CPU processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Kubernetes, cluster management, operating systems, concurrency, multi-threading, apache airflow, Apache Spark,
Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systems
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND "gpu processing"')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" AND (Java C++)')SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560988800000 AND 1568764800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560988800000 AND 1568764800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1545436800000 AND 1553212800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1537228800000 AND 1537660800000 GROUP BY dimensionCol3 TOP 2500
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1561366800000 AND 1561370399999 AND dimensionCol3 = 2019062409 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1563807600000 AND 1563811199999 AND dimensionCol3 = 2019072215 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1563811200000 AND 1563814799999 AND dimensionCol3 = 2019072216 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1566327600000 AND 1566329400000 AND dimensionCol3 = 2019082019 LIMIT 10000
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560834000000 AND 1560837599999 AND dimensionCol3 = 2019061805 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560870000000 AND 1560871800000 AND dimensionCol3 = 2019061815 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560871800001 AND 1560873599999 AND dimensionCol3 = 2019061815 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560873600000 AND 1560877199999 AND dimensionCol3 = 2019061816 LIMIT 0SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"group by"')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"select count"')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"timestamp between" AND "group by"')"fieldConfigList":[
{
"name":"text_col_1",
"encodingType":"RAW",
"indexType":"TEXT"
},
{
"name":"text_col_2",
"encodingType":"RAW",
"indexType":"TEXT"
}
]"tableIndexConfig": {
"noDictionaryColumns": [
"text_col_1",
"text_col_2"
]}SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...)
SELECT * FROM Foo WHERE TEXT_MATCH(...)SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...) AND some_other_column_1 > 20000
SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...) AND some_other_column_1 > 20000 AND some_other_column_2 < 100000SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(text_col_1, ....) AND TEXT_MATCH(text_col_2, ...)Java, C++, worked on open source projects, coursera machine learning
Machine learning, Tensor flow, Java, Stanford university,
Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Java, Python, C++, Machine learning, building and deploying large scale production systems, concurrency, multi-threading, CPU processing
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
Amazon EC2, AWS, hadoop, big data, spark, building high performance scalable systems, building and deploying large scale production systems, concurrency, multi-threading, Java, C++, CPU processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Kubernetes, cluster management, operating systems, concurrency, multi-threading, apache airflow, Apache Spark,
Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systems
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,
C++, Java, Python, realtime streaming systems, Machine learning, spark, Kubernetes, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distribution
Database engine, OLAP systems, OLTP transaction processing at large scale, concurrency, multi-threading, GO, building large scale systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Distributed systems"')Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distributionDistributed data processing, systems design experienceSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"query processing"')Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distribution"SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, 'Java')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND "Tensor Flow"')Machine learning, Tensor flow, Java, Stanford university,
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND gpu AND python')CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" Java C++')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" AND (Java C++)')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, 'stream*')Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,
C++, Java, Python, realtime streaming systems, Machine learning, spark, Kubernetes, transaction processing, distributed storage, concurrency, multi-threading, apache airflowSELECT SKILLS_COL
FROM MyTable
WHERE text_match(SKILLS_COL, '/.*Exception/')TEXT_MATCH(column, '"machine learning"')TEXT_MATCH(column, '"Java C++"')TEXT_MATCH(column, 'Java AND C++'){
"name": "adam",
"age": 30,
"country": "us",
"addresses":
[
{
"number" : 112,
"street" : "main st",
"country" : "us"
},
{
"number" : 2,
"street" : "second st",
"country" : "us"
},
{
"number" : 3,
"street" : "third st",
"country" : "ca"
}
]
}SELECT *
FROM mytable
WHERE JSON_EXTRACT_SCALAR(person, '$.name', 'STRING') = 'adam'{
"tableIndexConfig": {
"jsonIndexColumns": [
"person",
...
],
...
}
}SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam'' AND "$.addresses[*].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.phone" IS NOT NULL')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].floor" IS NULL')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].street"=''main st'' AND "$.addresses[*].country"=''ca''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].street"=''main st''') AND JSON_MATCH(person, '"$.addresses[*].country"=''ca''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].street"=''main st''') AND JSON_MATCH(person, '"$.addresses[1].street"=''second st''')["item1", "item2", "item3"]SELECT ...
FROM mytable
WHERE JSON_MATCH(arrayCol, '"$[*]"=''item1''')SELECT ...
FROM mytable
WHERE JSON_MATCH(arrayCol, '"$[1]"=''item2''')123
1.23
"Hello World"SELECT ...
FROM mytable
WHERE JSON_MATCH(valueCol, '"$"=123')nullSELECT ...
FROM mytable
WHERE JSON_MATCH(nullableCol, '"$" IS NULL')void aggregate(int length, AggregationResultHolder aggregationResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupBySV(int length, int[] groupKeyArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupByMV(int length, int[][] groupKeysArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);//default to limit 10
SELECT *
FROM myTable
SELECT *
FROM myTable
LIMIT 100SELECT "date", "timestamp"
FROM myTable SELECT COUNT(*), MAX(foo), SUM(bar)
FROM myTableSELECT MIN(foo), MAX(foo), SUM(foo), AVG(foo), bar, baz
FROM myTable
GROUP BY bar, baz
LIMIT 50SELECT MIN(foo), MAX(foo), SUM(foo), AVG(foo), bar, baz
FROM myTable
GROUP BY bar, baz
ORDER BY bar, MAX(foo) DESC
LIMIT 50SELECT COUNT(*)
FROM myTable
WHERE foo = 'foo'
AND bar BETWEEN 1 AND 20
OR (baz < 42 AND quux IN ('hello', 'goodbye') AND quuux NOT IN (42, 69))SELECT COUNT(*)
FROM myTable
WHERE foo IS NOT NULL
AND foo = 'foo'
AND bar BETWEEN 1 AND 20
OR (baz < 42 AND quux IN ('hello', 'goodbye') AND quuux NOT IN (42, 69))SELECT *
FROM myTable
WHERE quux < 5
LIMIT 50SELECT foo, bar
FROM myTable
WHERE baz > 20
ORDER BY bar DESC
LIMIT 100SELECT foo, bar
FROM myTable
WHERE baz > 20
ORDER BY bar DESC
LIMIT 50, 100SELECT COUNT(*)
FROM myTable
WHERE REGEXP_LIKE(airlineName, '^U.*')
GROUP BY airlineName LIMIT 10SELECT
CASE
WHEN price > 30 THEN 3
WHEN price > 20 THEN 2
WHEN price > 10 THEN 1
ELSE 0
END AS price_category
FROM myTableSELECT
SUM(
CASE
WHEN price > 30 THEN 30
WHEN price > 20 THEN 20
WHEN price > 10 THEN 10
ELSE 0
END) AS total_cost
FROM myTableSELECT COUNT(*)
FROM myTable
GROUP BY DATETIMECONVERT(timeColumnName, '1:MILLISECONDS:EPOCH', '1:HOURS:EPOCH', '1:HOURS')SELECT *
FROM myTable
WHERE UID = 'c8b3bce0b378fc5ce8067fc271a34892'SELECT ID_SET(yearID)
FROM baseballStats
WHERE teamID = 'WS1'SELECT ID_SET(playerName, 'expectedInsertions=10')
FROM baseballStats
WHERE teamID = 'WS1'SELECT ID_SET(playerName, 'expectedInsertions=100')
FROM baseballStats
WHERE teamID = 'WS1'SELECT ID_SET(playerName, 'expectedInsertions=100;fpp=0.01')
FROM baseballStats
WHERE teamID = 'WS1'SELECT yearID, count(*)
FROM baseballStats
WHERE IN_ID_SET(
yearID,
'ATowAAABAAAAAAA7ABAAAABtB24HbwdwB3EHcgdzB3QHdQd2B3cHeAd5B3oHewd8B30Hfgd/B4AHgQeCB4MHhAeFB4YHhweIB4kHigeLB4wHjQeOB48HkAeRB5IHkweUB5UHlgeXB5gHmQeaB5sHnAedB54HnwegB6EHogejB6QHpQemB6cHqAc='
) = 1
GROUP BY yearIDSELECT yearID, count(*)
FROM baseballStats
WHERE IN_ID_SET(
yearID,
'ATowAAABAAAAAAA7ABAAAABtB24HbwdwB3EHcgdzB3QHdQd2B3cHeAd5B3oHewd8B30Hfgd/B4AHgQeCB4MHhAeFB4YHhweIB4kHigeLB4wHjQeOB48HkAeRB5IHkweUB5UHlgeXB5gHmQeaB5sHnAedB54HnwegB6EHogejB6QHpQemB6cHqAc='
) = 0
GROUP BY yearIDSELECT yearID, count(*)
FROM baseballStats
WHERE IN_SUBQUERY(
yearID,
'SELECT ID_SET(yearID) FROM baseballStats WHERE teamID = ''WS1'''
) = 1
GROUP BY yearID SELECT yearID, count(*)
FROM baseballStats
WHERE IN_SUBQUERY(
yearID,
'SELECT ID_SET(yearID) FROM baseballStats WHERE teamID = ''WS1'''
) = 0
GROUP BY yearID SELECT yearID, count(*)
FROM baseballStats
WHERE IN_PARTITIONED_SUBQUERY(
yearID,
'SELECT ID_SET(yearID) FROM baseballStats WHERE teamID = ''WS1'''
) = 1
GROUP BY yearID SELECT yearID, count(*)
FROM baseballStats
WHERE IN_PARTITIONED_SUBQUERY(
yearID,
'SELECT ID_SET(yearID) FROM baseballStats WHERE teamID = ''WS1'''
) = 0
GROUP BY yearID {
"tableName": "myTable",
"tableType": "OFFLINE",
"queryConfig" : {
"disableGroovy": true
}
}<dependency>
<groupId>org.apache.pinot</groupId>
<artifactId>pinot-common</artifactId>
<version>0.5.0</version>
</dependency>include 'org.apache.pinot:pinot-common:0.5.0'//Example Scalar function
@ScalarFunction
static String mySubStr(String input, Integer beginIndex) {
return input.substring(beginIndex);
}SELECT mysubstr(playerName, 4)
FROM baseballStatsselect distinctCountThetaSketch(
sketchCol,
'nominalEntries=1024',
'country'=''USA'' AND 'state'=''CA'', 'device'=''mobile'', 'SET_INTERSECT($1, $2)'
)
from table
where country = 'USA' or device = 'mobile...' SELECT id,
json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null') last_name,
json_extract_scalar(jsoncolumn, '$.name.first', 'STRING', 'null') first_name
json_extract_scalar(jsoncolumn, '$.data[1]', 'STRING', 'null') value
FROM myTableSELECT id,
json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null') last_name,
json_extract_scalar(jsoncolumn, '$.name.first', 'STRING', 'null') first_name,
json_extract_scalar(jsoncolumn, '$.data[1]', 'STRING', 'null') value
FROM myTable
WHERE JSON_MATCH(jsoncolumn, '"$.data[1]" IS NOT NULL') SELECT json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null') last_name,
count(*)
FROM myTable
WHERE JSON_MATCH(jsoncolumn, '"$.data[1]" IS NOT NULL')
GROUP BY json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null')
ORDER BY 2 DESC SELECT json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null') last_name,
sum(json_extract_scalar(jsoncolumn, '$.id', 'INT', 0)) total
FROM myTable
WHERE JSON_MATCH(jsoncolumn, '"$.name.last" IS NOT NULL')
GROUP BY json_extract_scalar(jsoncolumn, '$.name.last', 'STRING', 'null')BROKER_REDUCE(limit:10)
└── COMBINE_SELECT
└── SELECT(selectList:playerID, playerName)
└── TRANSFORM_PASSTHROUGH(playerID, playerName)
└── PROJECT(playerName, playerID)
└── FILTER_MATCH_ENTIRE_SEGMENT(docs:97889)EXPLAIN PLAN FOR
SELECT playerID, playerName
FROM baseballStats
WHERE playerID = 'aardsda01' AND playerName = 'David Allan'
BROKER_REDUCE(limit:10)
└── COMBINE_SELECT
└── SELECT(selectList:playerID, playerName)
└── TRANSFORM_PASSTHROUGH(playerID, playerName)
└── PROJECT(playerName, playerID)
└── FILTER_AND
├── FILTER_INVERTED_INDEX(indexLookUp:inverted_index,operator:EQ,predicate:playerID = 'aardsda01')
└── FILTER_FULL_SCAN(operator:EQ,predicate:playerName = 'David Allan')EXPLAIN PLAN FOR
SELECT playerID, count(*)
FROM baseballStats
WHERE playerID != 'aardsda01'
GROUP BY playerID
BROKER_REDUCE(limit:10)
└── COMBINE_GROUPBY_ORDERBY
└── AGGREGATE_GROUPBY_ORDERBY(groupKeys:playerID, aggregations:count(*))
└── TRANORM_PASSTHROUGH(playerID)
└── PROJECT(playerID)
└── FILTER_INVERTED_INDEX(indexLookUp:inverted_index,operator:NOT_EQ,predicate:playerID != 'aardsda01')SELECT *
FROM ...
OPTION(minSegmentGroupTrimSize=<minSegmentGroupTrimSize>)SELECT *
FROM ...
OPTION(minServerGroupTrimSize=<minServerGroupTrimSize>)SELECT SUM(colA)
FROM myTable
GROUP BY colB
ORDER BY SUM(colA) DESC
HAVING SUM(colA) < 100
LIMIT 10curl -X POST \
-d '{"pql":"select * from flights limit 3"}' \
http://localhost:8099/query
{
"selectionResults":{
"columns":[
"Cancelled",
"Carrier",
"DaysSinceEpoch",
"Delayed",
"Dest",
"DivAirports",
"Diverted",
"Month",
"Origin",
"Year"
],
"results":[
[
"0",
"AA",
"16130",
"0",
"SFO",
[],
"0",
"3",
"LAX",
"2014"
],
[
"0",
"AA",
"16130",
"0",
"LAX",
[],
"0",
"3",
"SFO",
"2014"
],
[
"0",
"AA",
"16130",
"0",
"SFO",
[],
"0",
"3",
"LAX",
"2014"
]
]
},
"traceInfo":{},
"numDocsScanned":3,
"aggregationResults":[],
"timeUsedMs":10,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":102
}curl -X POST \
-d '{"pql":"select count(*) from flights"}' \
http://localhost:8099/query
{
"traceInfo":{},
"numDocsScanned":17,
"aggregationResults":[
{
"function":"count_star",
"value":"17"
}
],
"timeUsedMs":27,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":17
}curl -X POST \
-d '{"pql":"select count(*) from flights group by Carrier"}' \
http://localhost:8099/query
{
"traceInfo":{},
"numDocsScanned":23,
"aggregationResults":[
{
"groupByResult":[
{
"value":"10",
"group":["AA"]
},
{
"value":"9",
"group":["VX"]
},
{
"value":"4",
"group":["WN"]
}
],
"function":"count_star",
"groupByColumns":["Carrier"]
}
],
"timeUsedMs":47,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":23
}public static final String DB_URL = "jdbc:pinot://localhost:9000"
DriverManager.registerDriver(new PinotDriver());
Connection conn = DriverManager.getConnection(DB_URL);
Statement statement = conn.createStatement();
Integer limitResults = 10;
ResultSet rs = statement.executeQuery(String.format("SELECT UPPER(playerName) AS name FROM baseballStats LIMIT %d", limitResults));
Set<String> results = new HashSet<>();
while(rs.next()){
String playerName = rs.getString("name");
results.add(playerName);
}
conn.close();Connection conn = DriverManager.getConnection(DB_URL);
PreparedStatement statement = conn.prepareStatement("SELECT UPPER(playerName) AS name FROM baseballStats WHERE age = ?");
statement.setInt(1, 20);
ResultSet rs = statement.executeQuery();
Set<String> results = new HashSet<>();
while(rs.next()){
String playerName = rs.getString("name");
results.add(playerName);
}
conn.close();import org.apache.pinot.client.Connection;
import org.apache.pinot.client.ConnectionFactory;
import org.apache.pinot.client.Request;
import org.apache.pinot.client.ResultSetGroup;
import org.apache.pinot.client.ResultSet;
/**
* Demonstrates the use of the pinot-client to query Pinot from Java
*/
public class PinotClientExample {
public static void main(String[] args) {
// pinot connection
String zkUrl = "localhost:2181";
String pinotClusterName = "PinotCluster";
Connection pinotConnection = ConnectionFactory.fromZookeeper(zkUrl + "/" + pinotClusterName);
String query = "SELECT COUNT(*) FROM myTable GROUP BY foo";
// set queryType=sql for querying the sql endpoint
Request pinotClientRequest = new Request("sql", query);
ResultSetGroup pinotResultSetGroup = pinotConnection.execute(pinotClientRequest);
ResultSet resultTableResultSet = pinotResultSetGroup.getResultSet(0);
int numRows = resultTableResultSet.getRowCount();
int numColumns = resultTableResultSet.getColumnCount();
String columnValue = resultTableResultSet.getString(0, 1);
String columnName = resultTableResultSet.getColumnName(1);
System.out.println("ColumnName: " + columnName + ", ColumnValue: " + columnValue);
}
}Connection connection = ConnectionFactory.fromZookeeper
("some-zookeeper-server:2191/zookeeperPath");
Connection connection = ConnectionFactory.fromProperties("demo.properties");
Connection connection = ConnectionFactory.fromHostList
("broker-1:1234", "broker-2:1234", ...);ResultSetGroup resultSetGroup =
connection.execute(new Request("sql", "select * from foo..."));
// OR
Future<ResultSetGroup> futureResultSetGroup =
connection.executeAsync(new Request("sql", "select * from foo..."));PreparedStatement statement =
connection.prepareStatement(new Request("sql", "select * from foo where a = ?"));
statement.setString(1, "bar");
ResultSetGroup resultSetGroup = statement.execute();
// OR
Future<ResultSetGroup> futureResultSetGroup = statement.executeAsync();Request request = new Request("sql", "select foo, bar from baz where quux = 'quuux'");
ResultSetGroup resultSetGroup = connection.execute(request);
ResultSet resultTableResultSet = pinotResultSetGroup.getResultSet(0);
for (int i = 0; i < resultSet.getRowCount(); ++i) {
System.out.println("foo: " + resultSet.getString(i, 0));
System.out.println("bar: " + resultSet.getInt(i, 1));
}ResultSetGroup resultSetGroup =
connection.execute(new Request("pql", "select max(foo), min(foo) from bar"));
System.out.println("Number of result groups:" +
resultSetGroup.getResultSetCount(); // 2, min(foo) and max(foo)
ResultSet resultSetMax = resultSetGroup.getResultSet(0);
System.out.println("Max foo: " + resultSetMax.getInt(0));
ResultSet resultSetMin = resultSetGroup.getResultSet(1);
System.out.println("Min foo: " + resultSetMin.getInt(0));ResultSetGroup resultSetGroup =
connection.execute(
new Request("pql", "select min(foo), max(foo) from bar group by baz"));
System.out.println("Number of result groups:" +
resultSetGroup.getResultSetCount(); // 2, min(foo) and max(foo)
ResultSet minResultSet = resultSetGroup.getResultSet(0);
for(int i = 0; i < minResultSet.length(); ++i) {
System.out.println("Minimum foo for " + minResultSet.getGroupKeyString(i, 1) +
": " + minResultSet.getInt(i));
}
ResultSet maxResultSet = resultSetGroup.getResultSet(1);
for(int i = 0; i < maxResultSet.length(); ++i) {
System.out.println("Maximum foo for " + maxResultSet.getGroupKeyString(i, 1) +
": " + maxResultSet.getInt(i));
}final String username = "admin";
final String password = "verysecret";
// Concatenate username and password and use base64 to encode the concatenated string
String plainCredentials = username + ":" + password;
String base64Credentials = new String(Base64.getEncoder().encode(plainCredentials.getBytes()));
// Create authorization header
String authorizationHeader = "Basic " + base64Credentials;
Properties connectionProperties = new Properties();
connectionProperties.setProperty("headers.Authorization", authorizationHeader);
// Register new Pinot JDBC driver
DriverManager.registerDriver(new PinotDriver());
// Get a client connection and set the encoded authorization header
Connection connection = DriverManager.getConnection(DB_URL, connectionProperties);
// Test that your query successfully authenticates
Statement statement = connection.createStatement();
ResultSet rs = statement.executeQuery("SELECT count(*) FROM baseballStats LIMIT 1;");
while (rs.next()) {
String result = rs.getString("count(*)");
System.out.println(result);
}pip install pinotdbfrom pinotdb import connect
conn = connect(host='localhost', port=8099, path='/query/sql', scheme='http')
curs = conn.cursor()
curs.execute("""
SELECT place,
CAST(REGEXP_EXTRACT(place, '(.*),', 1) AS FLOAT) AS lat,
CAST(REGEXP_EXTRACT(place, ',(.*)', 1) AS FLOAT) AS lon
FROM places
LIMIT 10
""")
for row in curs:
print(row)from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
engine = create_engine('pinot://localhost:8099/query/sql?controller=http://localhost:9000/') # uses HTTP by default :(
# engine = create_engine('pinot+http://localhost:8099/query/sql?controller=http://localhost:9000/')
# engine = create_engine('pinot+https://localhost:8099/query/sql?controller=http://localhost:9000/')
places = Table('places', MetaData(bind=engine), autoload=True)
print(select([func.count('*')], from_obj=places).scalar())git clone [email protected]:python-pinot-dbapi/pinot-dbapi.git
cd pinot-dbapidocker run \
--name pinot-quickstart \
-p 2123:2123 \
-p 9000:9000 \
-p 8000:8000 \
apachepinot/pinot:latest QuickStart -type batchpython3 examples/pinot-quickstart-batch.pySending SQL to Pinot: SELECT * FROM baseballStats LIMIT 5
[0, 11, 0, 0, 0, 0, 0, 0, 0, 0, 'NL', 11, 11, 'aardsda01', 'David Allan', 1, 0, 0, 0, 0, 0, 0, 'SFN', 0, 2004]
[2, 45, 0, 0, 0, 0, 0, 0, 0, 0, 'NL', 45, 43, 'aardsda01', 'David Allan', 1, 0, 0, 0, 1, 0, 0, 'CHN', 0, 2006]
[0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 'AL', 25, 2, 'aardsda01', 'David Allan', 1, 0, 0, 0, 0, 0, 0, 'CHA', 0, 2007]
[1, 5, 0, 0, 0, 0, 0, 0, 0, 0, 'AL', 47, 5, 'aardsda01', 'David Allan', 1, 0, 0, 0, 0, 0, 1, 'BOS', 0, 2008]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 'AL', 73, 3, 'aardsda01', 'David Allan', 1, 0, 0, 0, 0, 0, 0, 'SEA', 0, 2009]
Sending SQL to Pinot: SELECT playerName, sum(runs) FROM baseballStats WHERE yearID>=2000 GROUP BY playerName LIMIT 5
['Scott Michael', 26.0]
['Justin Morgan', 0.0]
['Jason Andre', 0.0]
['Jeffrey Ellis', 0.0]
['Maximiliano R.', 16.0]
Sending SQL to Pinot: SELECT playerName,sum(runs) AS sum_runs FROM baseballStats WHERE yearID>=2000 GROUP BY playerName ORDER BY sum_runs DESC LIMIT 5
['Adrian', 1820.0]
['Jose Antonio', 1692.0]
['Rafael', 1565.0]
['Brian Michael', 1500.0]
['Alexander Emmanuel', 1426.0]from pinotdb import connect
conn = connect(host='localhost', port=8000, path='/query/sql', scheme='http')
curs = conn.cursor()
curs.execute("""
SELECT *
FROM baseballStats
WHERE league IN (%(leagues)s)
""", {"leagues": ["AA", "NL"]})
for row in curs:
print(row)
curs.execute("""
SELECT *
FROM baseballStats
WHERE baseOnBalls > (%(score)d)
""", {"score": 0})
for row in curs:
print(row)docker run \
--name pinot-quickstart \
-p 2123:2123 \
-p 9000:9000 \
-p 8000:8000 \
apachepinot/pinot:latest QuickStart -type hybridpython3 examples/pinot-quickstart-hybrid.pySending SQL to Pinot: SELECT * FROM airlineStats LIMIT 5
[171, 153, 19393, 0, 8, 8, 1433, '1400-1459', 0, 1425, 1240, 165, 'null', 0, 'WN', -2147483648, 1, 27, 17540, 0, 2, 2, 1242, '1200-1259', 0, 'MDW', 13232, 1323202, 30977, 'Chicago, IL', 'IL', 17, 'Illinois', 41, 861, 4, -2147483648, [-2147483648], 0, [-2147483648], ['null'], -2147483648, -2147483648, [-2147483648], -2147483648, ['null'], [-2147483648], [-2147483648], [-2147483648], 0, -2147483648, '2014-01-27', 402, 1, -2147483648, -2147483648, 1, -2147483648, 'BOS', 10721, 1072102, 30721, 'Boston, MA', 'MA', 25, 'Massachusetts', 13, 1, ['null'], -2147483648, 'N556WN', 6, 12, -2147483648, 'WN', -2147483648, 1254, 1427, 2014]
[183, 141, 20398, 1, 17, 17, 1302, '1200-1259', 1, 1245, 1005, 160, 'null', 0, 'MQ', 0, 1, 27, 17540, 0, -6, 0, 959, '1000-1059', -1, 'CMH', 11066, 1106603, 31066, 'Columbus, OH', 'OH', 39, 'Ohio', 44, 990, 4, -2147483648, [-2147483648], 0, [-2147483648], ['null'], -2147483648, -2147483648, [-2147483648], -2147483648, ['null'], [-2147483648], [-2147483648], [-2147483648], 0, -2147483648, '2014-01-27', 3574, 1, 0, -2147483648, 1, 17, 'MIA', 13303, 1330303, 32467, 'Miami, FL', 'FL', 12, 'Florida', 33, 1, ['null'], 0, 'N605MQ', 13, 29, -2147483648, 'MQ', 0, 1028, 1249, 2014]
[-2147483648, -2147483648, 20304, -2147483648, -2147483648, -2147483648, -2147483648, '2100-2159', -2147483648, 2131, 2005, 146, 'null', 0, 'OO', -2147483648, 1, 27, 17541, 1, 52, 52, 2057, '2000-2059', 3, 'COS', 11109, 1110902, 30189, 'Colorado Springs, CO', 'CO', 8, 'Colorado', 82, 809, 4, -2147483648, [11292], 1, [1129202], ['DEN'], -2147483648, 73, [9], 0, ['null'], [9], [-2147483648], [2304], 1, -2147483648, '2014-01-27', 5554, 1, -2147483648, -2147483648, 1, -2147483648, 'IAH', 12266, 1226603, 31453, 'Houston, TX', 'TX', 48, 'Texas', 74, 1, ['SEA', 'PSC', 'PHX', 'MSY', 'ATL', 'TYS', 'DEN', 'CHS', 'PDX', 'LAX', 'EWR', 'SFO', 'PIT', 'RDU', 'RAP', 'LSE', 'SAN', 'SBN', 'IAH', 'OAK', 'BRO', 'JFK', 'SAT', 'ORD', 'ACY', 'DFW', 'BWI'], -2147483648, 'N795SK', -2147483648, 19, -2147483648, 'OO', -2147483648, 2116, -2147483648, 2014]
[153, 125, 20436, 1, 41, 41, 1442, '1400-1459', 2, 1401, 1035, 146, 'null', 0, 'F9', 2, 1, 27, 17541, 1, 34, 34, 1109, '1000-1059', 2, 'DEN', 11292, 1129202, 30325, 'Denver, CO', 'CO', 8, 'Colorado', 82, 967, 4, -2147483648, [-2147483648], 0, [-2147483648], ['null'], -2147483648, -2147483648, [-2147483648], -2147483648, ['null'], [-2147483648], [-2147483648], [-2147483648], 0, -2147483648, '2014-01-27', 658, 1, 8, -2147483648, 1, 31, 'SFO', 14771, 1477101, 32457, 'San Francisco, CA', 'CA', 6, 'California', 91, 1, ['null'], 0, 'N923FR', 11, 17, -2147483648, 'F9', 0, 1126, 1431, 2014]
[-2147483648, -2147483648, 20304, -2147483648, -2147483648, -2147483648, -2147483648, '1400-1459', -2147483648, 1432, 1314, 78, 'B', 1, 'OO', -2147483648, 1, 27, 17541, -2147483648, -2147483648, -2147483648, -2147483648, '1300-1359', -2147483648, 'EAU', 11471, 1147103, 31471, 'Eau Claire, WI', 'WI', 55, 'Wisconsin', 45, 268, 2, -2147483648, [-2147483648], 0, [-2147483648], ['null'], -2147483648, -2147483648, [-2147483648], -2147483648, ['null'], [-2147483648], [-2147483648], [-2147483648], 0, -2147483648, '2014-01-27', 5455, 1, -2147483648, -2147483648, 1, -2147483648, 'ORD', 13930, 1393003, 30977, 'Chicago, IL', 'IL', 17, 'Illinois', 41, 1, ['null'], -2147483648, 'N903SW', -2147483648, -2147483648, -2147483648, 'OO', -2147483648, -2147483648, -2147483648, 2014]
Sending SQL to Pinot: SELECT count(*) FROM airlineStats LIMIT 5
[17772]
Sending SQL to Pinot: SELECT AirlineID, sum(Cancelled) FROM airlineStats WHERE Year > 2010 GROUP BY AirlineID LIMIT 5
[20409, 40.0]
[19930, 16.0]
[19805, 60.0]
[19790, 115.0]
[20366, 172.0]
Sending SQL to Pinot: select OriginCityName, max(Flights) from airlineStats group by OriginCityName ORDER BY max(Flights) DESC LIMIT 5
['Casper, WY', 1.0]
['Deadhorse, AK', 1.0]
['Austin, TX', 1.0]
['Chicago, IL', 1.0]
['Monterey, CA', 1.0]
Sending SQL to Pinot: SELECT OriginCityName, sum(Cancelled) AS sum_cancelled FROM airlineStats WHERE Year>2010 GROUP BY OriginCityName ORDER BY sum_cancelled DESC LIMIT 5
['Chicago, IL', 178.0]
['Atlanta, GA', 111.0]
['New York, NY', 65.0]
['Houston, TX', 62.0]
['Denver, CO', 49.0]
Sending Count(*) SQL to Pinot
17773
Sending SQL: "SELECT OriginCityName, sum(Cancelled) AS sum_cancelled FROM "airlineStats" WHERE Year>2010 GROUP BY OriginCityName ORDER BY sum_cancelled DESC LIMIT 5" to Pinot
[('Chicago, IL', 178.0), ('Atlanta, GA', 111.0), ('New York, NY', 65.0), ('Houston, TX', 62.0), ('Denver, CO', 49.0)]go build ./examples/batch-quickstart
./batch-quickstartpinotClient := pinot.NewFromZookeeper([]string{"localhost:2123"}, "", "QuickStartCluster")pinotClient := pinot.NewFromBrokerList([]string{"localhost:8000"})pinotClient := pinot.NewWithConfig(&pinot.ClientConfig{
ZkConfig: &pinot.ZookeeperConfig{
ZookeeperPath: zkPath,
PathPrefix: strings.Join([]string{zkPathPrefix, pinotCluster}, "/"),
SessionTimeoutSec: defaultZkSessionTimeoutSec,
},
ExtraHTTPHeader: map[string]string{
"extra-header":"value",
},
})pinotClient, err := pinot.NewFromZookeeper([]string{"localhost:2123"}, "", "QuickStartCluster")
if err != nil {
log.Error(err)
}
brokerResp, err := pinotClient.ExecuteSQL("baseballStats", "select count(*) as cnt, sum(homeRuns) as sum_homeRuns from baseballStats group by teamID limit 10")
if err != nil {
log.Error(err)
}
log.Infof("Query Stats: response time - %d ms, scanned docs - %d, total docs - %d", brokerResp.TimeUsedMs, brokerResp.NumDocsScanned, brokerResp.TotalDocs)type BrokerResponse struct {
AggregationResults []*AggregationResult `json:"aggregationResults,omitempty"`
SelectionResults *SelectionResults `json:"SelectionResults,omitempty"`
ResultTable *ResultTable `json:"resultTable,omitempty"`
Exceptions []Exception `json:"exceptions"`
TraceInfo map[string]string `json:"traceInfo,omitempty"`
NumServersQueried int `json:"numServersQueried"`
NumServersResponded int `json:"numServersResponded"`
NumSegmentsQueried int `json:"numSegmentsQueried"`
NumSegmentsProcessed int `json:"numSegmentsProcessed"`
NumSegmentsMatched int `json:"numSegmentsMatched"`
NumConsumingSegmentsQueried int `json:"numConsumingSegmentsQueried"`
NumDocsScanned int64 `json:"numDocsScanned"`
NumEntriesScannedInFilter int64 `json:"numEntriesScannedInFilter"`
NumEntriesScannedPostFilter int64 `json:"numEntriesScannedPostFilter"`
NumGroupsLimitReached bool `json:"numGroupsLimitReached"`
TotalDocs int64 `json:"totalDocs"`
TimeUsedMs int `json:"timeUsedMs"`
MinConsumingFreshnessTimeMs int64 `json:"minConsumingFreshnessTimeMs"`
}// ResultTable is a ResultTable
type ResultTable struct {
DataSchema RespSchema `json:"dataSchema"`
Rows [][]interface{} `json:"rows"`
}// RespSchema is response schema
type RespSchema struct {
ColumnDataTypes []string `json:"columnDataTypes"`
ColumnNames []string `json:"columnNames"`
}func (r ResultTable) GetRowCount() int
func (r ResultTable) GetColumnCount() int
func (r ResultTable) GetColumnName(columnIndex int) string
func (r ResultTable) GetColumnDataType(columnIndex int) string
func (r ResultTable) Get(rowIndex int, columnIndex int) interface{}
func (r ResultTable) GetString(rowIndex int, columnIndex int) string
func (r ResultTable) GetInt(rowIndex int, columnIndex int) int
func (r ResultTable) GetLong(rowIndex int, columnIndex int) int64
func (r ResultTable) GetFloat(rowIndex int, columnIndex int) float32
func (r ResultTable) GetDouble(rowIndex int, columnIndex int) float64// Print Response Schema
for c := 0; c < brokerResp.ResultTable.GetColumnCount(); c++ {
fmt.Printf("%s(%s)\t", brokerResp.ResultTable.GetColumnName(c), brokerResp.ResultTable.GetColumnDataType(c))
}
fmt.Println()
// Print Row Table
for r := 0; r < brokerResp.ResultTable.GetRowCount(); r++ {
for c := 0; c < brokerResp.ResultTable.GetColumnCount(); c++ {
fmt.Printf("%v\t", brokerResp.ResultTable.Get(r, c))
}
fmt.Println()
}select count(*)
from myTable "tableIndexConfig": {
"noDictionaryColumns": ["metric1", "metric2"],
"aggregateMetrics": true,
...
} "broker": "brokerTenantName",
"server": "serverTenantName",
"tagOverrideConfig" : {
"realtimeConsuming" : "serverTenantName_REALTIME"
"realtimeCompleted" : "serverTenantName_OFFLINE"
}
}docker run \
--network=pinot-demo \
--name pinot-batch-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -schemaFile examples/batch/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: a413b0013806, version: Unknown
{"status":"Table airlineStats_OFFLINE succesfully added"}bin/pinot-admin.sh AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-exec# add schema
curl -F schemaName=@airlineStats_schema.json localhost:9000/schemas
# add table
curl -i -X POST -H 'Content-Type: application/json' \
-d @airlineStats_offline_table_config.json localhost:9000/tablesdocker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper pinot-zookeeper:2181/kafka \
--partitions=1 --replication-factor=1 \
--create --topic flights-realtimedocker run \
--network=pinot-demo \
--name pinot-streaming-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json -schemaFile examples/stream/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: 8fbe601012f3, version: Unknown
{"status":"Table airlineStats_REALTIME succesfully added"}bin/pinot-admin.sh StartZookeeper -zkPort 2191bin/pinot-admin.sh StartKafka -zkAddress=localhost:2191/kafka -port 19092"OFFLINE": {
"tableName": "pinotTable",
"tableType": "OFFLINE",
"segmentsConfig": {
...
},
"tableIndexConfig": {
...
},
"tenants": {
"broker": "myBrokerTenant",
"server": "myServerTenant"
},
"metadata": {
...
}
},
"REALTIME": {
"tableName": "pinotTable",
"tableType": "REALTIME",
"segmentsConfig": {
...
},
"tableIndexConfig": {
...
"streamConfigs": {
...
},
},
"tenants": {
"broker": "myBrokerTenant",
"server": "myServerTenant"
},
"metadata": {
...
}
}
}bin/pinot-admin.sh AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/stream/airlineStats/airlineStats_realtime_table_config.json \
-execUsage: StartMinion
-help : Print this message. (required=false)
-minionHost <String> : Host name for minion. (required=false)
-minionPort <int> : Port number to start the minion at. (required=false)
-zkAddress <http> : HTTP address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Minion Starter Config file. (required=false)public interface PinotTaskGenerator {
/**
* Initializes the task generator.
*/
void init(ClusterInfoAccessor clusterInfoAccessor);
/**
* Returns the task type of the generator.
*/
String getTaskType();
/**
* Generates a list of tasks to schedule based on the given table configs.
*/
List<PinotTaskConfig> generateTasks(List<TableConfig> tableConfigs);
/**
* Returns the timeout in milliseconds for each task, 3600000 (1 hour) by default.
*/
default long getTaskTimeoutMs() {
return JobConfig.DEFAULT_TIMEOUT_PER_TASK;
}
/**
* Returns the maximum number of concurrent tasks allowed per instance, 1 by default.
*/
default int getNumConcurrentTasksPerInstance() {
return JobConfig.DEFAULT_NUM_CONCURRENT_TASKS_PER_INSTANCE;
}
/**
* Performs necessary cleanups (e.g. remove metrics) when the controller leadership changes.
*/
default void nonLeaderCleanUp() {
}
}public interface PinotTaskExecutorFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the executor.
*/
String getTaskType();
/**
* Creates a new task executor.
*/
PinotTaskExecutor create();
}public interface PinotTaskExecutor {
/**
* Executes the task based on the given task config and returns the execution result.
*/
Object executeTask(PinotTaskConfig pinotTaskConfig)
throws Exception;
/**
* Tries to cancel the task.
*/
void cancel();
}public interface MinionEventObserverFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the event observer.
*/
String getTaskType();
/**
* Creates a new task event observer.
*/
MinionEventObserver create();
}public interface MinionEventObserver {
/**
* Invoked when a minion task starts.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskStart(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task succeeds.
*
* @param pinotTaskConfig Pinot task config
* @param executionResult Execution result
*/
void notifyTaskSuccess(PinotTaskConfig pinotTaskConfig, @Nullable Object executionResult);
/**
* Invoked when a minion task gets cancelled.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskCancelled(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task encounters exception.
*
* @param pinotTaskConfig Pinot task config
* @param exception Exception encountered during execution
*/
void notifyTaskError(PinotTaskConfig pinotTaskConfig, Exception exception);
}"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY",
"batchConfigMaps": [
{
"input.fs.className": "org.apache.pinot.plugin.filesystem.S3PinotFS",
"input.fs.prop.region": "us-west-2",
"input.fs.prop.secretKey": "....",
"input.fs.prop.accessKey": "....",
"inputDirURI": "s3://my.s3.bucket/batch/airlineStats/rawdata/",
"includeFileNamePattern": "glob:**/*.avro",
"excludeFileNamePattern": "glob:**/*.tmp",
"inputFormat": "avro"
}
]
}
},
"task": {
"taskTypeConfigsMap": {
"SegmentGenerationAndPushTask": {
"schedule": "0 */10 * * * ?",
"tableMaxNumTasks": 10
}
}
}{
...
"task": {
"taskTypeConfigsMap": {
"myTask": {
"myProperty1": "value1",
"myProperty2": "value2"
}
}
}
}Using "POST /cluster/configs" API on CLUSTER tab in Swagger, with this payload
{
"RealtimeToOfflineSegmentsTask.timeoutMs": "600000",
"RealtimeToOfflineSegmentsTask.numConcurrentTasksPerInstance": "4"
} "task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bucketTimePeriod": "1h",
"bufferTimePeriod": "1h",
"schedule": "0 * * * * ?"
}
}
},docker run \
--network=pinot-demo \
--name pinot-minion \
-d ${PINOT_IMAGE} StartMinion \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartMinion \
-zkAddress localhost:2181serverTenantName_REALTIME"tenants": {
"broker": "brokerTenantName",
"server": "serverTenantName"
}{
"tenantRole" : "BROKER",
"tenantName" : "sampleBrokerTenant",
"numberOfInstances" : 3
}bin/pinot-admin.sh AddTenant \
-name sampleBrokerTenant
-role BROKER
-instanceCount 3 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-broker-tenant.json localhost:9000/tenants{
"tenantRole" : "SERVER",
"tenantName" : "sampleServerTenant",
"offlineInstances" : 1,
"realtimeInstances" : 1
}bin/pinot-admin.sh AddTenant \
-name sampleServerTenant \
-role SERVER \
-offlineInstanceCount 1 \
-realtimeInstanceCount 1 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-server-tenant.json localhost:9000/tenantsMILLISECONDS{
"schemaName": "flights",
"dimensionFieldSpecs": [
{
"name": "flightNumber",
"dataType": "LONG"
},
{
"name": "tags",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": "null"
}
],
"metricFieldSpecs": [
{
"name": "price",
"dataType": "DOUBLE",
"defaultNullValue": 0
}
],
"dateTimeFieldSpecs": [
{
"name": "millisSinceEpoch",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "15:MINUTES"
},
{
"name": "hoursSinceEpoch",
"dataType": "INT",
"format": "1:HOURS:EPOCH",
"granularity": "1:HOURS"
},
{
"name": "dateString",
"dataType": "STRING",
"format": "1:DAYS:SIMPLE_DATE_FORMAT:yyyy-MM-dd",
"granularity": "1:DAYS"
}
]
}bin/pinot-admin.sh AddSchema -schemaFile flights-schema.json -exec
OR
bin/pinot-admin.sh AddTable -schemaFile flights-schema.json -tableFile flights-table.json -execcurl -F [email protected] localhost:9000/schemas<activeProfiles>
<activeProfile>
apple-silicon
</activeProfile>
</activeProfiles>
<profiles>
<profile>
<id>apple-silicon</id>
<properties>
<os.detected.classifier>osx-x86_64</os.detected.classifier>
</properties>
</profile>
</profiles>./bin/pinot-admin.sh QuickStart -type batchexport JAVA_OPTS="-Xms4G -Xmx8G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"export JAVA_OPTS="-Xms4G -Xmx8G"./bin/pinot-admin.sh StartZookeeper \
-zkPort 2191export JAVA_OPTS="-Xms4G -Xmx8G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"
./bin/pinot-admin.sh StartController \
-zkAddress localhost:2191 \
-controllerPort 9000export JAVA_OPTS="-Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log"
./bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2191export JAVA_OPTS="-Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log"
./bin/pinot-admin.sh StartServer \
-zkAddress localhost:2191./bin/pinot-admin.sh StartKafka \
-zkAddress=localhost:2191/kafka \
-port 19092PINOT_VERSION=0.10.0 #set to the Pinot version you decide to use
wget https://downloads.apache.org/pinot/apache-pinot-$PINOT_VERSION/apache-pinot-$PINOT_VERSION-bin.tar.gz# untar it
tar -zxvf apache-pinot-$PINOT_VERSION-bin.tar.gz
# navigate to directory containing the launcher scripts
cd apache-pinot-$PINOT_VERSION-bin# checkout pinot
git clone https://github.com/apache/pinot.git
cd
kubectl get all -n pinot-quickstarthelm repo add incubator https://charts.helm.sh/incubator
helm install -n pinot-quickstart kafka incubator/kafka --set replicas=1,zookeeper.image.tag=latesthelm repo add incubator https://charts.helm.sh/incubator
helm install --namespace "pinot-quickstart" --name kafka incubator/kafka --set zookeeper.image.tag=latest kubectl get all -n pinot-quickstart | grep kafkapod/kafka-0 1/1 Running 0 2m
pod/kafka-zookeeper-0 1/1 Running 0 10m
pod/kafka-zookeeper-1 1/1 Running 0 9m
pod/kafka-zookeeper-2 1/1 Running 0 8mkubectl -n pinot-quickstart exec kafka-0 -- kafka-topics --zookeeper kafka-zookeeper:2181 --topic flights-realtime --create --partitions 1 --replication-factor 1
kubectl -n pinot-quickstart exec kafka-0 -- kafka-topics --zookeeper kafka-zookeeper:2181 --topic flights-realtime-avro --create --partitions 1 --replication-factor 1kubectl apply -f pinot/pinot-realtime-quickstart.yml./query-pinot-data.shhelm repo add superset https://apache.github.io/supersethelm inspect values superset/superset > /tmp/superset-values.yamlkubectl create ns superset
helm upgrade --install --values /tmp/superset-values.yaml superset superset/superset -n supersetkubectl get all -n supersetkubectl port-forward service/superset 18088:8088 -n supersethelm repo add trino https://trinodb.github.io/charts/helm search repo trinohelm inspect values trino/trino > /tmp/trino-values.yamladditionalCatalogs:
pinot: |
connector.name=pinot
pinot.controller-urls=pinot-controller.pinot-quickstart:9000kubectl create ns trino-quickstart
helm install my-trino trino/trino --version 0.2.0 -n trino-quickstart --values /tmp/trino-values.yamlkubectl get pods -n trino-quickstartcurl -L https://repo1.maven.org/maven2/io/trino/trino-cli/363/trino-cli-363-executable.jar -o /tmp/trino && chmod +x /tmp/trinoecho "Visit http://127.0.0.1:18080 to use your application"
kubectl port-forward service/my-trino 18080:8080 -n trino-quickstart/tmp/trino --server localhost:18080 --catalog pinot --schema defaulttrino:default> show catalogs; Catalog
---------
pinot
system
tpcds
tpch
(4 rows)
Query 20211025_010256_00002_mxcvx, FINISHED, 2 nodes
Splits: 36 total, 36 done (100.00%)
0.70 [0 rows, 0B] [0 rows/s, 0B/s]trino:default> show tables; Table
--------------
airlinestats
(1 row)
Query 20211025_010326_00003_mxcvx, FINISHED, 3 nodes
Splits: 36 total, 36 done (100.00%)
0.28 [1 rows, 29B] [3 rows/s, 104B/s]trino:default> DESCRIBE airlinestats; Column | Type | Extra | Comment
----------------------+----------------+-------+---------
flightnum | integer | |
origin | varchar | |
quarter | integer | |
lateaircraftdelay | integer | |
divactualelapsedtime | integer | |
divwheelsons | array(integer) | |
divwheelsoffs | array(integer) | |
......
Query 20211025_010414_00006_mxcvx, FINISHED, 3 nodes
Splits: 36 total, 36 done (100.00%)
0.37 [79 rows, 5.96KB] [212 rows/s, 16KB/s]trino:default> select count(*) as cnt from airlinestats limit 10; cnt
------
9746
(1 row)
Query 20211025_015607_00009_mxcvx, FINISHED, 2 nodes
Splits: 17 total, 17 done (100.00%)
0.24 [1 rows, 9B] [4 rows/s, 38B/s]helm install presto pinot/presto -n pinot-quickstartkubectl apply -f presto-coordinator.yamlhelm inspect values pinot/presto > /tmp/presto-values.yamlhelm install presto pinot/presto -n pinot-quickstart --values /tmp/presto-values.yamlkubectl get pods -n pinot-quickstart./pinot-presto-cli.shcurl -L https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.246/presto-cli-0.246-executable.jar -o /tmp/presto-cli && chmod +x /tmp/presto-clikubectl port-forward service/presto-coordinator 18080:8080 -n pinot-quickstart> /dev/null &/tmp/presto-cli --server localhost:18080 --catalog pinot --schema defaultpresto:default> show catalogs; Catalog
---------
pinot
system
(2 rows)
Query 20191112_050827_00003_xkm4g, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:01 [0 rows, 0B] [0 rows/s, 0B/s]presto:default> show tables; Table
--------------
airlinestats
(1 row)
Query 20191112_050907_00004_xkm4g, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:01 [1 rows, 29B] [1 rows/s, 41B/s]presto:default> DESCRIBE pinot.dontcare.airlinestats; Column | Type | Extra | Comment
----------------------+---------+-------+---------
flightnum | integer | |
origin | varchar | |
quarter | integer | |
lateaircraftdelay | integer | |
divactualelapsedtime | integer | |
......
Query 20191112_051021_00005_xkm4g, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:02 [80 rows, 6.06KB] [35 rows/s, 2.66KB/s]presto:default> select count(*) as cnt from pinot.dontcare.airlinestats limit 10; cnt
------
9745
(1 row)
Query 20191112_051114_00006_xkm4g, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:00 [1 rows, 8B] [2 rows/s, 19B/s]kubectl delete ns pinot-quickstarthelm repo add pinot https://raw.githubusercontent.com/apache/pinot/master/kubernetes/helm
kubectl create ns pinot-quickstart
helm install pinot pinot/pinot \
-n pinot-quickstart \
--set cluster.name=pinot \
--set server.replicaCount=2




# checkout pinot
git clone https://github.com/apache/pinot.git
cd pinot/kubernetes/helmcurl -X GET "http://localhost:9000/debug/tables/airlineStats?verbosity=0" -H "accept: application/json"{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestamp":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestamp":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestamp":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestamp":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestamp":1572854400000}{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestamp",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "localhost:9876",
"realtime.segment.flush.threshold.time": "3600000",
"realtime.segment.flush.threshold.rows": "50000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}docker run \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost pinot-quickstart \
-controllerPort 9000 \
-execbin/pinot-admin.sh AddTable \
-schemaFile /path/to/transcript-schema.json \
-tableConfigFile /path/to/transcript-table-realtime.json \
-exec{
"primaryKeyColumns": ["event_id"]
}{
"upsertConfig": {
"mode": "FULL"
}
}{
"upsertConfig": {
"mode": "PARTIAL",
"partialUpsertStrategies":{
"rsvp_count": "INCREMENT",
"group_name": "UNION",
"venue_name": "APPEND"
}
}
}{
"upsertConfig": {
"mode": "PARTIAL",
"defaultPartialUpsertStrategy": "OVERWRITE",
"partialUpsertStrategies":{
"rsvp_count": "INCREMENT",
"group_name": "UNION",
"venue_name": "APPEND"
}
}
}{
"upsertConfig": {
"mode": "FULL",
"comparisonColumn": "anotherTimeColumn",
"hashFunction": "NONE"
}
}{
"routing": {
"instanceSelectorType": "strictReplicaGroup"
}
}{
"tableName": "meetupRsvp",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "mtime",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "1",
"segmentPushType": "APPEND",
"segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy",
"schemaName": "meetupRsvp",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowLevel",
"stream.kafka.topic.name": "meetupRSVPEvents",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.hlc.zk.connect.string": "localhost:2191/kafka",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:19092",
"realtime.segment.flush.threshold.rows": 30
}
},
"metadata": {
"customConfigs": {}
},
"routing": {
"instanceSelectorType": "strictReplicaGroup"
},
"upsertConfig": {
"mode": "FULL"
}
}# stop previous quick start cluster, if any
bin/quick-start-upsert-streaming.sh# stop previous quick start cluster, if any
bin/quick-start-partial-upsert-streaming.shgroup_topics under group is unnested into the top-level, and convert the output to a collection of two rows. Note the handling of the nested field within group_topics, and the eventual top-level field of group.group_topics.urlkey. All the collections to unnest shall be included in configuration fieldsToUnnest.{
"ingestionConfig":{
"transformConfigs": [
{
"columnName": "group_json",
"transformFunction": "jsonFormat(\"group\")"
}
],
},
...
"tableIndexConfig": {
"loadMode": "MMAP",
"noDictionaryColumns": [
"group_json"
],
"jsonIndexColumns": [
"group_json"
]
},
}{
{
"name": "group_json",
"dataType": "JSON",
"maxLength": 2147483647
}
...
}{
"ingestionConfig": {
"complexTypeConfig": {
"delimiter": '.',
"fieldsToUnnest": ["group.group_topics"],
"collectionNotUnnestedToJson": "NON_PRIMITIVE"
}
}
}SELECT "group.group_topics.urlkey",
"group.group_topics.topic_name",
"group.group_id"
FROM meetupRsvp
LIMIT 10bin/pinot-admin.sh AvroSchemaToPinotSchema \
-timeColumnName fields.hoursSinceEpoch \
-avroSchemaFile /tmp/test.avsc \
-pinotSchemaName myTable \
-outputDir /tmp/test \
-fieldsToUnnest entriesbin/pinot-admin.sh JsonToPinotSchema \
-timeColumnName hoursSinceEpoch \
-jsonFile /tmp/test.json \
-pinotSchemaName myTable \
-outputDir /tmp/test \
-fieldsToUnnest payload.commits{
"tableIndexConfig": {
"sortedColumn": [
"column_name"
],
...
}
}$ grep memberId <segment_name>/v3/metadata.properties | grep isSorted
column.memberId.isSorted = truecurl -X GET \
"http://localhost:9000/segments/baseballStats/metadata?columns=playerID&columns=teamID" \
-H "accept: application/json" 2>/dev/null | \
jq -c '.[] | . as $parent |
.columns[] |
[$parent .segmentName, .columnName, .sorted]'["baseballStats_OFFLINE_0","teamID",false]
["baseballStats_OFFLINE_0","playerID",false]{
"tableIndexConfig": {
"noDictionaryColumns": [
"column_name",
...
],
...
}
}SELECT SUM(Impressions)
FROM myTable
WHERE Country = 'USA'
AND Browser = 'Chrome'
GROUP BY Locale"tableIndexConfig": {
"starTreeIndexConfigs": [{
"dimensionsSplitOrder": [
"Country",
"Browser",
"Locale"
],
"skipStarNodeCreationForDimensions": [
],
"functionColumnPairs": [
"SUM__Impressions"
],
"maxLeafRecords": 1
}],
...
}ST_LinestringST_PolygonST_MultiPolygonST_Distance(loc1, loc2) < x{
"dataType": "BYTES",
"name": "location_st_point",
"transformFunction": "toSphericalGeography(stPoint(lon,lat))"
}{
"fieldConfigList": [
{
"name": "location_st_point",
"encodingType":"RAW",
"indexType":"H3",
"properties": {
"resolutions": "5"
}
}
],
"tableIndexConfig": {
"loadMode": "MMAP",
"noDictionaryColumns": [
"location_st_point"
]
},
}SELECT address, ST_DISTANCE(location_st_point, ST_Point(-122, 37, 1))
FROM starbucksStores
WHERE ST_DISTANCE(location_st_point, ST_Point(-122, 37, 1)) < 5000
limit 1000dateTrunc('DAY', ts) will be translated to use the underly column $ts$DAY to fetch data.
2.2 PREDICATE: range index is auto-built for all granularity columns.select count(*), datetrunc('WEEK', ts) as tsWeek from airlineStats WHERE tsWeek > fromDateTime('2014-01-16', 'yyyy-MM-dd') group by tsWeek limit 10select dateTrunc('YEAR', event_time) as y, dateTrunc('MONTH', event_time) as m, sum(pull_request_commits) from githubEvents group by y, m limit 1000 Option(timeoutMs=3000000){
"tableName": "airlineStats",
"tableType": "OFFLINE",
"segmentsConfig": {
"timeColumnName": "DaysSinceEpoch",
"timeType": "DAYS",
"segmentPushType": "APPEND",
"segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy",
"replication": "1"
},
"tenants": {},
"fieldConfigList": [
{
"name": "ts",
"encodingType": "DICTIONARY",
"indexTypes": ["TIMESTAMP"],
"timestampConfig": {
"granularities": [
"DAY",
"WEEK",
"MONTH"
]
}
}
],
"tableIndexConfig": {
"loadMode": "MMAP"
},
"metadata": {
"customConfigs": {}
},
"ingestionConfig": {}
}
CSVJSONORCParquetThrift2020/03/09 23:37:19.879 ERROR [HelixTaskExecutor] [CallbackProcessor@b808af5-pinot] [pinot-broker] [] Message cannot be processed: 78816abe-5288-4f08-88c0-f8aa596114fe, {CREATE_TIMESTAMP=1583797034542, MSG_ID=78816abe-5288-4f08-88c0-f8aa596114fe, MSG_STATE=unprocessable, MSG_SUBTYPE=REFRESH_SEGMENT, MSG_TYPE=USER_DEFINE_MSG, PARTITION_NAME=fooBar_OFFLINE, RESOURCE_NAME=brokerResource, RETRY_COUNT=0, SRC_CLUSTER=pinot, SRC_INSTANCE_TYPE=PARTICIPANT, SRC_NAME=Controller_hostname.domain,com_9000, TGT_NAME=Broker_hostname,domain.com_6998, TGT_SESSION_ID=f6e19a457b80db5, TIMEOUT=-1, segmentName=fooBar_559, tableName=fooBar_OFFLINE}{}{}
java.lang.UnsupportedOperationException: Unsupported user defined message sub type: REFRESH_SEGMENT
at org.apache.pinot.broker.broker.helix.TimeboundaryRefreshMessageHandlerFactory.createHandler(TimeboundaryRefreshMessageHandlerFactory.java:68) ~[pinot-broker-0.2.1172.jar:0.3.0-SNAPSHOT-c9d88e47e02d799dc334d7dd1446a38d9ce161a3]
at org.apache.helix.messaging.handling.HelixTaskExecutor.createMessageHandler(HelixTaskExecutor.java:1096) ~[helix-core-0.9.1.509.jar:0.9.1.509]
at org.apache.helix.messaging.handling.HelixTaskExecutor.onMessage(HelixTaskExecutor.java:866) [helix-core-0.9.1.509.jar:0.9.1.509]$ cd kubernetes/helm
$ kubectl apply -f pinot-github-realtime-events.ymlexport PINOT_VERSION=latest
export PINOT_IMAGE=apachepinot/pinot:${PINOT_VERSION}
docker pull ${PINOT_IMAGE}{
"schemaName": "pullRequestMergedEvents",
"dimensionFieldSpecs": [
{
"name": "title",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "labels",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "userId",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "userType",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "authorAssociation",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "mergedBy",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "assignees",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "authors",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "committers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "requestedReviewers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "requestedTeams",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "reviewers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "commenters",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "repo",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "organization",
"dataType": "STRING",
"defaultNullValue": ""
}
],
"metricFieldSpecs": [
{
"name": "count",
"dataType": "LONG",
"defaultNullValue": 1
},
{
"name": "numComments",
"dataType": "LONG"
},
{
"name": "numReviewComments",
"dataType": "LONG"
},
{
"name": "numCommits",
"dataType": "LONG"
},
{
"name": "numLinesAdded",
"dataType": "LONG"
},
{
"name": "numLinesDeleted",
"dataType": "LONG"
},
{
"name": "numFilesChanged",
"dataType": "LONG"
},
{
"name": "numAuthors",
"dataType": "LONG"
},
{
"name": "numCommitters",
"dataType": "LONG"
},
{
"name": "numReviewers",
"dataType": "LONG"
},
{
"name": "numCommenters",
"dataType": "LONG"
},
{
"name": "createdTimeMillis",
"dataType": "LONG"
},
{
"name": "elapsedTimeMillis",
"dataType": "LONG"
}
],
"dateTimeFieldSpecs": [
{
"name": "mergedTimeMillis",
"dataType": "TIMESTAMP",
"format": "1:MILLISECONDS:TIMESTAMP",
"granularity": "1:MILLISECONDS"
}
]
}{
"tableName": "pullRequestMergedEvents",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "mergedTimeMillis",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "60",
"schemaName": "pullRequestMergedEvents",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"invertedIndexColumns": [
"organization",
"repo"
],
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "simple",
"stream.kafka.topic.name": "pullRequestMergedEvents",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "pinot-zookeeper:2181/kafka",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.time": "12h",
"realtime.segment.flush.threshold.rows": "100000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}$ docker run \
--network=pinot-demo \
--name pinot-streaming-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/stream/githubEvents/pullRequestMergedEvents_schema.json \
-tableConfigFile examples/stream/githubEvents/docker/pullRequestMergedEvents_realtime_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-exec
Executing command: AddTable -tableConfigFile examples/stream/githubEvents/docker/pullRequestMergedEvents_realtime_table_config.json -schemaFile examples/stream/githubEvents/pullRequestMergedEvents_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: 20c241022a96, version: Unknown
{"status":"Table pullRequestMergedEvents_REALTIME succesfully added"}$ docker run --rm -ti \
--network=pinot-demo \
--name pinot-github-events-into-kafka \
-d ${PINOT_IMAGE} StreamGitHubEvents \
-schemaFile examples/stream/githubEvents/pullRequestMergedEvents_schema.json \
-topic pullRequestMergedEvents \
-personalAccessToken <your_github_personal_access_token> \
-kafkaBrokerList kafka:9092$ docker run --rm -ti \
--network=pinot-demo \
--name pinot-github-events-quick-start \
${PINOT_IMAGE} GitHubEventsQuickStart \
-personalAccessToken <your_github_personal_access_token> docker exec \
-t kafka \
cd incubator-pinot/pinot-tools/target/pinot-tools-pkg
bin/pinot-admin.sh PostQuery \
-queryType sql \
-brokerPort 8000 \
-query "select count(*) from baseballStats"
2020/03/04 12:46:33.459 INFO [PostQueryCommand] [main] Executing command: PostQuery -brokerHost localhost -brokerPort 8000 -queryType sql -query select count(*) from baseballStats
2020/03/04 12:46:33.854 INFO [PostQueryCommand] [main] Result: {"resultTable":{"dataSchema":{"columnDataTypes":["LONG"],"columnNames":["count(*)"]},"rows":[[97889]]},"exceptions":[],"numServersQueried":1,"numServersResponded":1,"numSegmentsQueried":1,"numSegmentsProcessed":1,"numSegmentsMatched":1,"numConsumingSegmentsQueried":0,"numDocsScanned":97889,"numEntriesScannedInFilter":0,"numEntriesScannedPostFilter":0,"numGroupsLimitReached":false,"totalDocs":97889,"timeUsedMs":185,"segmentStatistics":[],"traceInfo":{},"minConsumingFreshnessTimeMs":0}$ curl -H "Content-Type: application/json" -X POST \
-d '{"sql":"select foo, count(*) from myTable group by foo limit 100"}' \
http://localhost:8099/query/sql$ curl -H "Content-Type: application/json" -X POST \
-
docker run \
--network=pinot-demo \
--name pinot-broker \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
-brokerPort 7000Usage: StartServer
-serverHost <String> : Host name for controller. (required=false)
-serverPort <int> : Port number to start the server at. (required=false)
-serverAdminPort <int> : Port number to serve the server admin API at. (required=false)
-dataDir <string> : Path to directory containing data. (required=false)
-segmentDir <string> : Path to directory containing segments. (required=false)
-zkAddress <http> : Http address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Broker Starter Config file. (required=false)
-help : Print this message. (required=false)docker run \
--network=pinot-demo \
--name pinot-server \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartServer \
-zkAddress localhost:2181Usage: StartServer
-serverHost <String> : Host name for controller. (required=false)
-serverPort <int> : Port number to start the server at. (required=false)
-serverAdminPort <int> : Port number to serve the server admin API at. (required=false)
-dataDir <string> : Path to directory containing data. (required=false)
-segmentDir <string> : Path to directory containing segments. (required=false)
-zkAddress <http> : Http address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Server Starter Config file. (required=false)
-help : Print this message. (required=false)select playerName, max(hits)
from baseballStats
group by playerName
order by max(hits) descselect sum(hits), sum(homeRuns), sum(numberOfGames)
from baseballStats
where yearID > 2010select *
from baseballStats
order by league






docker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type batchdocker network create -d bridge pinot-demo_defaultdocker run \
--network=pinot-demo_default \
--name manual-pinot-zookeeper \
--restart always \
-p 2181:2181 \
-d zookeeper:3.5.6docker run --rm -ti \
--network=pinot-demo_default \
--name manual-pinot-controller \
-p 9000:9000 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms1G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log" \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181docker run --rm -ti \
--network=pinot-demo_default \
--name manual-pinot-broker \
-p 8099:8099 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log" \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181docker run --rm -ti \
--network=pinot-demo_default \
--name manual-pinot-server \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log" \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181docker run --rm -ti \
--network pinot-demo_default --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9ec20e4463fa wurstmeister/kafka:latest "start-kafka.sh" 43 minutes ago Up 43 minutes kafka
0775f5d8d6bf apachepinot/pinot:latest "./bin/pinot-admin.s…" 44 minutes ago Up 44 minutes 8096-8099/tcp, 9000/tcp pinot-server
64c6392b2e04 apachepinot/pinot:latest "./bin/pinot-admin.s…" 44 minutes ago Up 44 minutes 8096-8099/tcp, 9000/tcp pinot-broker
b6d0f2bd26a3 apachepinot/pinot:latest "./bin/pinot-admin.s…" 45 minutes ago Up 45 minutes 8096-8099/tcp, 0.0.0.0:9000->9000/tcp pinot-quickstart
570416fc530e zookeeper:3.5.6 "/docker-entrypoint.…" 45 minutes ago Up 45 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp pinot-zookeeperversion: '3.7'
services:
zookeeper:
image: zookeeper:3.5.6
hostname: zookeeper
container_name: manual-zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
pinot-controller:
image: apachepinot/pinot:0.9.3
command: "StartController -zkAddress manual-zookeeper:2181"
container_name: "manual-pinot-controller"
restart: unless-stopped
ports:
- "9000:9000"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms1G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.9.3
command: "StartBroker -zkAddress manual-zookeeper:2181"
restart: unless-stopped
container_name: "manual-pinot-broker"
ports:
- "8099:8099"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.9.3
command: "StartServer -zkAddress manual-zookeeper:2181"
restart: unless-stopped
container_name: "manual-pinot-server"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log"
depends_on:
- pinot-broker
docker-compose --project-name pinot-demo updocker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ba5cb0868350 apachepinot/pinot:0.9.3 "./bin/pinot-admin.s…" About a minute ago Up About a minute 8096-8099/tcp, 9000/tcp manual-pinot-server
698f160852f9 apachepinot/pinot:0.9.3 "./bin/pinot-admin.s…" About a minute ago Up About a minute 8096-8098/tcp, 9000/tcp, 0.0.0.0:8099->8099/tcp, :::8099->8099/tcp manual-pinot-broker
b1ba8cf60d69 apachepinot/pinot:0.9.3 "./bin/pinot-admin.s…" About a minute ago Up About a minute 8096-8099/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp manual-pinot-controller
54e7e114cd53 zookeeper:3.5.6 "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, :::2181->2181/tcp, 8080/tcp manual-zookeeperstudentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "transcript",
"segmentsConfig" : {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"replication" : "1",
"schemaName" : "transcript"
},
"tableIndexConfig" : {
"invertedIndexColumns" : [],
"loadMode" : "MMAP"
},
"tenants" : {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableType":"OFFLINE",
"metadata": {}
}$ ls /tmp/pinot-quick-start
rawdata transcript-schema.json transcript-table-offline.json
$ ls /tmp/pinot-quick-start/rawdata
transcript.csvdocker run --rm -ti \
--network=pinot-demo_default \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-batch-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-offline.json \
-controllerHost manual-pinot-controller \
-controllerPort 9000 -execbin/pinot-admin.sh AddTable \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-offline.json \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json -execexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
schemaURI: 'http://manual-pinot-controller:9000/tables/transcript/schema'
tableConfigURI: 'http://manual-pinot-controller:9000/tables/transcript'
pinotClusterSpecs:
- controllerURI: 'http://manual-pinot-controller:9000'executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
schemaURI: 'http://localhost:9000/tables/transcript/schema'
tableConfigURI: 'http://localhost:9000/tables/transcript'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'docker run --rm -ti \
--network=pinot-demo_default \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-data-ingestion-job \
apachepinot/pinot:latest LaunchDataIngestionJob \
-jobSpecFile /tmp/pinot-quick-start/docker-job-spec.ymlbin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile /tmp/pinot-quick-start/batch-job-spec.ymlSegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**\/*.csv
inputDirURI: /tmp/pinot-quick-start/rawdata/
jobType: SegmentCreationAndTarPush
outputDirURI: /tmp/pinot-quick-start/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://localhost:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
pushJobSpec: null
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.csv.CSVRecordReader,
configClassName: org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig,
configs: null, dataFormat: csv}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://localhost:9000/tables/transcript/schema', tableConfigURI: 'http://localhost:9000/tables/transcript',
tableName: transcript}
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Finished building StatsCollector!
Collected stats for 4 documents
Using fixed bytes value dictionary for column: studentID, size: 9
Created dictionary for STRING column: studentID with cardinality: 3, max length in bytes: 3, range: 200 to 202
Using fixed bytes value dictionary for column: firstName, size: 12
Created dictionary for STRING column: firstName with cardinality: 3, max length in bytes: 4, range: Bob to Nick
Using fixed bytes value dictionary for column: lastName, size: 15
Created dictionary for STRING column: lastName with cardinality: 3, max length in bytes: 5, range: King to Young
Created dictionary for FLOAT column: score with cardinality: 4, range: 3.2 to 3.8
Using fixed bytes value dictionary for column: gender, size: 12
Created dictionary for STRING column: gender with cardinality: 2, max length in bytes: 6, range: Female to Male
Using fixed bytes value dictionary for column: subject, size: 21
Created dictionary for STRING column: subject with cardinality: 3, max length in bytes: 7, range: English to Physics
Created dictionary for LONG column: timestampInEpoch with cardinality: 4, range: 1570863600000 to 1572418800000
Start building IndexCreator!
Finished records indexing in IndexCreator!
Finished segment seal!
Converting segment: /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0 to v3 format
v3 segment location for segment: transcript_OFFLINE_1570863600000_1572418800000_0 is /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3
Deleting files in v1 segment directory: /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0
Starting building 1 star-trees with configs: [StarTreeV2BuilderConfig[splitOrder=[studentID, firstName],skipStarNodeCreation=[],functionColumnPairs=[org.apache.pinot.core.startree.v2.AggregationFunctionColumnPair@3a48efdc],maxLeafRecords=1]] using OFF_HEAP builder
Starting building star-tree with config: StarTreeV2BuilderConfig[splitOrder=[studentID, firstName],skipStarNodeCreation=[],functionColumnPairs=[org.apache.pinot.core.startree.v2.AggregationFunctionColumnPair@3a48efdc],maxLeafRecords=1]
Generated 3 star-tree records from 4 segment records
Finished constructing star-tree, got 9 tree nodes and 4 records under star-node
Finished creating aggregated documents, got 6 aggregated records
Finished building star-tree in 10ms
Finished building 1 star-trees in 27ms
Computed crc = 3454627653, based on files [/var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3/columns.psf, /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3/index_map, /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3/metadata.properties, /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3/star_tree_index, /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0/v3/star_tree_index_map]
Driver, record read time : 0
Driver, stats collector time : 0
Driver, indexing time : 0
Tarring segment from: /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0 to: /var/folders/3z/qn6k60qs6ps1bb6s2c26gx040000gn/T/pinot-1583443148720/output/transcript_OFFLINE_1570863600000_1572418800000_0.tar.gz
Size for segment: transcript_OFFLINE_1570863600000_1572418800000_0, uncompressed: 6.73KB, compressed: 1.89KB
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Start pushing segments: [/tmp/pinot-quick-start/segments/transcript_OFFLINE_1570863600000_1572418800000_0.tar.gz]... to locations: [org.apache.pinot.spi.ingestion.batch.spec.PinotClusterSpec@243c4f91] for table transcript
Pushing segment: transcript_OFFLINE_1570863600000_1572418800000_0 to location: http://localhost:9000 for table transcript
Sending request: http://localhost:9000/v2/segments?tableName=transcript to controller: nehas-mbp.hsd1.ca.comcast.net, version: Unknown
Response for pushing table transcript segment transcript_OFFLINE_1570863600000_1572418800000_0 to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: transcript_OFFLINE_1570863600000_1572418800000_0 of table: transcript"}{
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "50M",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}docker run \
--network=pinot-demo_default \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost manual-pinot-controller \
-controllerPort 9000 \
-execbin/pinot-admin.sh AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-exec{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestampInEpoch":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestampInEpoch":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestampInEpoch":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestampInEpoch":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestampInEpoch":1572854400000}bin/kafka-console-producer.sh \
--broker-list localhost:9876 \
--topic transcript-topic < /tmp/pinot-quick-start/rawData/transcript.jsondocker run \
--network pinot-demo_default --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=manual-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper manual-zookeeper:2181/kafka \
--partitions=1 --replication-factor=1 \
--create --topic transcript-topicbin/pinot-admin.sh StartKafka -zkAddress=localhost:2123/kafka -port 9876bin/kafka-topics.sh --create --bootstrap-server localhost:9876 --replication-factor 1 --partitions 1 --topic transcript-topicallowVolumeExpansion: truekubectl edit pvc data-pinot-server-3 -n pinot{
"schemaName": "baseballStats",
"dimensionFieldSpecs": [
{
"name": "playerID",
"dataType": "STRING"
},
{
"name": "yearID",
"dataType": "INT"
},
{
"name": "teamID",
"dataType": "STRING"
},
{
"name": "league",
"dataType": "STRING"
},
{
"name": "playerName",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "playerStint",
"dataType": "INT"
},
{
"name": "numberOfGames",
"dataType": "INT"
},
{
"name": "numberOfGamesAsBatter",
"dataType": "INT"
},
{
"name": "AtBatting",
"dataType": "INT"
},
{
"name": "runs",
"dataType": "INT"
},
{
"name": "hits",
"dataType": "INT"
},
{
"name": "doules",
"dataType": "INT"
},
{
"name": "tripples",
"dataType": "INT"
},
{
"name": "homeRuns",
"dataType": "INT"
},
{
"name": "runsBattedIn",
"dataType": "INT"
},
{
"name": "stolenBases",
"dataType": "INT"
},
{
"name": "caughtStealing",
"dataType": "INT"
},
{
"name": "baseOnBalls",
"dataType": "INT"
},
{
"name": "strikeouts",
"dataType": "INT"
},
{
"name": "intentionalWalks",
"dataType": "INT"
},
{
"name": "hitsByPitch",
"dataType": "INT"
},
{
"name": "sacrificeHits",
"dataType": "INT"
},
{
"name": "sacrificeFlies",
"dataType": "INT"
},
{
"name": "groundedIntoDoublePlays",
"dataType": "INT"
},
{
"name": "G_old",
"dataType": "INT"
}
]
}org.apache.pinot.plugin.inputformat.avro.SimpleAvroMessageDecoderorg.apache.pinot.plugin.stream.kinesis.KinesisConsumerFactory/tasks/cleanuptasks/{taskType} -> /tasks/{taskType}/cleanup






$ bin/kafka-topics.sh \
--create \
--bootstrap-server localhost:19092 \
--replication-factor 1 \
--partitions 1 \
--topic pullRequestMergedEvents{
"schemaName": "pullRequestMergedEvents",
"dimensionFieldSpecs": [
{
"name": "title",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "labels",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "userId",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "userType",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "authorAssociation",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "mergedBy",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "assignees",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "authors",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "committers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "requestedReviewers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "requestedTeams",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "reviewers",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "commenters",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": ""
},
{
"name": "repo",
"dataType": "STRING",
"defaultNullValue": ""
},
{
"name": "organization",
"dataType": "STRING",
"defaultNullValue": ""
}
],
"metricFieldSpecs": [
{
"name": "count",
"dataType": "LONG",
"defaultNullValue": 1
},
{
"name": "numComments",
"dataType": "LONG"
},
{
"name": "numReviewComments",
"dataType": "LONG"
},
{
"name": "numCommits",
"dataType": "LONG"
},
{
"name": "numLinesAdded",
"dataType": "LONG"
},
{
"name": "numLinesDeleted",
"dataType": "LONG"
},
{
"name": "numFilesChanged",
"dataType": "LONG"
},
{
"name": "numAuthors",
"dataType": "LONG"
},
{
"name": "numCommitters",
"dataType": "LONG"
},
{
"name": "numReviewers",
"dataType": "LONG"
},
{
"name": "numCommenters",
"dataType": "LONG"
},
{
"name": "createdTimeMillis",
"dataType": "LONG"
},
{
"name": "elapsedTimeMillis",
"dataType": "LONG"
}
],
"timeFieldSpec": {
"incomingGranularitySpec": {
"timeType": "MILLISECONDS",
"timeFormat": "EPOCH",
"dataType": "LONG",
"name": "mergedTimeMillis"
}
}
}{
"tableName": "pullRequestMergedEvents",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "mergedTimeMillis",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "60",
"schemaName": "pullRequestMergedEvents",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"invertedIndexColumns": [
"organization",
"repo"
],
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "simple",
"stream.kafka.topic.name": "pullRequestMergedEvents",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:19092",
"realtime.segment.flush.threshold.time": "12h",
"realtime.segment.flush.threshold.rows": "100000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}
$ bin/pinot-admin.sh AddTable \
-tableConfigFile $PATH_TO_CONFIGS/examples/stream/githubEvents/pullRequestMergedEvents_realtime_table_config.json \
-schemaFile $PATH_TO_CONFIGS/examples/stream/githubEvents/pullRequestMergedEvents_schema.json \
-exec$ bin/pinot-admin.sh StreamGitHubEvents \
-topic pullRequestMergedEvents \
-personalAccessToken <your_github_personal_access_token> \
-kafkaBrokerList localhost:19092 \
-schemaFile $PATH_TO_CONFIGS/examples/stream/githubEvents/pullRequestMergedEvents_schema.json$ bin/pinot-admin.sh GitHubEventsQuickStart \
-personalAccessToken <your_github_personal_access_token>kubectl apply -f helm-rbac.yamlhelm init --service-account tillerhelm install --namespace "pinot-quickstart" --name "pinot" pinotkubectl create ns pinot-quickstart
helm install -n pinot-quickstart pinot pinotError: could not find tiller.kubectl -n kube-system delete deployment tiller-deploy
kubectl -n kube-system delete service/tiller-deploy
helm init --service-account tiller