Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
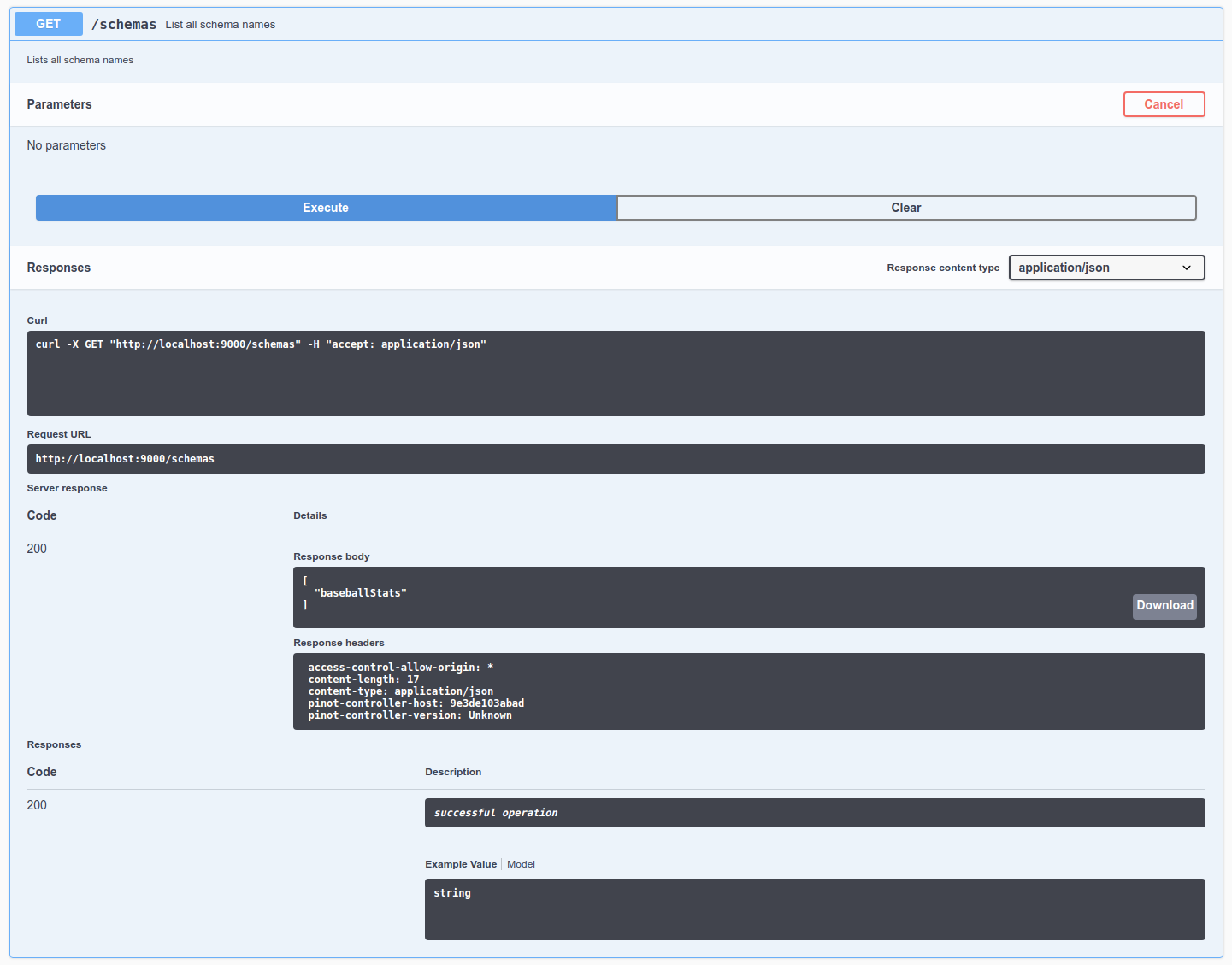
Discover how Apache Pinot's broker component optimizes query processing, data retrieval, and enhances data-driven applications.
docker run \
--network=pinot-demo \
--name pinot-broker \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
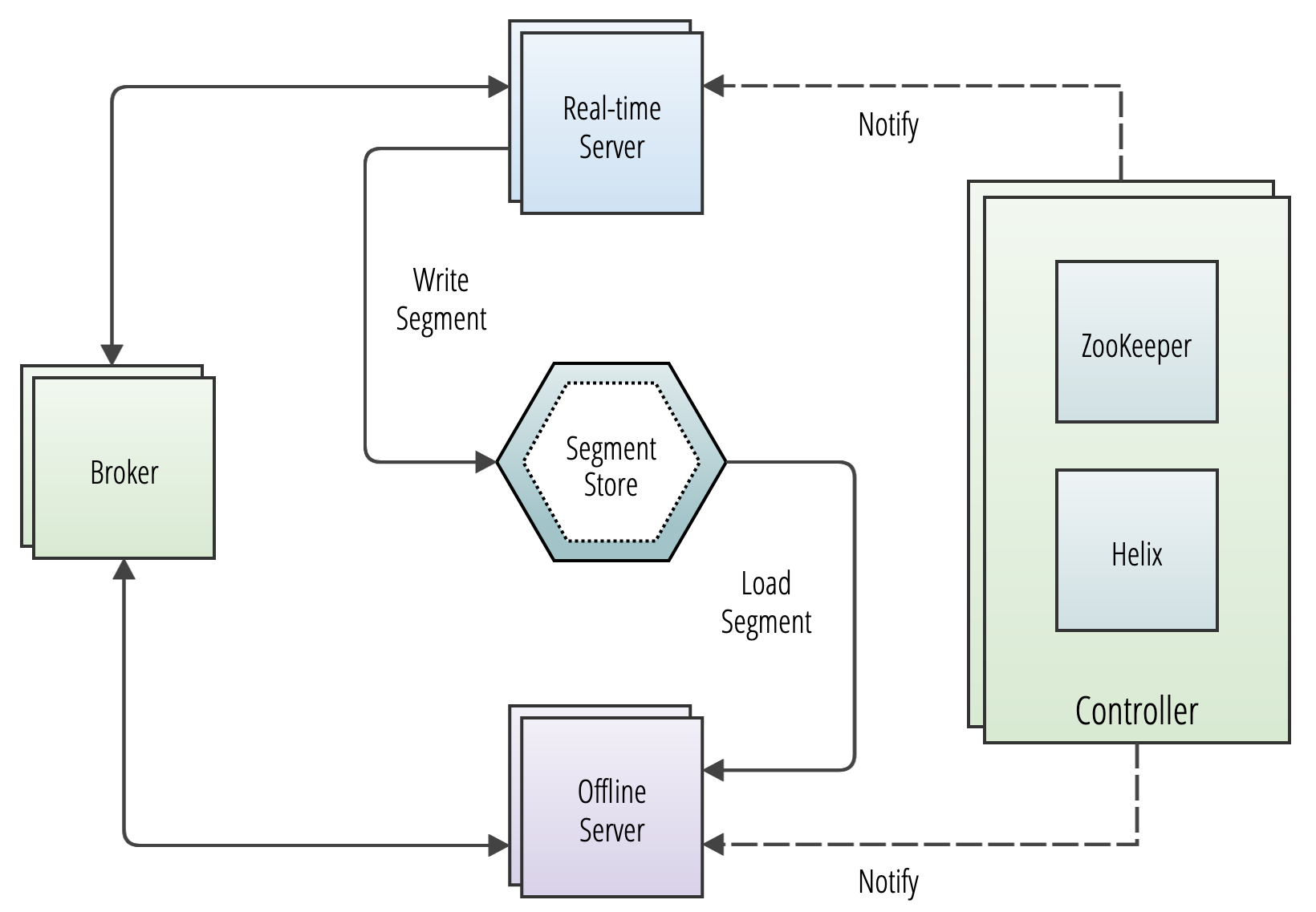
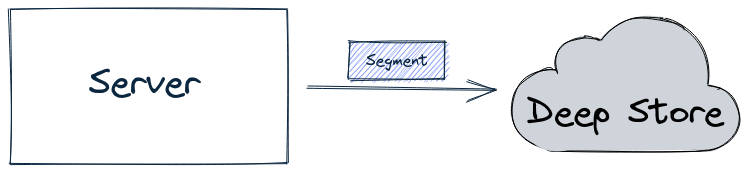
-brokerPort 7000Leverage Apache Pinot's deep store component for efficient large-scale data storage and management, enabling impactful data processing and analysis.
curl -X GET "http://localhost:9000/periodictask/names" -H "accept: application/json"
[
"RetentionManager",
"OfflineSegmentIntervalChecker",
"RealtimeSegmentValidationManager",
"BrokerResourceValidationManager",
"SegmentStatusChecker",
"SegmentRelocator",
"StaleInstancesCleanupTask",
"TaskMetricsEmitter"
]curl -X GET "http://localhost:9000/periodictask/run?taskname=SegmentStatusChecker&tableName=jsontypetable&type=OFFLINE" -H "accept: application/json"
{
"Log Request Id": "api-09630c07",
"Controllers notified": true
}docker run \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartController \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
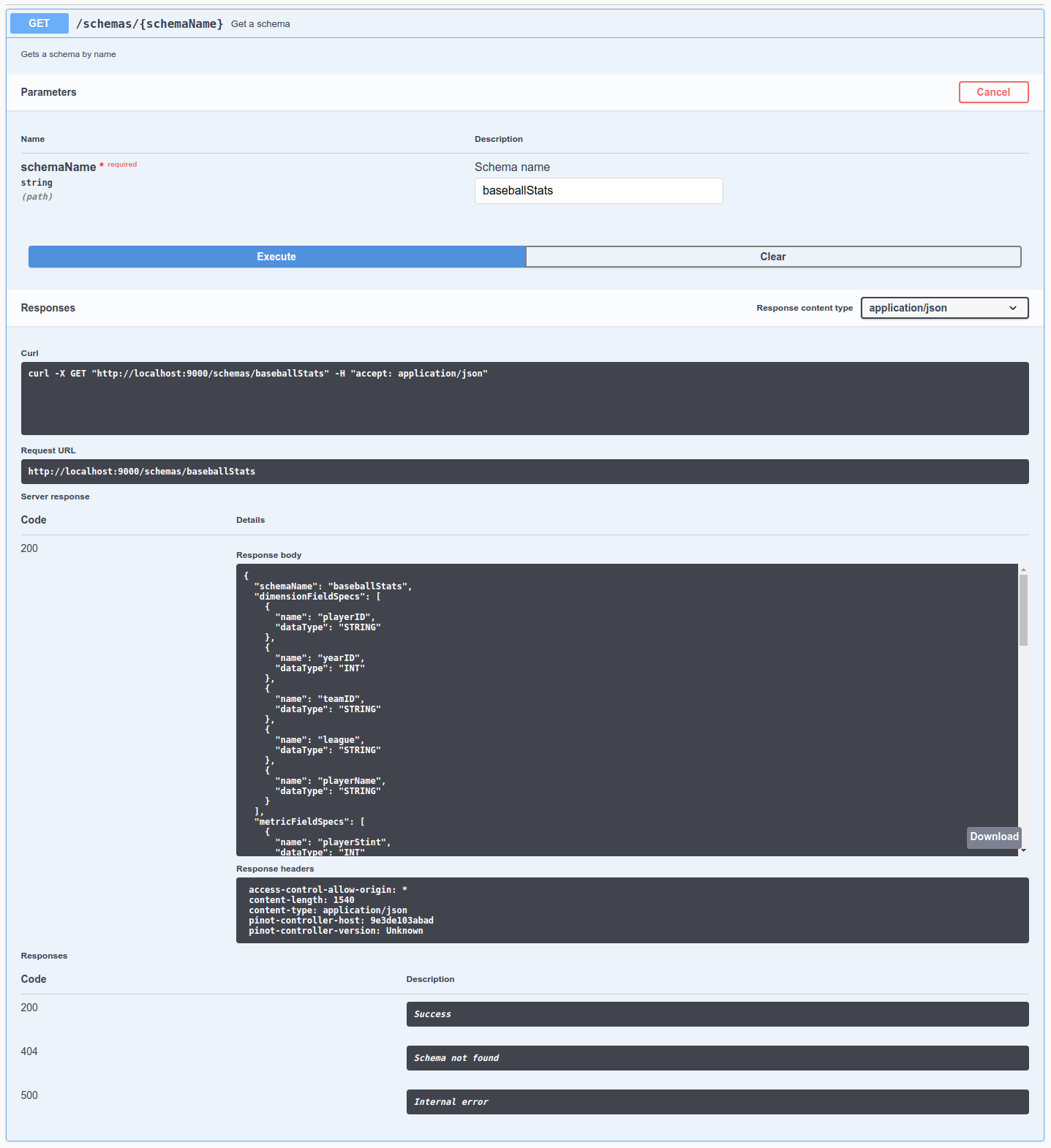
-controllerPort 9000Explore the Schema component in Apache Pinot, vital for defining the structure and data types of Pinot tables, enabling efficient data processing and analysis.
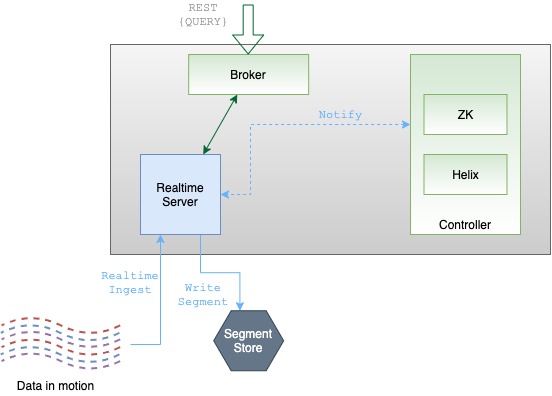
Uncover the efficient data processing and storage capabilities of Apache Pinot's server component, optimizing performance for data-driven applications.
docker run \
--network=pinot-demo \
--name pinot-server \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181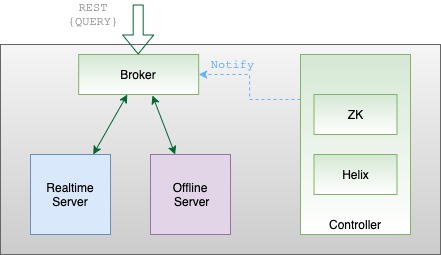
bin/pinot-admin.sh AddSchema -schemaFile flights-schema.json -exec
OR
bin/pinot-admin.sh AddTable -schemaFile flights-schema.json -tableFile flights-table.json -execcurl -F [email protected] localhost:9000/schemas{
"schemaName": "flights",
"dimensionFieldSpecs": [
{
"name": "flightNumber",
"dataType": "LONG"
},
{
"name": "tags",
"dataType": "STRING",
"singleValueField": false,
"defaultNullValue": "null"
}
],
"metricFieldSpecs": [
{
"name": "price",
"dataType": "DOUBLE",
"defaultNullValue": 0
}
],
"dateTimeFieldSpecs": [
{
"name": "millisSinceEpoch",
"dataType": "LONG",
"format": "EPOCH",
"granularity": "15:MINUTES"
},
{
"name": "hoursSinceEpoch",
"dataType": "INT",
"format": "EPOCH|HOURS",
"granularity": "1:HOURS"
},
{
"name": "dateString",
"dataType": "STRING",
"format": "SIMPLE_DATE_FORMAT|yyyy-MM-dd",
"granularity": "1:DAYS"
}
]
}bin/pinot-admin.sh StartServer \
-zkAddress localhost:2181Usage: StartServer
-serverHost <String> : Host name for controller. (required=false)
-serverPort <int> : Port number to start the server at. (required=false)
-serverAdminPort <int> : Port number to serve the server admin API at. (required=false)
-dataDir <string> : Path to directory containing data. (required=false)
-segmentDir <string> : Path to directory containing segments. (required=false)
-zkAddress <http> : Http address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Broker Starter Config file. (required=false)
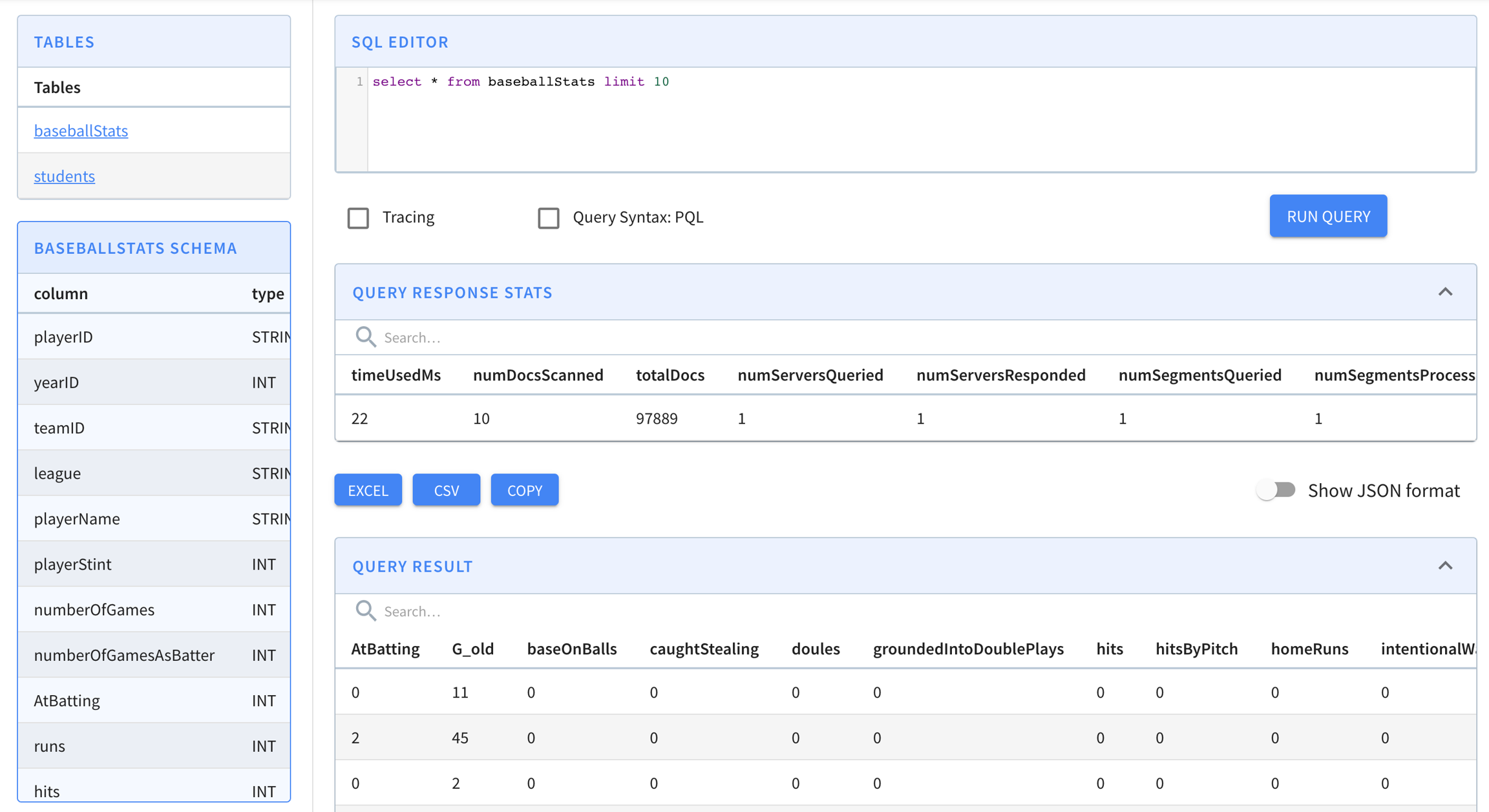
-help : Print this message. (required=false)select playerName, max(hits)
from baseballStats
group by playerName
order by max(hits) descselect sum(hits), sum(homeRuns), sum(numberOfGames)
from baseballStats
where yearID > 2010select *
from baseballStats
order by leagueserverTenantName_REALTIME
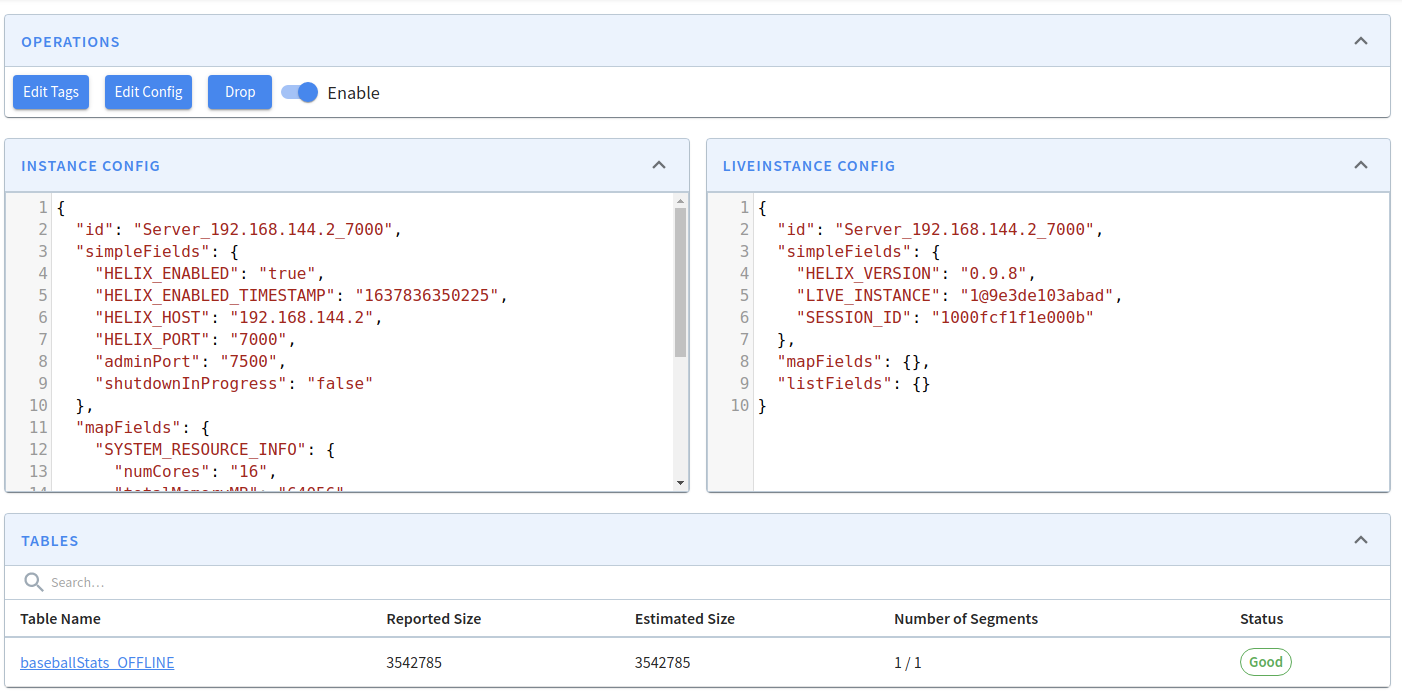
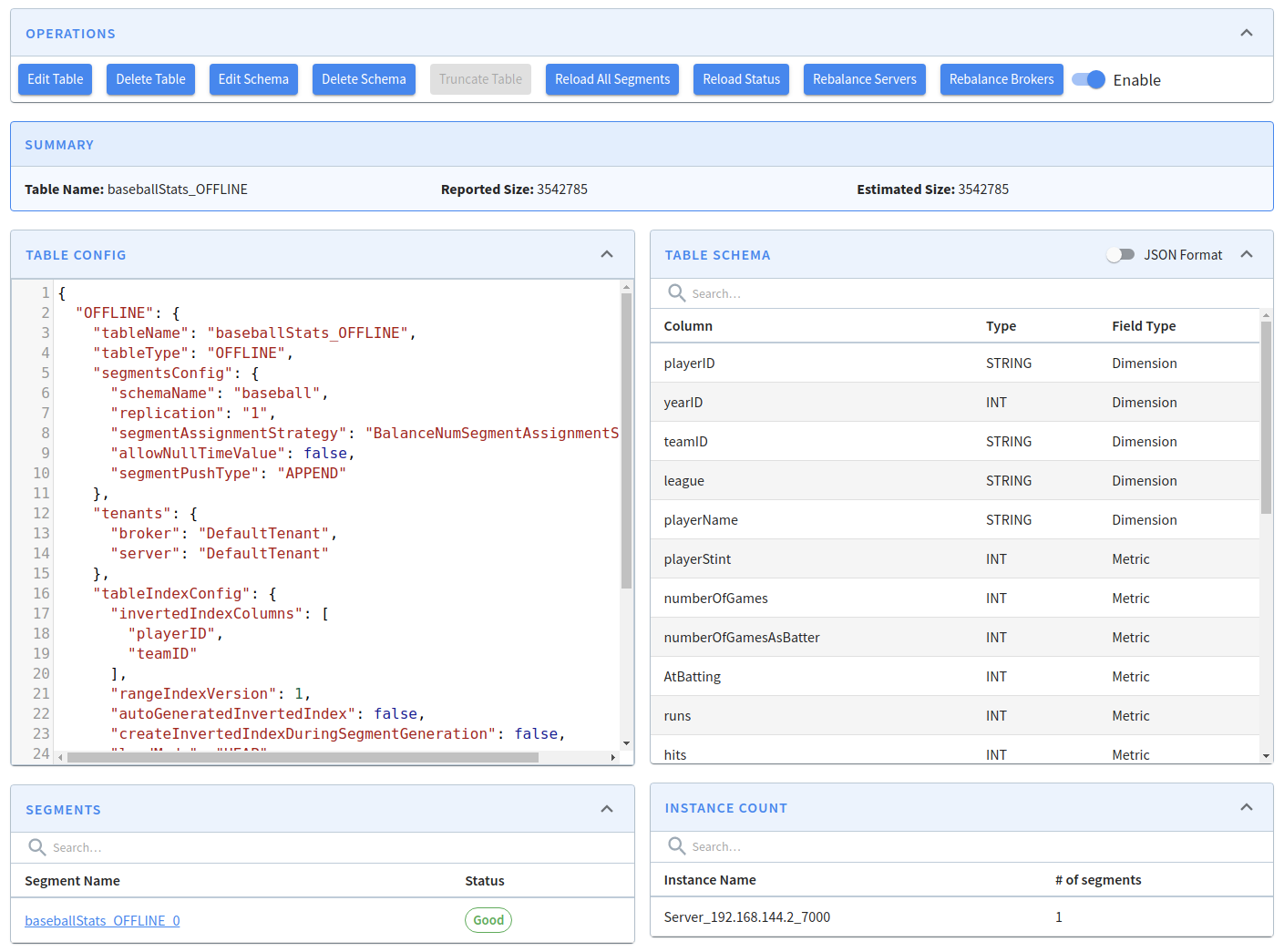
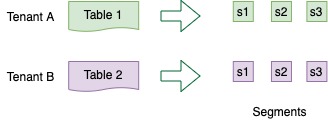
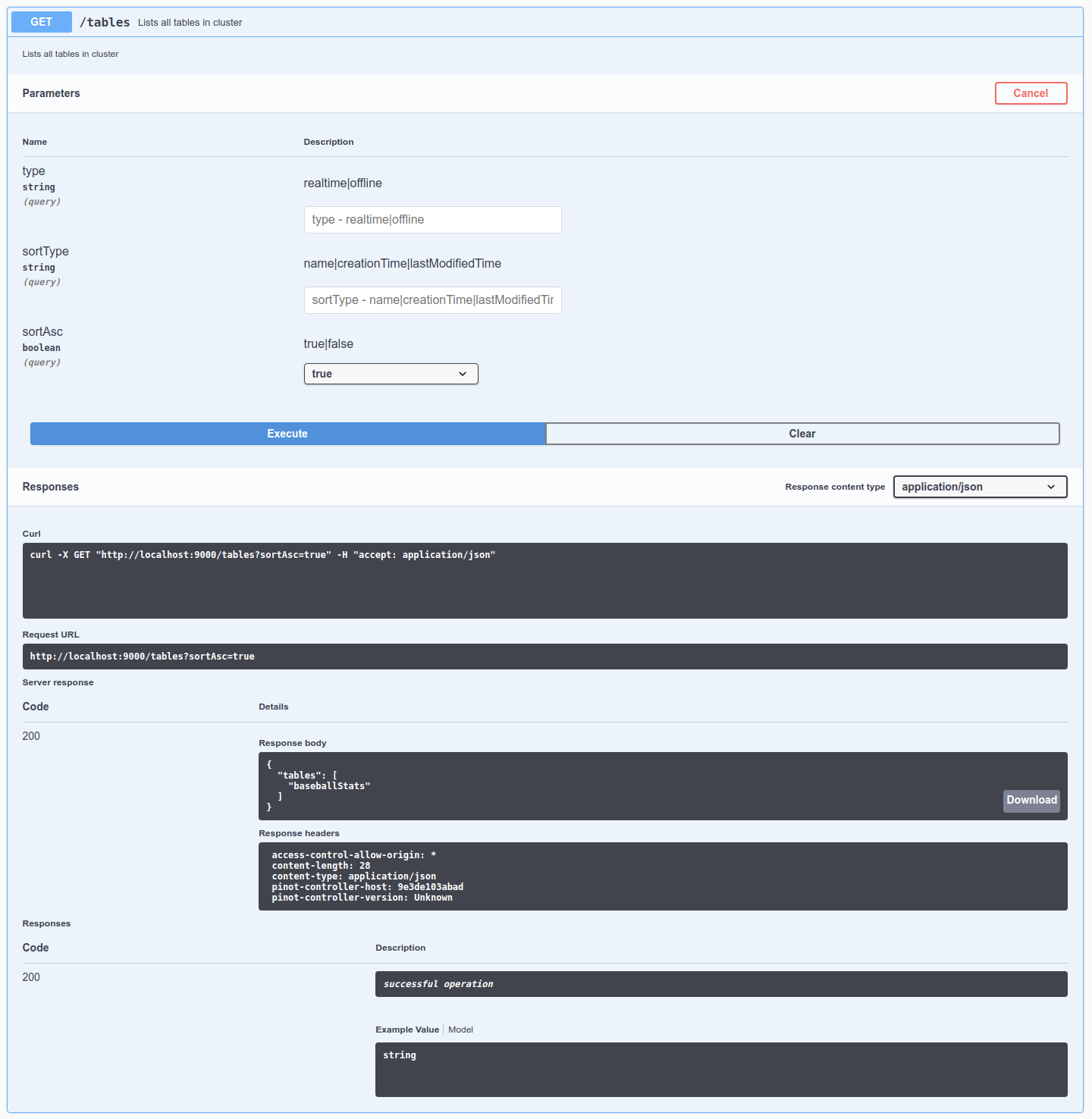
Explore the table component in Apache Pinot, a fundamental building block for organizing and managing data in Pinot clusters, enabling effective data processing and analysis.
"tenants": {
"broker": "brokerTenantName",
"server": "serverTenantName"
}{
"tenantRole" : "BROKER",
"tenantName" : "sampleBrokerTenant",
"numberOfInstances" : 3
}bin/pinot-admin.sh AddTenant \
-name sampleBrokerTenant
-role BROKER
-instanceCount 3 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-broker-tenant.json localhost:9000/tenants{
"tenantRole" : "SERVER",
"tenantName" : "sampleServerTenant",
"offlineInstances" : 1,
"realtimeInstances" : 1
}bin/pinot-admin.sh AddTenant \
-name sampleServerTenant \
-role SERVER \
-offlineInstanceCount 1 \
-realtimeInstanceCount 1 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-server-tenant.json localhost:9000/tenants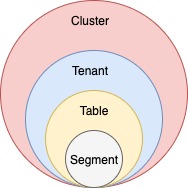
select count(*)
from myTable "tableIndexConfig": {
"noDictionaryColumns": ["metric1", "metric2"],
"aggregateMetrics": true,
...
} "broker": "brokerTenantName",
"server": "serverTenantName",
"tagOverrideConfig" : {
"realtimeConsuming" : "serverTenantName_REALTIME"
"realtimeCompleted" : "serverTenantName_OFFLINE"
}
}docker run \
--network=pinot-demo \
--name pinot-batch-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -schemaFile examples/batch/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: a413b0013806, version: Unknown
{"status":"Table airlineStats_OFFLINE succesfully added"}bin/pinot-admin.sh AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-exec# add schema
curl -F schemaName=@airlineStats_schema.json localhost:9000/schemas
# add table
curl -i -X POST -H 'Content-Type: application/json' \
-d @airlineStats_offline_table_config.json localhost:9000/tablesdocker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper pinot-zookeeper:2181/kafka \
--partitions=1 --replication-factor=1 \
--create --topic flights-realtimedocker run \
--network=pinot-demo \
--name pinot-streaming-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json -schemaFile examples/stream/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: 8fbe601012f3, version: Unknown
{"status":"Table airlineStats_REALTIME succesfully added"}bin/pinot-admin.sh StartZookeeper -zkPort 2191bin/pinot-admin.sh StartKafka -zkAddress=localhost:2191/kafka -port 19092"OFFLINE": {
"tableName": "pinotTable",
"tableType": "OFFLINE",
"segmentsConfig": {
...
},
"tableIndexConfig": {
...
},
"tenants": {
"broker": "myBrokerTenant",
"server": "myServerTenant"
},
"metadata": {
...
}
},
"REALTIME": {
"tableName": "pinotTable",
"tableType": "REALTIME",
"segmentsConfig": {
...
},
"tableIndexConfig": {
...
"streamConfigs": {
...
},
},
"tenants": {
"broker": "myBrokerTenant",
"server": "myServerTenant"
},
"metadata": {
...
}
}
}bin/pinot-admin.sh AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/stream/airlineStats/airlineStats_realtime_table_config.json \
-exec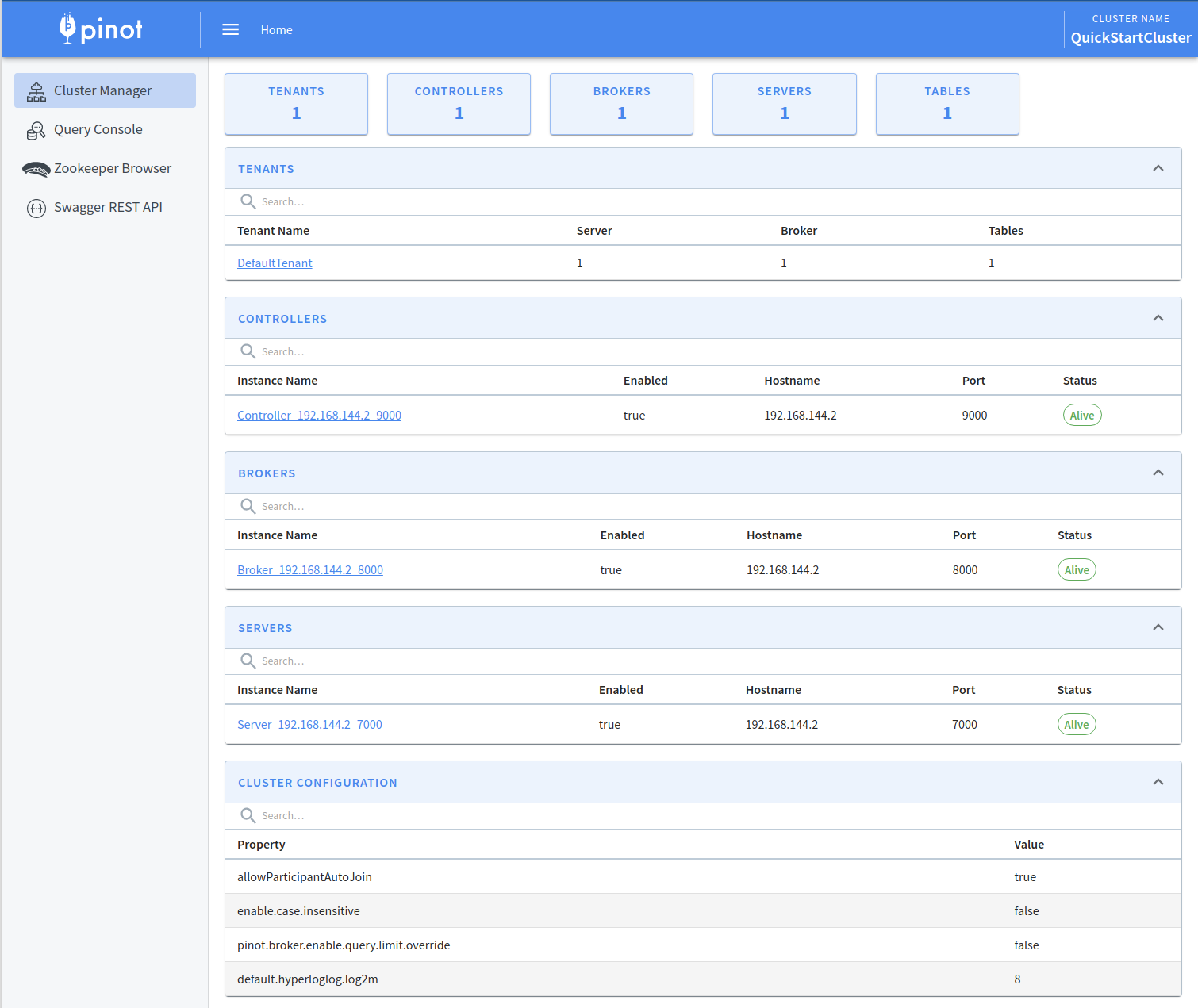
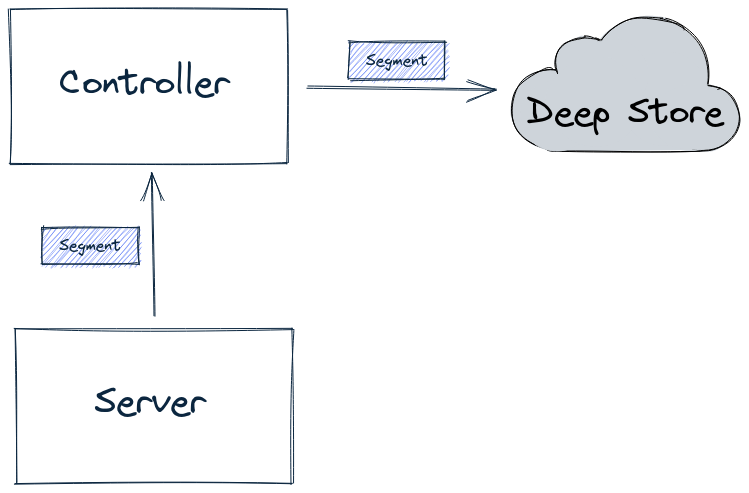
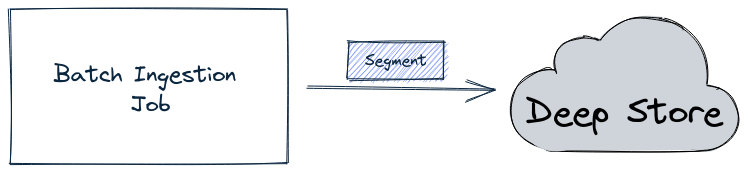
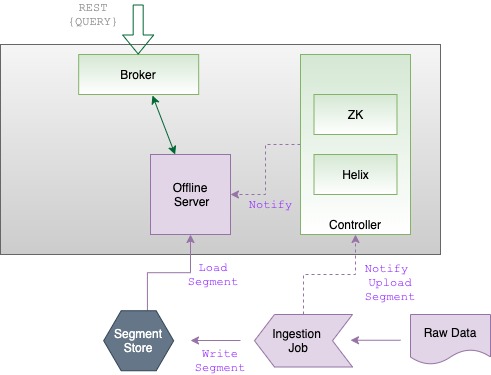
Discover the segment component in Apache Pinot for efficient data storage and querying within Pinot clusters, enabling optimized data processing and analysis.
docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yamlSegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**/*.avro
inputDirURI: examples/batch/airlineStats/rawdata
jobType: SegmentCreationAndTarPush
outputDirURI: examples/batch/airlineStats/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://pinot-controller:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
pushJobSpec: {pushAttempts: 2, pushParallelism: 1, pushRetryIntervalMillis: 1000,
segmentUriPrefix: null, segmentUriSuffix: null}
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.avro.AvroRecordReader,
configClassName: null, configs: null, dataFormat: avro}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://pinot-controller:9000/tables/airlineStats/schema',
tableConfigURI: 'http://pinot-controller:9000/tables/airlineStats', tableName: airlineStats}
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Finished building StatsCollector!
Collected stats for 403 documents
Created dictionary for INT column: FlightNum with cardinality: 386, range: 14 to 7389
Using fixed bytes value dictionary for column: Origin, size: 294
Created dictionary for STRING column: Origin with cardinality: 98, max length in bytes: 3, range: ABQ to VPS
Created dictionary for INT column: Quarter with cardinality: 1, range: 1 to 1
Created dictionary for INT column: LateAircraftDelay with cardinality: 50, range: -2147483648 to 303
......
......
Pushing segment: airlineStats_OFFLINE_16085_16085_29 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16085_16085_29 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16085_16085_29 of table: airlineStats"}
Pushing segment: airlineStats_OFFLINE_16084_16084_30 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16084_16084_30 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16084_16084_30 of table: airlineStats"}bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile examples/batch/airlineStats/ingestionJobSpec.yamldocker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yaml
-values year=2014 month=01 day=03docker run \
--network pinot-demo \
--name=loading-airlineStats-data-to-kafka \
${PINOT_IMAGE} StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList kafka:9092 -zkAddress pinot-zookeeper:2181/kafkabin/pinot-admin.sh StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList localhost:19092 -zkAddress localhost:2191/kafkaexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'examples/batch/baseballStats/rawdata'
includeFileNamePattern: 'glob:**/*.csv'
excludeFileNamePattern: 'glob:**/*.tmp'
outputDirURI: 'examples/batch/baseballStats/segments'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
tableSpec:
tableName: 'baseballStats'
schemaURI: 'http://localhost:9000/tables/baseballStats/schema'
tableConfigURI: 'http://localhost:9000/tables/baseballStats'
segmentNameGeneratorSpec:
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000inputDirURI: 'examples/batch/airlineStats/rawdata/${year}/${month}/${day}'
outputDirURI: 'examples/batch/airlineStats/segments/${year}/${month}/${day}'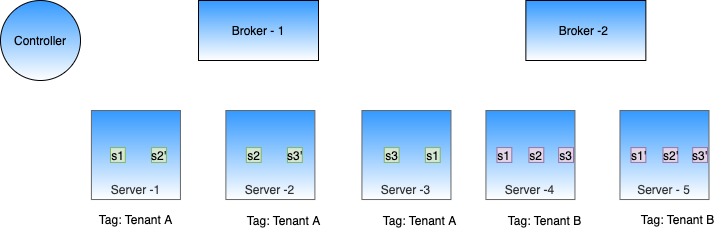
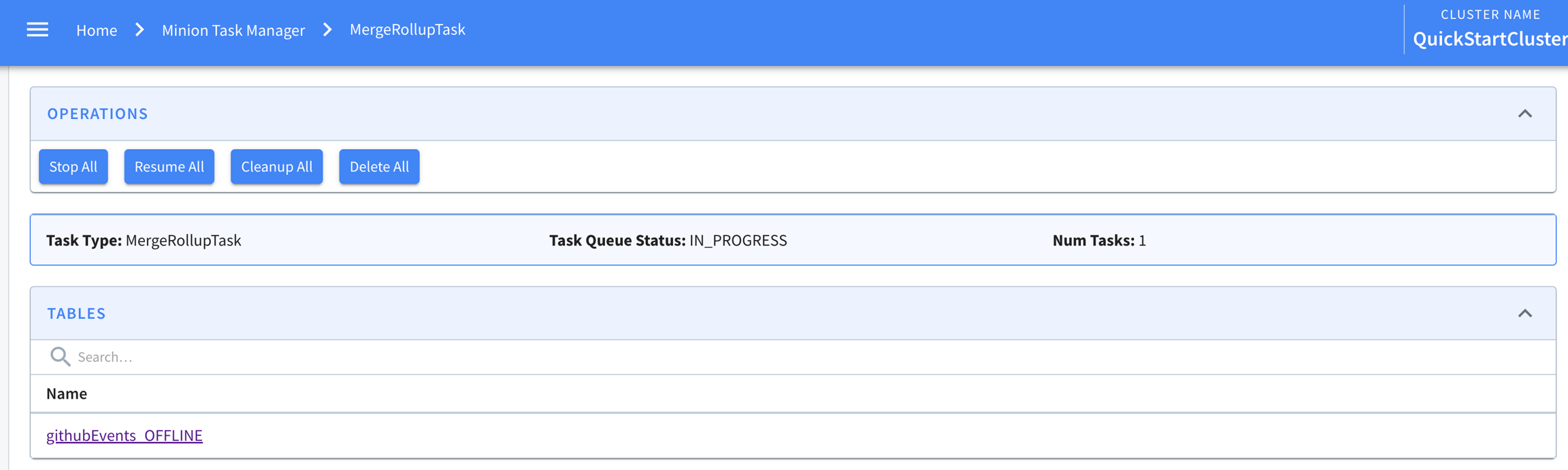
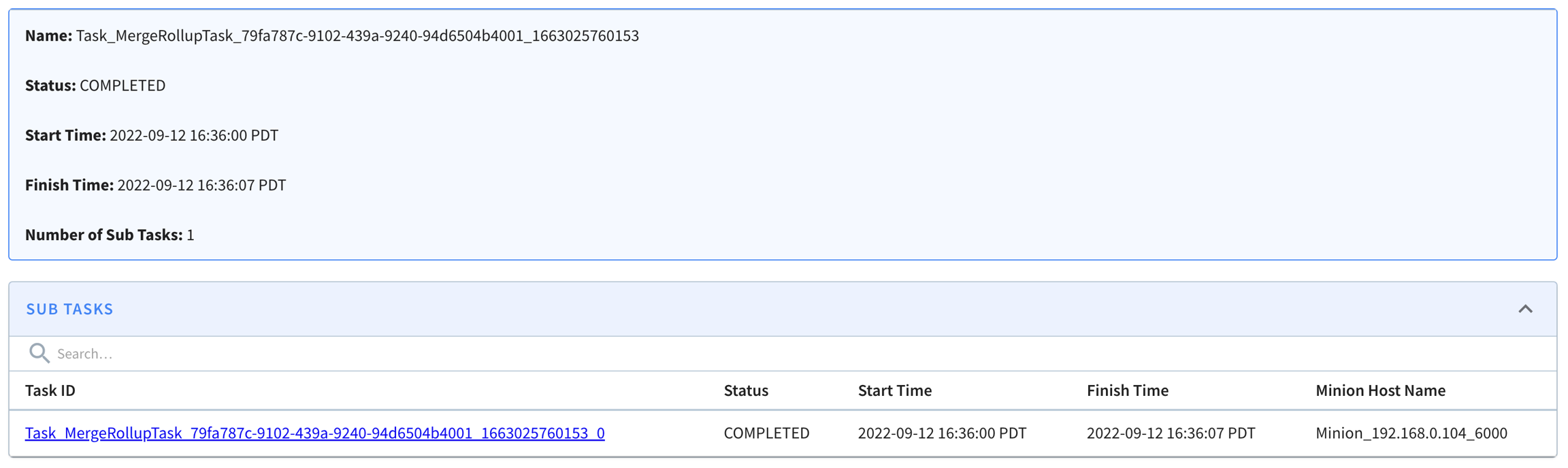
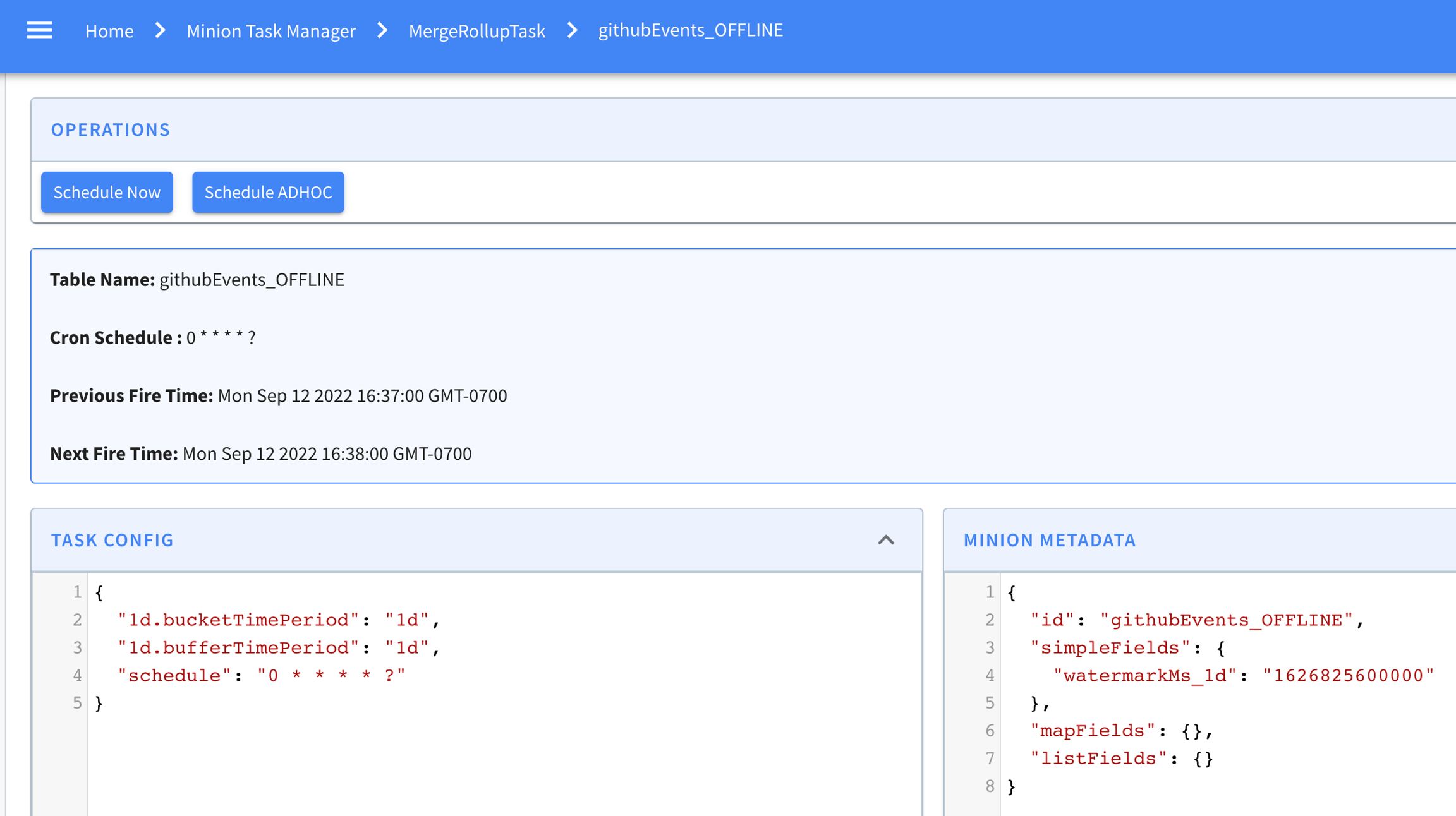
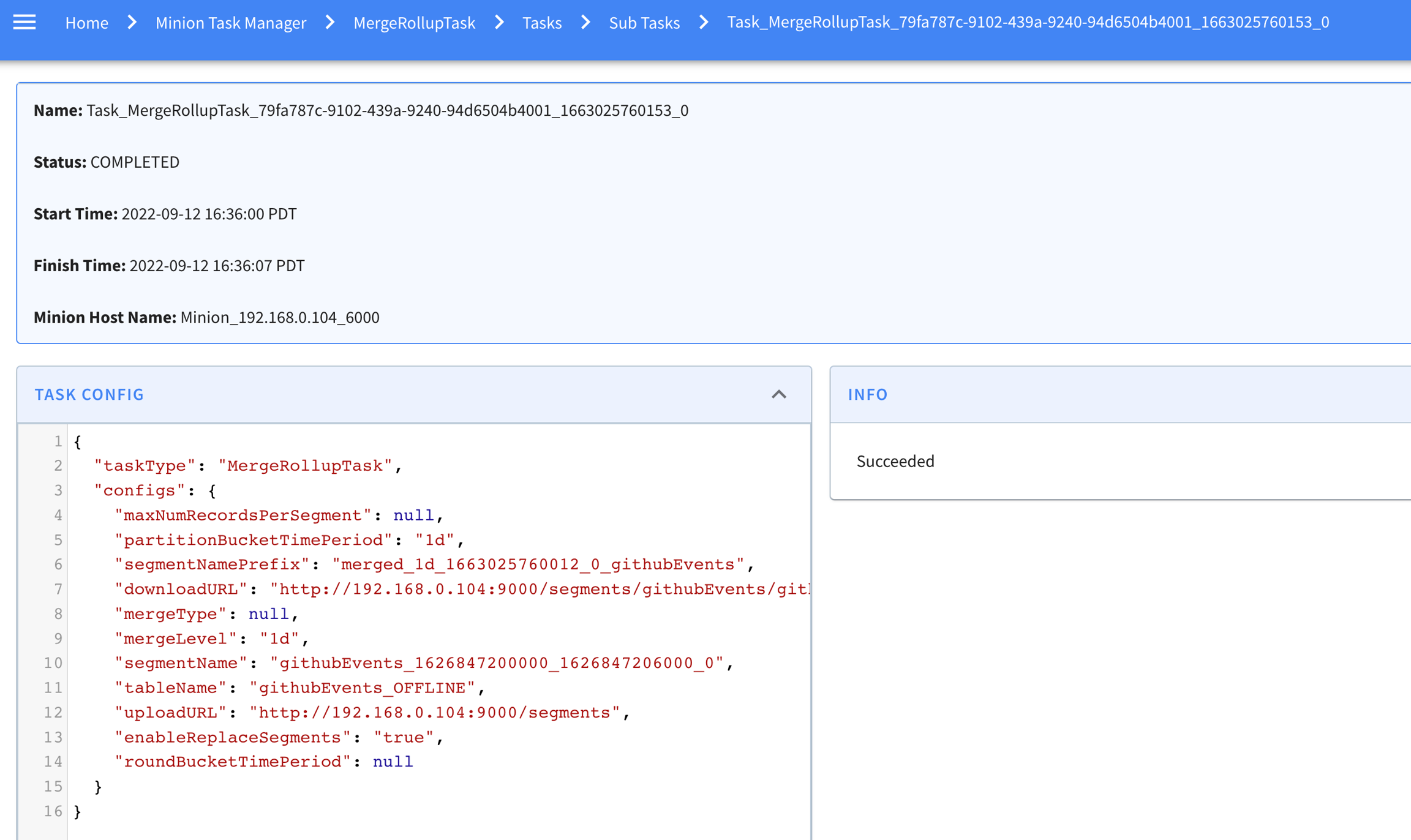
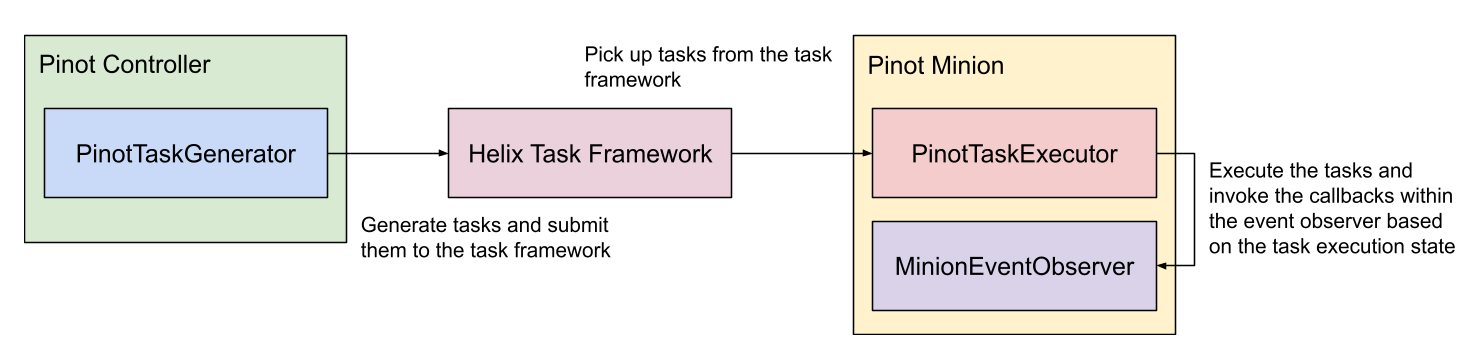
Explore the minion component in Apache Pinot, empowering efficient data movement and segment generation within Pinot clusters.
docker run \
--network=pinot-demo \
--name pinot-minion \
-d ${PINOT_IMAGE} StartMinion \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartMinion \
-zkAddress localhost:2181Usage: StartMinion
-help : Print this message. (required=false)
-minionHost <String> : Host name for minion. (required=false)
-minionPort <int> : Port number to start the minion at. (required=false)
-zkAddress <http> : HTTP address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Minion Starter Config file. (required=false)public interface PinotTaskGenerator {
/**
* Initializes the task generator.
*/
void init(ClusterInfoAccessor clusterInfoAccessor);
/**
* Returns the task type of the generator.
*/
String getTaskType();
/**
* Generates a list of tasks to schedule based on the given table configs.
*/
List<PinotTaskConfig> generateTasks(List<TableConfig> tableConfigs);
/**
* Returns the timeout in milliseconds for each task, 3600000 (1 hour) by default.
*/
default long getTaskTimeoutMs() {
return JobConfig.DEFAULT_TIMEOUT_PER_TASK;
}
/**
* Returns the maximum number of concurrent tasks allowed per instance, 1 by default.
*/
default int getNumConcurrentTasksPerInstance() {
return JobConfig.DEFAULT_NUM_CONCURRENT_TASKS_PER_INSTANCE;
}
/**
* Performs necessary cleanups (e.g. remove metrics) when the controller leadership changes.
*/
default void nonLeaderCleanUp() {
}
}public interface PinotTaskExecutorFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the executor.
*/
String getTaskType();
/**
* Creates a new task executor.
*/
PinotTaskExecutor create();
}public interface PinotTaskExecutor {
/**
* Executes the task based on the given task config and returns the execution result.
*/
Object executeTask(PinotTaskConfig pinotTaskConfig)
throws Exception;
/**
* Tries to cancel the task.
*/
void cancel();
}public interface MinionEventObserverFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the event observer.
*/
String getTaskType();
/**
* Creates a new task event observer.
*/
MinionEventObserver create();
}public interface MinionEventObserver {
/**
* Invoked when a minion task starts.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskStart(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task succeeds.
*
* @param pinotTaskConfig Pinot task config
* @param executionResult Execution result
*/
void notifyTaskSuccess(PinotTaskConfig pinotTaskConfig, @Nullable Object executionResult);
/**
* Invoked when a minion task gets cancelled.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskCancelled(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task encounters exception.
*
* @param pinotTaskConfig Pinot task config
* @param exception Exception encountered during execution
*/
void notifyTaskError(PinotTaskConfig pinotTaskConfig, Exception exception);
} "ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY",
"batchConfigMaps": [
{
"input.fs.className": "org.apache.pinot.plugin.filesystem.S3PinotFS",
"input.fs.prop.region": "us-west-2",
"input.fs.prop.secretKey": "....",
"input.fs.prop.accessKey": "....",
"inputDirURI": "s3://my.s3.bucket/batch/airlineStats/rawdata/",
"includeFileNamePattern": "glob:**/*.avro",
"excludeFileNamePattern": "glob:**/*.tmp",
"inputFormat": "avro"
}
]
}
},
"task": {
"taskTypeConfigsMap": {
"SegmentGenerationAndPushTask": {
"schedule": "0 */10 * * * ?",
"tableMaxNumTasks": "10"
}
}
}{
...
"task": {
"taskTypeConfigsMap": {
"myTask": {
"myProperty1": "value1",
"myProperty2": "value2"
}
}
}
}Using "POST /cluster/configs" API on CLUSTER tab in Swagger, with this payload
{
"RealtimeToOfflineSegmentsTask.timeoutMs": "600000",
"RealtimeToOfflineSegmentsTask.numConcurrentTasksPerInstance": "4"
} "task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bucketTimePeriod": "1h",
"bufferTimePeriod": "1h",
"schedule": "0 * * * * ?"
}
}
},