Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Batch ingestion of data into Apache Pinot using dimension tables.
isDimTable: Set to true.POST /segments/{tableName}/reloadPOST /segments/{tableName}/{segmentName}/reload{
"status": "200"
}SET taskName = 'myTask-s3';
SET input.fs.className = 'org.apache.pinot.plugin.filesystem.S3PinotFS';
SET input.fs.prop.accessKey = 'my-key';
SET input.fs.prop.secretKey = 'my-secret';
SET input.fs.prop.region = 'us-west-2';
INSERT INTO "baseballStats"
FROM FILE 's3://my-bucket/public_data_set/baseballStats/rawdata/'{
"OFFLINE": {
"tableName": "dimBaseballTeams_OFFLINE",
"tableType": "OFFLINE",
"segmentsConfig": {
"schemaName": "dimBaseballTeams",
"segmentPushType": "REFRESH"
},
"metadata": {},
"quota": {
"storage": "200M"
},
"isDimTable": true
}.
"dimensionTableConfig": {
"disablePreload": true
}
}
}
...
{
"dimensionFieldSpecs": [
{
"dataType": "STRING",
"name": "teamID"
},
{
"dataType": "STRING",
"name": "teamName"
}
],
"schemaName": "dimBaseballTeams",
"primaryKeyColumns": ["teamID"]
}Storing records with dynamic schemas in a table with a fixed schema.
This guide shows you how to import data from GCP (Google Cloud Platform).
This guide shows you how to import data from files stored in Azure Data Lake Storage Gen2 (ADLS Gen2)
This section contains a collection of short guides to show you how to import data from a Pinot-supported file system.
{
"timestamp": 1687786535928,
"hostname": "host1",
"HOSTNAME": "host1",
"level": "INFO",
"message": "Started processing job1",
"tags": {
"platform": "data",
"service": "serializer",
"params": {
"queueLength": 5,
"timeout": 299,
"userData_noIndex": {
"nth": 99
}
}
}
}{
"timestamp": 1687786535928,
"hostname": "host1",
"level": "INFO",
"message": "Started processing job1",
"tags.platform": "data",
"tags.service": "serializer",
"indexableExtras": {
"tags": {
"params": {
"queueLength": 5,
"timeout": 299
}
}
},
"unindexableExtras": {
"tags": {
"userData_noIndex": {
"nth": 99
}
}
}
}{
"ingestionConfig": {
"schemaConformingTransformerConfig": {
"indexableExtrasField": "extras",
"unindexableExtrasField": "extrasNoIndex",
"unindexableFieldSuffix": "_no_index",
"fieldPathsToDrop": [
"HOSTNAME"
]
}
}
}-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-gcspinot.controller.storage.factory.class.gs.projectId=test-projectexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'gs://my-bucket/path/to/input/directory/'
outputDirURI: 'gs://my-bucket/path/to/output/directory/'
overwriteOutput: true
pinotFSSpecs:
- scheme: gs
className: org.apache.pinot.plugin.filesystem.GcsPinotFS
configs:
projectId: 'my-project'
gcpKey: 'path-to-gcp json key file'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=gs://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.controller.storage.factory.gs.projectId=my-project
pinot.controller.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.controller.segment.fetcher.protocols=file,http,gs
pinot.controller.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.server.storage.factory.gs.projectId=my-project
pinot.server.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.server.segment.fetcher.protocols=file,http,gs
pinot.server.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.minion.storage.factory.class.gs=org.apache.pinot.plugin.filesystem.GcsPinotFS
pinot.minion.storage.factory.gs.projectId=my-project
pinot.minion.storage.factory.gs.gcpKey=path/to/gcp/key.json
pinot.minion.segment.fetcher.protocols=file,http,gs
pinot.minion.segment.fetcher.gs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-adlspinot.controller.storage.factory.class.adl2.accountName=test-userexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'adl2://path/to/input/directory/'
outputDirURI: 'adl2://path/to/output/directory/'
overwriteOutput: true
pinotFSSpecs:
- scheme: adl2
className: org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
configs:
accountName: 'my-account'
accessKey: 'foo-bar-1234'
fileSystemName: 'fs-name'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=adl2://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
pinot.controller.storage.factory.adl2.accountName=my-account
pinot.controller.storage.factory.adl2.accessKey=foo-bar-1234
pinot.controller.storage.factory.adl2.fileSystemName=fs-name
pinot.controller.segment.fetcher.protocols=file,http,adl2
pinot.controller.segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
pinot.server.storage.factory.adl2.accountName=my-account
pinot.server.storage.factory.adl2.accessKey=foo-bar-1234
pinot.server.storage.factory.adl2.fileSystemName=fs-name
pinot.server.segment.fetcher.protocols=file,http,adl2
pinot.server.segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherstorage.factory.class.adl2=org.apache.pinot.plugin.filesystem.ADLSGen2PinotFS
storage.factory.adl2.accountName=my-account
storage.factory.adl2.fileSystemName=fs-name
storage.factory.adl2.accessKey=foo-bar-1234
segment.fetcher.protocols=file,http,adl2
segment.fetcher.adl2.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherSupport for encoding fields with CLP during ingestion.
Upload a table segment in Apache Pinot.
-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-plugin-to-include-1,pinot-plugin-to-include-2#CONTROLLER
pinot.controller.storage.factory.class.[scheme]=className of the pinot file system
pinot.controller.segment.fetcher.protocols=file,http,[scheme]
pinot.controller.segment.fetcher.[scheme].class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher#SERVER
pinot.server.storage.factory.class.[scheme]=className of the Pinot file system
pinot.server.segment.fetcher.protocols=file,http,[scheme]
pinot.server.segment.fetcher.[scheme].class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinotFSSpecs
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS{
"tableName": "kinesisTable",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kinesis",
"stream.kinesis.topic.name": "<your kinesis stream name>",
"region": "<your region>",
"accessKey": "<your access key>",
"secretKey": "<your secret key>",
"shardIteratorType": "AFTER_SEQUENCE_NUMBER",
"stream.kinesis.consumer.type": "lowlevel",
"stream.kinesis.fetch.timeout.millis": "30000",
"stream.kinesis.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kinesis.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kinesis.KinesisConsumerFactory",
"realtime.segment.flush.threshold.rows": "1000000",
"realtime.segment.flush.threshold.time": "6h"
}
},
"metadata": {
"customConfigs": {}
}
}-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-hdfshadoop.kerberos.principle"invertedIndexColumns": ["uuid"]{
"tableName": "events",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "events",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"invertedIndexColumns": ["uuid"],
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "events",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "50M",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}curl -X GET "http://localhost:9000/segments/events/metadata?columns=uuid" \
-H "accept: application/json" 2>/dev/null |
jq '.[] | [.segmentName, .indexes]'[
"events__0__1__20220214T1106Z",
{
"uuid": {
"bloom-filter": "NO",
"dictionary": "YES",
"forward-index": "YES",
"inverted-index": "YES",
"null-value-vector-reader": "NO",
"range-index": "NO",
"json-index": "NO"
}
}
]
[
"events__0__0__20220214T1053Z",
{
"uuid": {
"bloom-filter": "NO",
"dictionary": "YES",
"forward-index": "YES",
"inverted-index": "YES",
"null-value-vector-reader": "NO",
"range-index": "NO",
"json-index": "NO"
}
}
]SELECT *
FROM events
WHERE uuid = 'f4a4f'
LIMIT 10export HADOOP_HOME=/local/hadoop/
export HADOOP_VERSION=2.7.1
export HADOOP_GUAVA_VERSION=11.0.2
export HADOOP_GSON_VERSION=2.2.4
export CLASSPATH_PREFIX="${HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-annotations-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/hadoop-auth-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/hadoop-common-${HADOOP_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/guava-${HADOOP_GUAVA_VERSION}.jar:${HADOOP_HOME}/share/hadoop/common/lib/gson-${HADOOP_GSON_VERSION}.jar"curl -X POST -H "UPLOAD_TYPE:URI" -H "DOWNLOAD_URI:hdfs://nameservice1/hadoop/path/to/segment/file.executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'hdfs:///path/to/input/directory/'
outputDirURI: 'hdfs:///path/to/output/directory/'
includeFileNamePath: 'glob:**/*.csv'
overwriteOutput: true
pinotFSSpecs:
- scheme: hdfs
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
hadoop.conf.path: 'path/to/conf/directory/'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'executionFrameworkSpec:
name: 'hadoop'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentUriPushJobRunner'
extraConfigs:
stagingDir: 'hdfs:///path/to/staging/directory/'
jobType: SegmentCreationAndTarPush
inputDirURI: 'hdfs:///path/to/input/directory/'
outputDirURI: 'hdfs:///path/to/output/directory/'
includeFileNamePath: 'glob:**/*.csv'
overwriteOutput: true
pinotFSSpecs:
- scheme: hdfs
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
hadoop.conf.path: '/etc/hadoop/conf/'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=hdfs://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.controller.storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory/
pinot.controller.segment.fetcher.protocols=file,http,hdfs
pinot.controller.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.controller.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>pinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.server.storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory/
pinot.server.segment.fetcher.protocols=file,http,hdfs
pinot.server.segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
pinot.server.segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>storage.factory.class.hdfs=org.apache.pinot.plugin.filesystem.HadoopPinotFS
storage.factory.hdfs.hadoop.conf.path=path/to/conf/directory
segment.fetcher.protocols=file,http,hdfs
segment.fetcher.hdfs.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher
segment.fetcher.hdfs.hadoop.kerberos.principle=<your kerberos principal>
segment.fetcher.hdfs.hadoop.kerberos.keytab=<your kerberos keytab>// some environmental setup
StreamExecutionEnvironment execEnv = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Row> srcRows = execEnv.addSource(new FlinkKafkaConsumer<Row>(...));
RowTypeInfo typeInfo = new RowTypeInfo(
new TypeInformation[]{Types.FLOAT, Types.FLOAT, Types.STRING, Types.STRING},
new String[]{"lon", "lat", "address", "name"});
// add processing logic for the data stream for example:
DataStream<Row> processedRows = srcRow.keyBy(r -> r.getField(0));
...
// configurations for PinotSinkFunction
Schema pinotSchema = ...
TableConfig pinotTableConfig = ...
processedRows.addSink(new PinotSinkFunction<>(
new FlinkRowGenericRowConverter(typeInfo),
pinotTableConfig,
pinotSchema);
// execute the program
execEnv.execute();{
"tableName" : "tbl_OFFLINE",
"tableType" : "OFFLINE",
"segmentsConfig" : {
// ...
},
"tenants" : {
// ...
},
"tableIndexConfig" : {
// ....
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "HOURLY",
"batchConfigMaps": [
{
"outputDirURI": "file://path/to/flink/segmentwriter/output/dir",
"overwriteOutput": "false",
"push.controllerUri": "https://target.pinot.cluster.controller.url"
}
]
}
}
}
{
"primaryKeyColumns": ["id"]
}{
"routing": {
"instanceSelectorType": "strictReplicaGroup"
}
}{
...
"dedupConfig": {
"dedupEnabled": true,
"hashFunction": "NONE"
},
...
}# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'hadoop'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentUriPushJobRunner'
# segmentMetadataPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentMetadataPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: your/local/dir/stagingexport PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=${PINOT_ROOT_DIR}/build/
export HADOOP_CLIENT_OPTS="-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml"
hadoop jar \\
${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \\
org.apache.pinot.tools.admin.PinotAdministrator \\
LaunchDataIngestionJob \\
-jobSpecFile ${PINOT_DISTRIBUTION_DIR}/examples/batch/airlineStats/hadoopIngestionJobSpec.yamlenable.preprocessing = true
preprocess.path.to.output = <output_path>{
"OFFLINE": {
"metadata": {
"customConfigs": {
“preprocessing.operations”: “resize, partition, sort”, // To enable the following preprocessing operations
"preprocessing.max.num.records.per.file": "100", // To enable resizing
"preprocessing.num.reducers": "3" // To enable resizing
}
},
...
"tableIndexConfig": {
"aggregateMetrics": false,
"autoGeneratedInvertedIndex": false,
"bloomFilterColumns": [],
"createInvertedIndexDuringSegmentGeneration": false,
"invertedIndexColumns": [],
"loadMode": "MMAP",
"nullHandlingEnabled": false,
"segmentPartitionConfig": { // To enable partitioning
"columnPartitionMap": {
"item": {
"functionName": "murmur",
"numPartitions": 4
}
}
},
"sortedColumn": [ // To enable sorting
"actorId"
],
"streamConfigs": {}
},
"tableName": "tableName_OFFLINE",
"tableType": "OFFLINE",
"tenants": {
...
}
}
}{
"timestamp": 1672531200000,
"message": "INFO Task task_12 assigned to container: [ContainerID:container_15], operation took 0.335 seconds. 8 tasks remaining.",
"logPath": "/mnt/data/application_123/container_15/stdout"
}{
"timestamp": 1672531200000,
"message_logtype": "INFO Task \\x12 assigned to container: [ContainerID:\\x12], operation took \\x13 seconds. \\x11 tasks remaining.",
"message_dictionaryVars": [
"task_12",
"container_15"
],
"message_encodedVars": [
1801439850948198735,
8
],
"logPath_logtype": "/mnt/data/\\x12/\\x12/stdout",
"logPath_dictionaryVars": [
"application_123",
"container_15"
],
"logPath_encodedVars": []
}{
"tableIndexConfig": {
"streamConfigs": {
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.clplog.CLPLogMessageDecoder",
"stream.kafka.decoder.prop.fieldsForClpEncoding": "message,logPath"
},
"varLengthDictionaryColumns": [
"message_logtype",
"message_dictionaryVars",
"logPath_logtype",
"logPath_dictionaryVars"
]
}
}{
"dimensionFieldSpecs": [
{
"name": "message_logtype",
"dataType": "STRING",
"maxLength": 2147483647
},
{
"name": "message_encodedVars",
"dataType": "LONG",
"singleValueField": false
},
{
"name": "message_dictionaryVars",
"dataType": "STRING",
"maxLength": 2147483647,
"singleValueField": false
},
{
"name": "message_logtype",
"dataType": "STRING",
"maxLength": 2147483647
},
{
"name": "message_encodedVars",
"dataType": "LONG",
"singleValueField": false
},
{
"name": "message_dictionaryVars",
"dataType": "STRING",
"maxLength": 2147483647,
"singleValueField": false
}
]
}pinot-admin.sh AddTable \\
-tableConfigFile /path/to/table-config.json \\
-schemaFile /path/to/table-schema.json -execpinot-admin.sh UploadSegment \\
-controllerHost localhost \\
-controllerPort 9000 \\
-segmentDir /path/to/local/dir \\
-tableName myTablepinot-admin.sh LaunchDataIngestionJob \\
-jobSpecFile /file/location/my-job-spec.yamlpinot-admin.sh LaunchDataIngestionJob \\
-jobSpecFile /file/location/my-job-spec.yamlBatch ingestion of data into Apache Pinot using Apache Spark.
"task": {
"taskTypeConfigsMap": {
"UpsertCompactionTask": {
"schedule": "0 */5 * ? * *",
"bufferTimePeriod": "7d",
"invalidRecordsThresholdPercent": "30",
"invalidRecordsThresholdCount": "100000",
"tableMaxNumTasks": "100",
"validDocIdsType": "SNAPSHOT"
}
}
}-Dplugins.dir=/opt/pinot/plugins -Dplugins.include=pinot-s3pinot.controller.storage.factory.s3.region=ap-southeast-1executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 's3://pinot-bucket/pinot-ingestion/batch-input/'
outputDirURI: 's3://pinot-bucket/pinot-ingestion/batch-output/'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'ap-southeast-1'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'controller.data.dir=s3://path/to/data/directory/
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=ap-southeast-1
pinot.controller.segment.fetcher.protocols=file,http,s3
pinot.controller.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.server.storage.factory.s3.region=ap-southeast-1
pinot.server.storage.factory.s3.httpclient.maxConnections=50
pinot.server.storage.factory.s3.httpclient.socketTimeout=30s
pinot.server.storage.factory.s3.httpclient.connectionTimeout=2s
pinot.server.storage.factory.s3.httpclient.connectionTimeToLive=0s
pinot.server.storage.factory.s3.httpclient.connectionAcquisitionTimeout=10s
pinot.server.segment.fetcher.protocols=file,http,s3
pinot.server.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.minion.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.minion.storage.factory.s3.region=ap-southeast-1
pinot.minion.segment.fetcher.protocols=file,http,s3
pinot.minion.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcher# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'spark'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner'
#segmentMetadataPushJobRunnerClassName: class name implements org.apache.pinot.spi.ingestion.batch.runner.IngestionJobRunner interface
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentMetadataPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: your/local/dir/stagingspark.driver.extraClassPath =>
pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:pinot-all-${PINOT_VERSION}-jar-with-dependencies.jarspark.driver.extraJavaOptions =>
-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/pluginsexport PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin
spark-submit //
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand //
--master local --deploy-mode client //
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins" //
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark-2.4/pinot-batch-ingestion-spark-2.4-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
-conf "spark.executor.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark-2.4/pinot-batch-ingestion-spark-2.4-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar -jobSpecFile /path/to/spark_job_spec.yamlspark-submit //
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand //
--master yarn --deploy-mode cluster //
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins" //
--conf "spark.driver.extraClassPath=pinot-batch-ingestion-spark-2.4/pinot-batch-ingestion-spark-2.4-${PINOT_VERSION}-shaded.jar:pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
--conf "spark.executor.extraClassPath=pinot-batch-ingestion-spark-2.4/pinot-batch-ingestion-spark-2.4-${PINOT_VERSION}-shaded.jar:pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" //
--jars "${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark-2.4/pinot-batch-ingestion-spark-2.4-${PINOT_VERSION}-shaded.jar,${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar"
--files s3://path/to/spark_job_spec.yaml
local://pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar -jobSpecFile spark_job_spec.yamlComplex type handling in Apache Pinot.
This guide shows you how to ingest a stream of records from an Apache Pulsar topic into a Pinot table.
{
"ingestionConfig":{
"transformConfigs": [
{
"columnName": "group_json",
"transformFunction": "jsonFormat(\"group\")"
}
],
},
...
"tableIndexConfig": {
"loadMode": "MMAP",
"noDictionaryColumns": [
"group_json"
],
"jsonIndexColumns": [
"group_json"
]
},
}{
{
"name": "group_json",
"dataType": "JSON",
}
...
}{
"ingestionConfig": {
"complexTypeConfig": {
"delimiter": ".",
"fieldsToUnnest": ["group.group_topics"],
"collectionNotUnnestedToJson": "NON_PRIMITIVE"
}
}
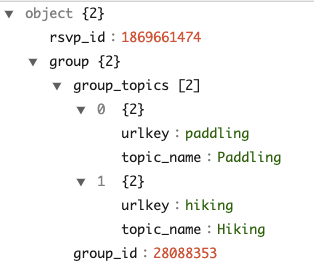
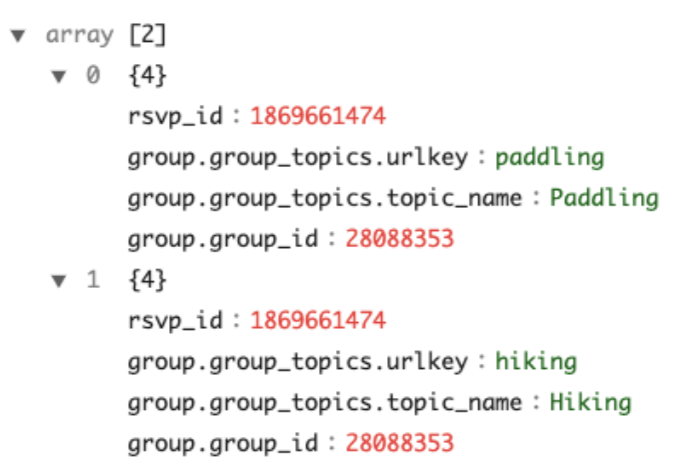
}SELECT "group.group_topics.urlkey",
"group.group_topics.topic_name",
"group.group_id"
FROM meetupRsvp
LIMIT 10bin/pinot-admin.sh AvroSchemaToPinotSchema \
-timeColumnName fields.hoursSinceEpoch \
-avroSchemaFile /tmp/test.avsc \
-pinotSchemaName myTable \
-outputDir /tmp/test \
-fieldsToUnnest entriesbin/pinot-admin.sh JsonToPinotSchema \
-timeColumnName hoursSinceEpoch \
-jsonFile /tmp/test.json \
-pinotSchemaName myTable \
-outputDir /tmp/test \
-fieldsToUnnest payload.commits{
"tableName": "pulsarTable",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "pulsar",
"stream.pulsar.topic.name": "<your pulsar topic name>",
"stream.pulsar.bootstrap.servers": "pulsar://localhost:6650,pulsar://localhost:6651",
"stream.pulsar.consumer.prop.auto.offset.reset" : "smallest",
"stream.pulsar.consumer.type": "lowlevel",
"stream.pulsar.fetch.timeout.millis": "30000",
"stream.pulsar.decoder.class.name": "org.apache.pinot.plugin.inputformat.json.JSONMessageDecoder",
"stream.pulsar.consumer.factory.class.name": "org.apache.pinot.plugin.stream.pulsar.PulsarConsumerFactory",
"realtime.segment.flush.threshold.rows": "1000000",
"realtime.segment.flush.threshold.time": "6h"
}
},
"metadata": {
"customConfigs": {}
}
}"stream.pulsar.authenticationToken":"your-auth-token""stream.pulsar.issuerUrl": "https://auth.streamnative.cloud"
"stream.pulsar.credsFilePath": "file:///path/to/private_creds_file
"stream.pulsar.audience": "urn:sn:pulsar:test:test-cluster""stream.pulsar.tlsTrustCertsFilePath": "/path/to/ca.cert.pem"
"streamConfigs": {
...
"stream.pulsar.metadata.populate": "true",
"stream.pulsar.metadata.fields": "messageId,messageIdBytes,eventTime,topicName",
...
} "dimensionFieldSpecs": [
{
"name": "__key",
"dataType": "STRING"
},
{
"name": "__metadata$messageId",
"dataType": "STRING"
},
...
],


This guide shows you how to ingest a stream of records from an Apache Kafka topic into a Pinot table.
docker pull wurstmeister/kafka:latesttar -xzf kafka_2.13-3.7.0.tgz
cd kafka_2.13-3.7.0docker run --network pinot-demo --name=kafka -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181/kafka -e KAFKA_BROKER_ID=0 -e KAFKA_ADVERTISED_HOST_NAME=kafka wurstmeister/kafka:latestbin/zookeeper-server-start.sh config/zookeeper.propertiesbin/kafka-server-start.sh config/server.propertiesBatch ingestion of data into Apache Pinot.
This guide shows you how to ingest a stream of records into a Pinot table.
ingestionConfigimport datetime
import uuid
import random
import json
while True:
ts = int(datetime.datetime.now().timestamp()* 1000)
id = str(uuid.uuid4())
count = random.randint(0, 1000)
print(
json.dumps({"ts": ts, "uuid": id, "count": count})
)
{"ts": 1644586485807, "uuid": "93633f7c01d54453a144", "count": 807}
{"ts": 1644586485836, "uuid": "87ebf97feead4e848a2e", "count": 41}
{"ts": 1644586485866, "uuid": "960d4ffa201a4425bb18", "count": 146}python datagen.py | docker exec -i kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic events;python datagen.py | bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic events;docker exec -i kafka kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic eventskafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic eventsevents:0:11940docker exec -i kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic eventsbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic events...
{"ts": 1644586485807, "uuid": "93633f7c01d54453a144", "count": 807}
{"ts": 1644586485836, "uuid": "87ebf97feead4e848a2e", "count": 41}
{"ts": 1644586485866, "uuid": "960d4ffa201a4425bb18", "count": 146}
...{
"schemaName": "events",
"dimensionFieldSpecs": [
{
"name": "uuid",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "count",
"dataType": "INT"
}
],
"dateTimeFieldSpecs": [{
"name": "ts",
"dataType": "TIMESTAMP",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "events",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "events",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "events",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "50M",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}docker run --rm -ti --network=pinot-demo -v /tmp/pinot:/tmp/pinot apachepinot/pinot:1.0.0 AddTable -schemaFile /tmp/pinot/schema-stream.json -tableConfigFile /tmp/pinot/table-config-stream.json -controllerHost pinot-controller -controllerPort 9000 -execbin/pinot-admin.sh AddTable -schemaFile /tmp/pinot/schema-stream.json -tableConfigFile /tmp/pinot/table-config-stream.json {
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "LowLevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "pinot-zookeeper:2191/kafka",
"stream.kafka.broker.list": "localhost:9092",
"schema.registry.url": "",
"security.protocol": "SSL",
"ssl.truststore.location": "",
"ssl.keystore.location": "",
"ssl.truststore.password": "",
"ssl.keystore.password": "",
"ssl.key.password": "",
"stream.kafka.decoder.prop.schema.registry.rest.url": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.location": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.location": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.keystore.type": "",
"stream.kafka.decoder.prop.schema.registry.ssl.truststore.type": "",
"stream.kafka.decoder.prop.schema.registry.ssl.key.password": "",
"stream.kafka.decoder.prop.schema.registry.ssl.protocol": ""
}
},
"metadata": {
"customConfigs": {}
}
} {
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "LowLevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "pinot-zookeeper:2191/kafka",
"stream.kafka.broker.list": "kafka:9092",
"stream.kafka.isolation.level": "read_committed"
}
},
"metadata": {
"customConfigs": {}
}
}"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "mytopic",
"stream.kafka.consumer.prop.auto.offset.reset": "largest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"stream.kafka.schema.registry.url": "https://xxx",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.confluent.KafkaConfluentSchemaRegistryAvroMessageDecoder",
"stream.kafka.decoder.prop.schema.registry.rest.url": "https://xxx",
"stream.kafka.decoder.prop.basic.auth.credentials.source": "USER_INFO",
"stream.kafka.decoder.prop.schema.registry.basic.auth.user.info": "schema_registry_username:schema_registry_password",
"sasl.mechanism": "PLAIN" ,
"security.protocol": "SASL_SSL" ,
"sasl.jaas.config":"org.apache.kafka.common.security.scram.ScramLoginModule required username=\"kafkausername\" password=\"kafkapassword\";",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.autotune.initialRows": "3000000",
"realtime.segment.flush.threshold.segment.size": "500M"
}, "dimensionFieldSpecs": [
{
"name": "__key",
"dataType": "STRING"
},
{
"name": "__metadata$offset",
"dataType": "STRING"
},
{
"name": "__metadata$partition",
"dataType": "STRING"
},
...
],...
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.inputformat.avro.SimpleAvroMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "",
"stream.kafka.consumer.prop.auto.offset.reset": "largest"
...
}recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
key1 : 'value1'
key2 : 'value2'dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
fileFormat: 'default' #should be one of default, rfc4180, excel, tdf, mysql
header: 'columnName separated by delimiter'
delimiter: ','
multiValueDelimiter: '-'dataFormat: 'avro'
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
configs:
enableLogicalTypes: truedataFormat: 'json'
className: 'org.apache.pinot.plugin.inputformat.json.JSONRecordReader'dataFormat: 'thrift'
className: 'org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader'
configs:
thriftClass: 'ParserClassName'dataFormat: 'parquet'
className: 'org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader'dataFormat: 'parquet'
className: 'org.apache.pinot.plugin.inputformat.parquet.ParquetNativeRecordReader'dataFormat: 'orc'
className: 'org.apache.pinot.plugin.inputformat.orc.ORCRecordReader'dataFormat: 'proto'
className: 'org.apache.pinot.plugin.inputformat.protobuf.ProtoBufRecordReader'
configs:
descriptorFile: 'file:///path/to/sample.desc'protoc --include_imports --descriptor_set_out=/absolute/path/to/output.desc /absolute/path/to/input.proto{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestamp":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestamp":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestamp":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestamp":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestamp":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestamp":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestamp":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestamp":1572854400000}{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestamp",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
},
"metadata": {
"customConfigs": {}
},
"ingestionConfig": {
"streamIngestionConfig": {
"streamConfigMaps": [
{
"realtime.segment.flush.threshold.rows": "0",
"stream.kafka.decoder.prop.format": "JSON",
"key.serializer": "org.apache.kafka.common.serialization.ByteArraySerializer",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"streamType": "kafka",
"value.serializer": "org.apache.kafka.common.serialization.ByteArraySerializer",
"stream.kafka.consumer.type": "LOWLEVEL",
"realtime.segment.flush.threshold.segment.rows": "50000",
"stream.kafka.broker.list": "localhost:9876",
"realtime.segment.flush.threshold.time": "3600000",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.topic.name": "transcript-topic"
}
]
},
"transformConfigs": [],
"continueOnError": true,
"rowTimeValueCheck": true,
"segmentTimeValueCheck": false
},
"isDimTable": false
}
}docker run \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost pinot-quickstart \
-controllerPort 9000 \
-execbin/pinot-admin.sh AddTable \
-schemaFile /path/to/transcript-schema.json \
-tableConfigFile /path/to/transcript-table-realtime.json \
-exec{
"tableName": "transcript",
"tableType": "REALTIME",
...
"ingestionConfig": {
"streamIngestionConfig":,
"streamConfigMaps": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
...
"topic.consumption.rate.limit": 1000
}
},
...A consumption rate limiter is set up for topic <topic_name> in table <tableName> with rate limit: <rate_limit> (topic rate limit: <topic_rate_limit>, partition count: <partition_count>)$ curl -X POST {controllerHost}/tables/{tableName}/forceCommit$ curl -X POST {controllerHost}/tables/{tableName}/pauseConsumption
$ curl -X POST {controllerHost}/tables/{tableName}/resumeConsumption$ curl -X POST {controllerHost}/tables/{tableName}/pauseStatus$ curl -X POST {controllerHost}/tables/{tableName}/forceCommit$ curl -X POST {controllerHost}/tables/{tableName}/forceCommit
{
"forceCommitJobId": "6757284f-b75b-45ce-91d8-a277bdbc06ae",
"forceCommitStatus": "SUCCESS",
"jobMetaZKWriteStatus": "SUCCESS"
}
$ curl -X GET {controllerHost}/tables/forceCommitStatus/6757284f-b75b-45ce-91d8-a277bdbc06ae
{
"jobId": "6757284f-b75b-45ce-91d8-a277bdbc06ae",
"segmentsForceCommitted": "[\"airlineStats__0__0__20230119T0700Z\",\"airlineStats__1__0__20230119T0700Z\",\"airlineStats__2__0__20230119T0700Z\"]",
"submissionTimeMs": "1674111682977",
"numberOfSegmentsYetToBeCommitted": 0,
"jobType": "FORCE_COMMIT",
"segmentsYetToBeCommitted": [],
"tableName": "airlineStats_REALTIME"
}$ curl -X POST {controllerHost}/tables/{tableName}/resumeConsumption?resumeFrom=smallest
$ curl -X POST {controllerHost}/tables/{tableName}/resumeConsumption?resumeFrom=largest# GET /tables/{tableName}/consumingSegmentsInfo
curl -X GET "http://<controller_url:controller_admin_port>/tables/meetupRsvp/consumingSegmentsInfo" -H "accept: application/json"
# GET /debug/tables/{tableName}
curl -X GET "http://localhost:9000/debug/tables/meetupRsvp?type=REALTIME&verbosity=1" -H "accept: application/json"{
"_segmentToConsumingInfoMap": {
"meetupRsvp__0__0__20221019T0639Z": [
{
"serverName": "Server_192.168.0.103_7000",
"consumerState": "CONSUMING",
"lastConsumedTimestamp": 1666161593904,
"partitionToOffsetMap": { // <<-- Deprecated. See currentOffsetsMap for same info
"0": "6"
},
"partitionOffsetInfo": {
"currentOffsetsMap": {
"0": "6" // <-- Current consumer position
},
"latestUpstreamOffsetMap": {
"0": "6" // <-- Upstream latest position
},
"recordsLagMap": {
"0": "0" // <-- Lag, in terms of #records behind latest
},
"recordsAvailabilityLagMap": {
"0": "2" // <-- Lag, in terms of time
}
}
}
],studentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}{
"tableName": "transcript",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": 1,
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": 365
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"continueOnError": true,
"rowTimeValueCheck": true,
"segmentTimeValueCheck": false
},
"metadata": {}
}bin/pinot-admin.sh AddTable \\
-tableConfigFile /path/to/table-config.json \\
-schemaFile /path/to/table-schema.json -execcurl -X POST -F [email protected] \
-H "Content-Type: multipart/form-data" \
"http://localhost:9000/ingestFromFile?tableNameWithType=foo_OFFLINE&
batchConfigMapStr={"inputFormat":"json"}"curl -X POST -F [email protected] \
-H "Content-Type: multipart/form-data" \
"http://localhost:9000/ingestFromFile?tableNameWithType=foo_OFFLINE&
batchConfigMapStr={
"inputFormat":"csv",
"recordReader.prop.delimiter":"|"
}"curl -X POST "http://localhost:9000/ingestFromURI?tableNameWithType=foo_OFFLINE
&batchConfigMapStr={
"inputFormat":"json",
"input.fs.className":"org.apache.pinot.plugin.filesystem.S3PinotFS",
"input.fs.prop.region":"us-central",
"input.fs.prop.accessKey":"foo",
"input.fs.prop.secretKey":"bar"
}
&sourceURIStr=s3://test.bucket/path/to/json/data/data.json"executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentMetadataPushJobRunner'
# Recommended to set jobType to SegmentCreationAndMetadataPush for production environment where Pinot Deep Store is configured
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushAttempts: 2
pushRetryIntervalMillis: 1000bin/pinot-admin.sh LaunchDataIngestionJob \\
-jobSpecFile /tmp/pinot-quick-start/batch-job-spec.yaml{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::metadata-push-staging",
"arn:aws:s3:::metadata-push-staging/*"
]
}
]
}...
jobType: SegmentCreationAndMetadataPush
...
outputDirURI: 's3://metadata-push-staging/stagingDir/'
...
pushJobSpec:
copyToDeepStoreForMetadataPush: true
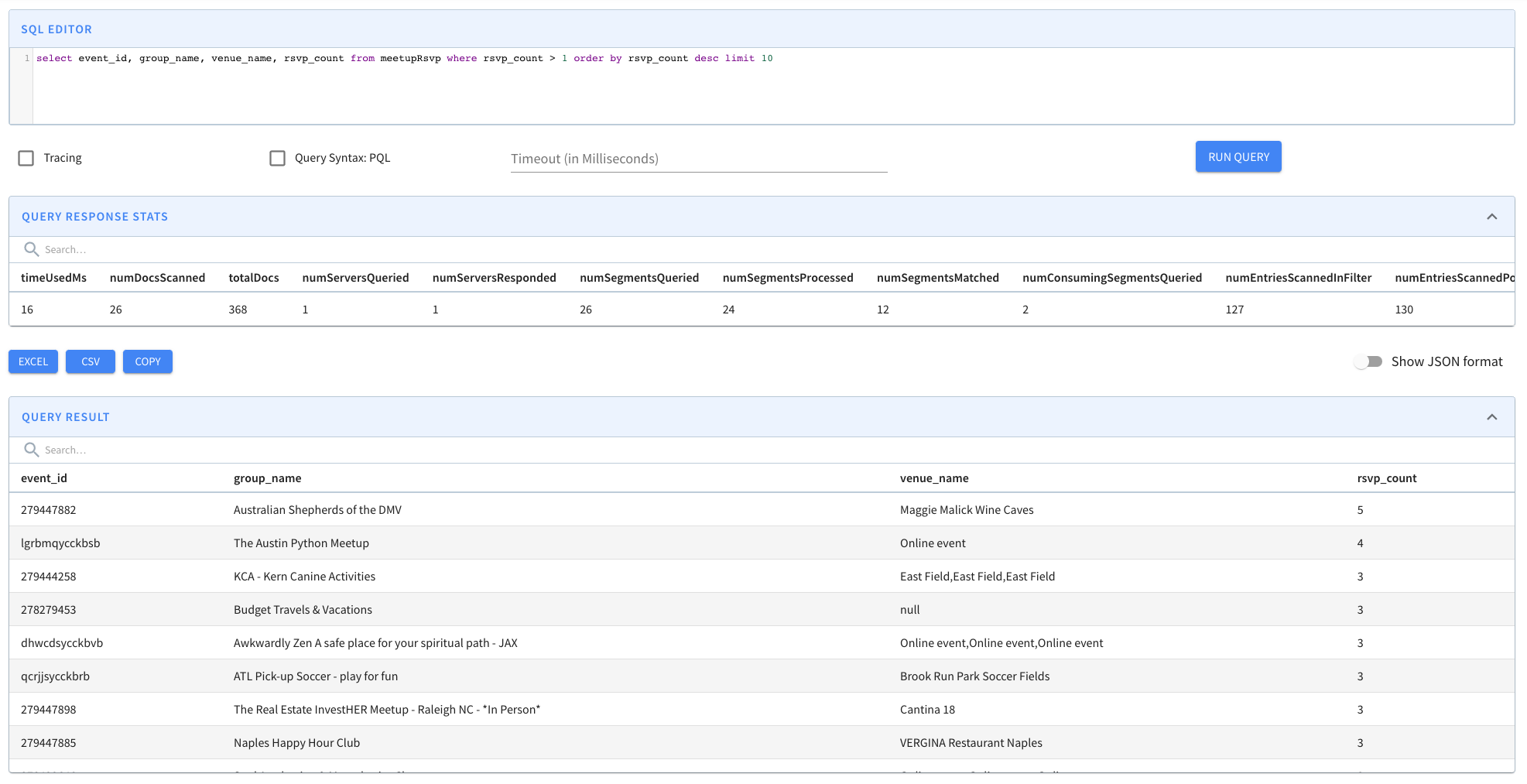
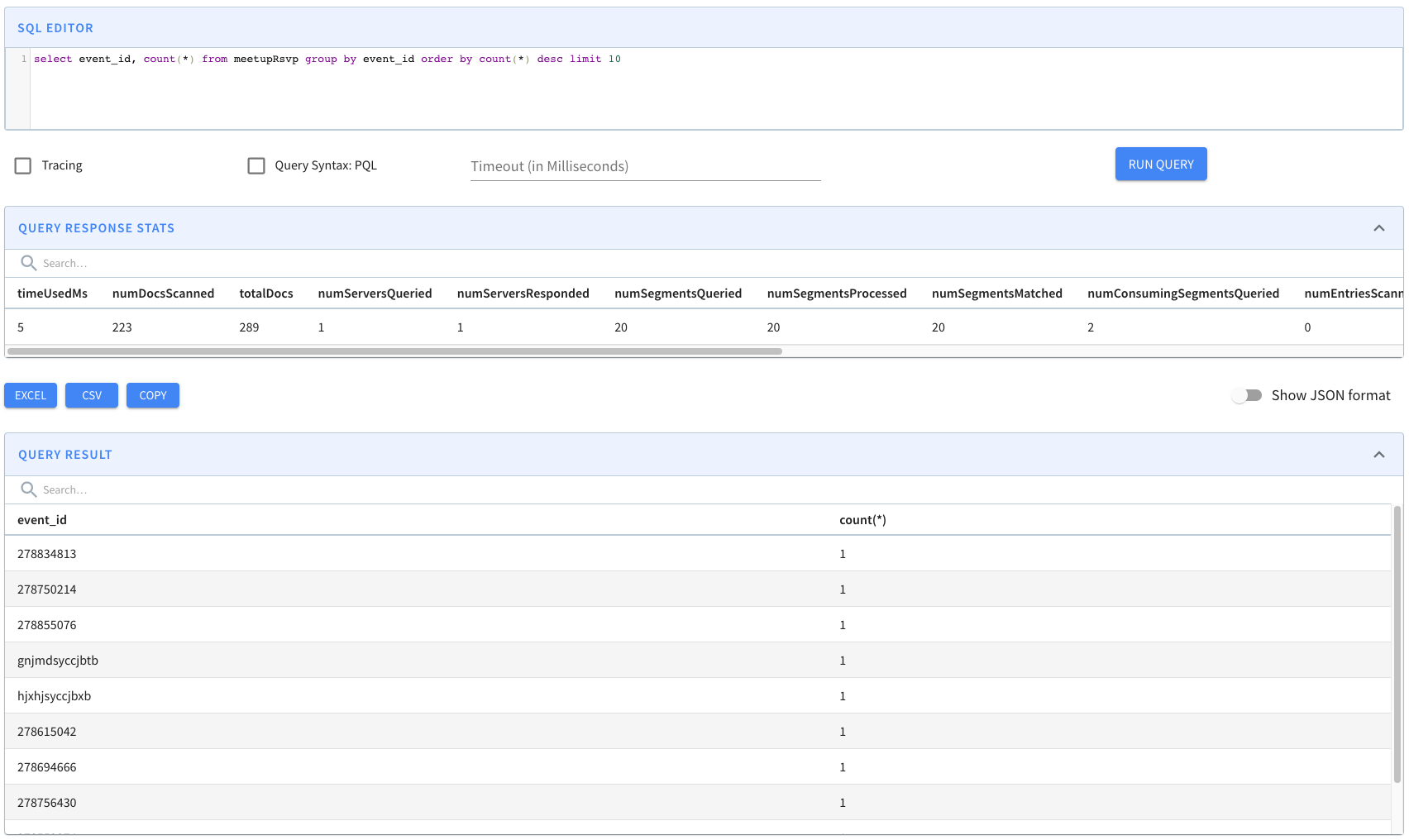
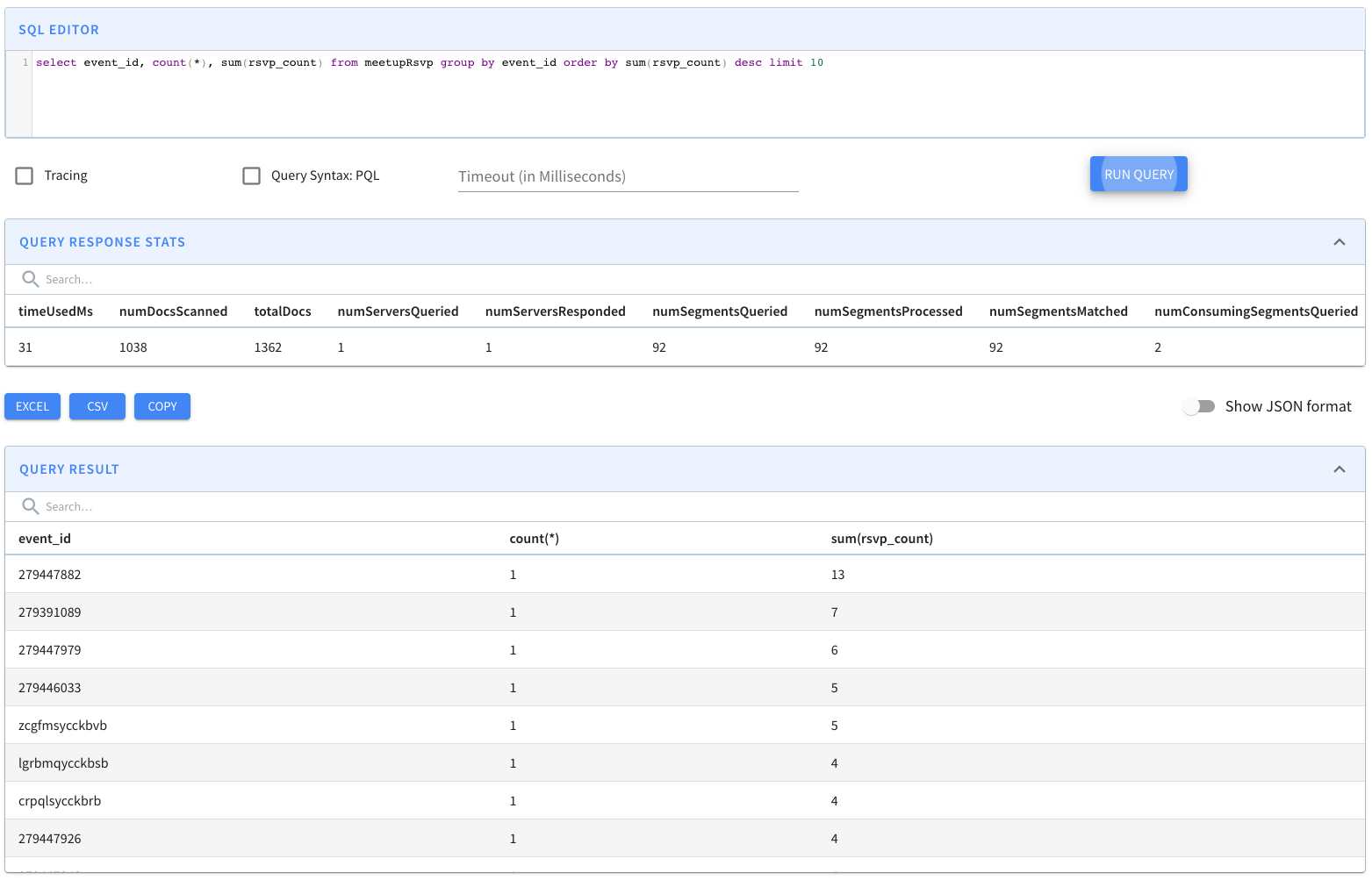
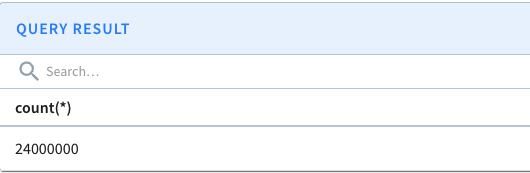
...Upsert support in Apache Pinot.
{
"primaryKeyColumns": ["event_id"]
}{
"upsertConfig": {
"mode": "FULL"
}
}{
"upsertConfig": {
"mode": "PARTIAL",
"partialUpsertStrategies":{
"rsvp_count": "INCREMENT",
"group_name": "IGNORE",
"venue_name": "OVERWRITE"
}
},
"tableIndexConfig": {
"nullHandlingEnabled": true
}
}{
"upsertConfig": {
"mode": "PARTIAL",
"defaultPartialUpsertStrategy": "OVERWRITE",
"partialUpsertStrategies":{
"rsvp_count": "INCREMENT",
"group_name": "IGNORE"
}
},
"tableIndexConfig": {
"nullHandlingEnabled": true
}
}{
"upsertConfig": {
"mode": "FULL",
"comparisonColumn": "anotherTimeColumn"
}
}{
"upsertConfig": {
"mode": "PARTIAL",
"defaultPartialUpsertStrategy": "OVERWRITE",
"partialUpsertStrategies":{},
"comparisonColumns": ["secondsSinceEpoch", "otherComparisonColumn"]
}
}[
{
"event_id": "aa",
"orderReceived": 1,
"description" : "first",
"secondsSinceEpoch": 1567205394
},
{
"event_id": "aa",
"orderReceived": 2,
"description" : "update",
"secondsSinceEpoch": 1567205397
},
{
"event_id": "aa",
"orderReceived": 3,
"description" : "update",
"secondsSinceEpoch": 1567205396
},
{
"event_id": "aa",
"orderReceived": 4,
"description" : "first arrival, other column",
"otherComparisonColumn": 1567205395
},
{
"event_id": "aa",
"orderReceived": 5,
"description" : "late arrival, other column",
"otherComparisonColumn": 1567205392
},
{
"event_id": "aa",
"orderReceived": 6,
"description" : "update, other column",
"otherComparisonColumn": 1567205398
}
] "upsertConfig": {
"mode": "FULL",
"enableSnapshot": true,
"enablePreload": true,
"metadataTTL": 86400
}
}{
"upsertConfig": {
...
"deleteRecordColumn": <column_name>
}
}// In the Schema
{
...
{
"name": "<delete_column_name>",
"dataType": "BOOLEAN"
},
...
} "upsertConfig": {
"mode": "FULL",
"deleteRecordColumn": <column_name>,
"deletedKeysTTL": 86400
}
}{
"routing": {
"instanceSelectorType": "strictReplicaGroup"
}
}{
"upsertConfig": {
"mode": "FULL",
"enableSnapshot": true
}
}{
"upsertConfig": {
"mode": "FULL",
"enableSnapshot": true,
"enablePreload": true
}
}{
"upsertConfig": {
...,
"dropOutOfOrderRecord": true
}
}{
"upsertConfig": {
...,
"outOfOrderRecordColumn": "isOutOfOrder"
}
}select key, val from tbl1 where isOutOfOrder = false option(skipUpsert=false){
"upsertConfig": {
"metadataManagerClass": org.apache.pinot.segment.local.upsert.CustomPartitionUpsertMetadataManager
}
}<dependency>
<groupId>org.apache.pinot</groupId>
<artifactId>pinot-segment-local</artifactId>
<version>1.0.0</version>
</dependency>include 'org.apache.pinot:pinot-common:1.0.0'//Example custom partition manager
class CustomPartitionUpsertMetadataManager implements PartitionUpsertMetadataManager {}//Example custom table upsert metadata manager
public class CustomTableUpsertMetadataManager extends BaseTableUpsertMetadataManager {}{
"upsertConfig": {
"metadataManagerClass": org.apache.pinot.segment.local.upsert.CustomPartitionUpsertMetadataManager
}
}{
"tableName": "upsertMeetupRsvp",
"tableType": "REALTIME",
"tenants": {},
"segmentsConfig": {
"timeColumnName": "mtime",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "1",
"replication": "1"
},
"tableIndexConfig": {
"segmentPartitionConfig": {
"columnPartitionMap": {
"event_id": {
"functionName": "Hashcode",
"numPartitions": 2
}
}
}
},
"instanceAssignmentConfigMap": {
"CONSUMING": {
"tagPoolConfig": {
"tag": "DefaultTenant_REALTIME"
},
"replicaGroupPartitionConfig": {
"replicaGroupBased": true,
"numReplicaGroups": 1,
"partitionColumn": "event_id",
"numPartitions": 2,
"numInstancesPerPartition": 1
}
}
},
"routing": {
"segmentPrunerTypes": [
"partition"
],
"instanceSelectorType": "strictReplicaGroup"
},
"ingestionConfig": {
"streamIngestionConfig": {
"streamConfigMaps": [
{
"streamType": "kafka",
"stream.kafka.topic.name": "upsertMeetupRSVPEvents",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:19092"
}
]
}
},
"upsertConfig": {
"mode": "FULL",
"enableSnapshot": true,
"enablePreload": true
},
"fieldConfigList": [
{
"name": "location",
"encodingType": "RAW",
"indexType": "H3",
"properties": {
"resolutions": "5"
}
}
],
"metadata": {
"customConfigs": {}
}
}{
"tableName": "upsertPartialMeetupRsvp",
"tableType": "REALTIME",
"tenants": {},
"segmentsConfig": {
"timeColumnName": "mtime",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "1",
"replication": "1"
},
"tableIndexConfig": {
"segmentPartitionConfig": {
"columnPartitionMap": {
"event_id": {
"functionName": "Hashcode",
"numPartitions": 2
}
}
},
"nullHandlingEnabled": true
},
"instanceAssignmentConfigMap": {
"CONSUMING": {
"tagPoolConfig": {
"tag": "DefaultTenant_REALTIME"
},
"replicaGroupPartitionConfig": {
"replicaGroupBased": true,
"numReplicaGroups": 1,
"partitionColumn": "event_id",
"numPartitions": 2,
"numInstancesPerPartition": 1
}
}
},
"routing": {
"segmentPrunerTypes": [
"partition"
],
"instanceSelectorType": "strictReplicaGroup"
},
"ingestionConfig": {
"streamIngestionConfig": {
"streamConfigMaps": [
{
"streamType": "kafka",
"stream.kafka.topic.name": "upsertPartialMeetupRSVPEvents",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.zk.broker.url": "localhost:2191/kafka",
"stream.kafka.broker.list": "localhost:19092"
}
]
}
},
"upsertConfig": {
"mode": "PARTIAL",
"partialUpsertStrategies": {
"rsvp_count": "INCREMENT",
"group_name": "UNION",
"venue_name": "APPEND"
}
},
"fieldConfigList": [
{
"name": "location",
"encodingType": "RAW",
"indexType": "H3",
"properties": {
"resolutions": "5"
}
}
],
"metadata": {
"customConfigs": {}
}
}# stop previous quick start cluster, if any
bin/quick-start-upsert-streaming.sh# stop previous quick start cluster, if any
bin/quick-start-partial-upsert-streaming.sh