

Architecture
Understand how the components of Apache Pinot™ work together to create a scalable OLAP database that can deliver low-latency, high-concurrency queries at scale.
We recommend that you read Basic Concepts to better understand the terms used in this guide.
Apache Pinot™ is a distributed OLAP database designed to serve real-time, user-facing use cases, which means handling large volumes of data and many concurrent queries with very low query latencies. Pinot supports the following requirements:
Ultra low-latency queries (as low as 10ms P95)
High query concurrency (as many as 100,000 queries per second)
High data freshness (streaming data available for query immediately upon ingestion)
Large data volume (up to petabytes)
Distributed design principles
To accommodate large data volumes with stringent latency and concurrency requirements, Pinot is designed as a distributed database that supports the following requirements:
Highly available: Pinot has no single point of failure. When tables are configured for replication, and a node goes down, the cluster is able to continue processing queries.
Immutable data: Pinot assumes all stored data is immutable, which helps simplify the parts of the system that handle data storage and replication. However, Pinot still supports upserts on streaming entity data and background purges of data to comply with data privacy regulations.
Dynamic configuration changes: Operations like adding new tables, expanding a cluster, ingesting data, modifying an existing table, and adding indexes do not impact query availability or performance.
Core components
As described in Apache Pinot™ Concepts, Pinot has four node types:

Apache Helix and ZooKeeper
Distributed systems do not maintain themselves, and in fact require sophisticated scheduling and resource management to function. Pinot uses Apache Helix for this purpose. Helix exists as an independent project, but it was designed by the original creators of Pinot for Pinot's own cluster management purposes, so the architectures of the two systems are well-aligned. Helix takes the form of a process on the controller, plus embedded agents on the brokers and servers. It uses Apache ZooKeeper as a fault-tolerant, strongly consistent, durable state store.
Helix maintains a picture of the intended state of the cluster, including the number of servers and brokers, the configuration and schema of all tables, connections to streaming ingest sources, currently executing batch ingestion jobs, the assignment of table segments to the servers in the cluster, and more. All of these configuration items are potentially mutable quantities, since operators routinely change table schemas, add or remove streaming ingest sources, begin new batch ingestion jobs, and so on. Additionally, physical cluster state may change as servers and brokers fail or suffer network partition. Helix works constantly to drive the actual state of the cluster to match the intended state, pushing configuration changes to brokers and servers as needed.
There are three physical node types in a Helix cluster:
Participant: These nodes do things, like store data or perform computation. Participants host resources, which are Helix's fundamental storage abstraction. Because Pinot servers store segment data, they are participants.
Spectator: These nodes see things, observing the evolving state of the participants through events pushed to the spectator. Because Pinot brokers need to know which servers host which segments, they are spectators.
Controller: This node observes and manages the state of participant nodes. The controller is responsible for coordinating all state transitions in the cluster and ensures that state constraints are satisfied while maintaining cluster stability.
In addition, Helix defines two logical components to express its storage abstraction:
Partition. A unit of data storage that lives on at least one participant. Partitions may be replicated across multiple participants. A Pinot segment is a partition.
Resource. A logical collection of partitions, providing a single view over a potentially large set of data stored across a distributed system. A Pinot table is a resource.
In summary, the Pinot architecture maps onto Helix components as follows:
Segment
Helix Partition
Table
Helix Resource
Controller
Helix Controller or Helix agent that drives the overall state of the cluster
Server
Helix Participant
Broker
A Helix Spectator that observes the cluster for changes in the state of segments and servers. To support multi-tenancy, brokers are also modeled as Helix Participants.
Minion
Helix Participant that performs computation rather than storing data
Helix uses ZooKeeper to maintain cluster state. ZooKeeper sends Helix spectators notifications of changes in cluster state (which correspond to changes in ZNodes). Zookeeper stores the following information about the cluster:
Controller
Controller that is assigned as the current leader
Servers and Brokers
List of servers and brokers
Configuration of all current servers and brokers
Health status of all current servers and brokers
Tables
List of tables
Table configurations
Table schema
List of the table's segments
Segment
Exact server locations of a segment
State of each segment (online/offline/error/consuming)
Metadata about each segment
Zookeeper, as a first-class citizen of a Pinot cluster, may use the well-known ZNode structure for operations and troubleshooting purposes. Be advised that this structure can change in future Pinot releases.
Controller
The Pinot controller schedules and re-schedules resources in a Pinot cluster when metadata changes or a node fails. As an Apache Helix Controller, it schedules the resources that comprise the cluster and orchestrates connections between certain external processes and cluster components (e.g., ingest of real-time tables and offline tables). It can be deployed as a single process on its own server or as a group of redundant servers in an active/passive configuration.
Fault tolerance
Only one controller can be active at a time, so when multiple controllers are present in a cluster, they elect a leader. When that controller instance becomes unavailable, the remaining instances automatically elect a new leader. Leader election is achieved using Apache Helix. A Pinot cluster can serve queries without an active controller, but it can't perform any metadata-modifying operations, like adding a table or consuming a new segment.
Controller REST interface
The controller provides a REST interface that allows read and write access to all logical storage resources (e.g., servers, brokers, tables, and segments). See Pinot Data Explorer for more information on the web-based admin tool.
Broker
The broker's responsibility is to route queries to the appropriate server instances, or in the case of multi-stage queries, to compute a complete query plan and distribute it to the servers required to execute it. The broker collects and merges the responses from all servers into a final result, then sends the result back to the requesting client. The broker exposes an HTTP endpoint that accepts SQL queries in JSON format and returns the response in JSON.
Each broker maintains a query routing table. The routing table maps segments to the servers that store them. (When replication is configured on a table, each segment is stored on more than one server.) The broker computes multiple routing tables depending on the configured routing strategy for a table. The default strategy is to balance the query load across all available servers.
Advanced routing strategies are available, such as replica-aware routing, partition-based routing, and minimal server selection routing.
Query processing
Every query processed by a broker uses the single-stage engine or the multi-stage engine. For single-stage queries, the broker does the following:
Computes query routes based on the routing strategy defined in the table configuration.
Sends the query to each of those servers for local execution against their segments.
Receives the results from each server and merges them.
Sends the query result to the client.
For multi-stage queries, the broker performs the following:
Computes a query plan that runs on multiple sets of servers. The servers selected for the first stage are selected based on the segments required to execute the query, which are determined in a process similar to single-stage queries.
Sends the relevant portions of the query plan to one or more servers in the cluster for each stage of the query plan.
The servers that received query plans each execute their part of the query. For more details on this process, read about the multi-stage engine.
The broker receives a complete result set from the final stage of the query, which is always a single server.
The broker sends the query result to the client.
Server
Servers host segments on locally attached storage and process queries on those segments. By convention, operators speak of "real-time" and "offline" servers, although there is no difference in the server process itself or even its configuration that distinguishes between the two. This is merely a convention reflected in the table assignment strategy to confine the two different kinds of workloads to two groups of physical instances, since the performance-limiting factors differ between the two kinds of workloads. For example, offline servers might optimize for larger storage capacity, whereas real-time servers might optimize for memory and CPU cores.
Offline servers
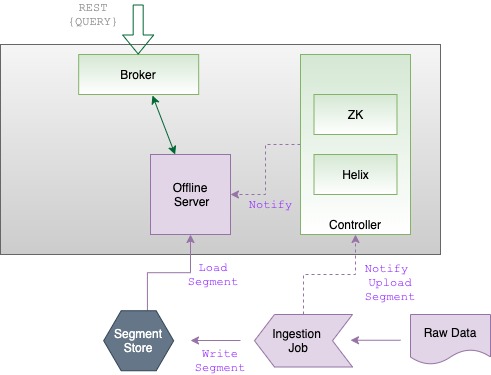
Offline servers host segments created by ingesting batch data. The controller writes these segments to the offline server according to the table's replication factor and segment assignment strategy. Typically, the controller writes new segments to the deep store, and affected servers download the segment from deep store. The controller then notifies brokers that a new segment exists, and is available to participate in queries.
Because offline tables tend to have long retention periods, offline servers tend to scale based on the size of the data they store.
Real-time servers
Real-time servers ingest data from streaming sources, like Apache Kafka®, Apache Pulsar®, or AWS Kinesis. Streaming data ends up in conventional segment files just like batch data, but is first accumulated in an in-memory data structure known as a consuming segment. Each message consumed from a streaming source is written immediately to the relevant consuming segment, and is available for query processing from the consuming segment immediately, since consuming segments participate in query processing as first-class citizens. Consuming segments get flushed to disk periodically based on a completion threshold, which can be calculated by row count, ingestion time, or segment size. A flushed segment on a real-time table is called a completed segment, and is functionally equivalent to a segment created during offline ingest.
Real-time servers tend to be scaled based on the rate at which they ingest streaming data.

Minion
A Pinot minion is an optional cluster component that executes background tasks on table data apart from the query processes performed by brokers and servers. Minions run on independent hardware resources, and are responsible for executing minion tasks as directed by the controller. Examples of minion tasks include converting batch data from a standard format like Avro or JSON into segment files to be loaded into an offline table, and rewriting existing segment files to purge records as required by data privacy laws like GDPR. Minion tasks can run once or be scheduled to run periodically.
Minions isolate the computational burden of out-of-band data processing from the servers. Although a Pinot cluster can function without minions, they are typically present to support routine tasks like ingesting batch data.
Data ingestion overview
Pinot tables exist in two varieties: offline (or batch) and real-time. Offline tables contain data from batch sources like CSV, Avro, or Parquet files, and real-time tables contain data from streaming sources like like Apache Kafka®, Apache Pulsar®, or AWS Kinesis.
Offline (batch) ingest
Pinot ingests batch data using an ingestion job, which follows a process like this:
The job transforms a raw data source (such as a CSV file) into segments. This is a potentially complex process resulting in a file that is typically several hundred megabytes in size.
The job then transfers the file to the cluster's deep store and notifies the controller that a new segment exists.
The controller (in its capacity as a Helix controller) updates the ideal state of the cluster in its cluster metadata map.
The controller then assigns the segment to one or more "offline" servers (depending on replication factor) and notifies them that new segments are available.
The servers then download the newly created segments directly from the deep store.
The cluster's brokers, which watch for state changes as Helix spectators, detect the new segments and update their segment routing tables accordingly. The cluster is now able to query the new offline segments.
Real-time ingest
Ingestion is established at the time a real-time table is created, and continues as long as the table exists. When the controller receives the metadata update to create a new real-time table, the table configuration specifies the source of the streaming input data—often a topic in a Kafka cluster. This kicks off a process like this:
The controller picks one or more servers to act as direct consumers of the streaming input source.
The controller creates consuming segments for the new table. It does this by creating an entry in the global metadata map for a new consuming segment for each of the real-time servers selected in step 1.
Through Helix functionality on the controller and the relevant servers, the servers proceed to create consuming segments in memory and establish a connection to the streaming input source. When this input source is Kafka, each server acts as a Kafka consumer directly, with no other components involved in the integration.
Through Helix functionality on the controller and all of the cluster's brokers, the brokers become aware of the consuming segments, and begin including them in query routing immediately.
The consuming servers simultaneously begin consuming messages from the streaming input source, storing them in the consuming segment.
When a server decides its consuming segment is complete, it commits the in-memory consuming segment to a conventional segment file, uploads it to the deep store, and notifies the controller.
The controller and the server create a new consuming segment to continue real-time ingestion.
The controller marks the newly committed segment as online. Brokers then discover the new segment through the Helix notification mechanism, allowing them to route queries to it in the usual fashion.
Was this helpful?