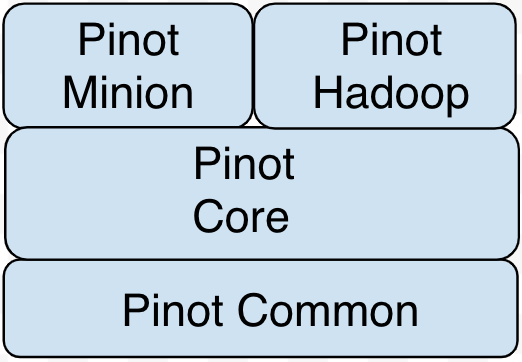
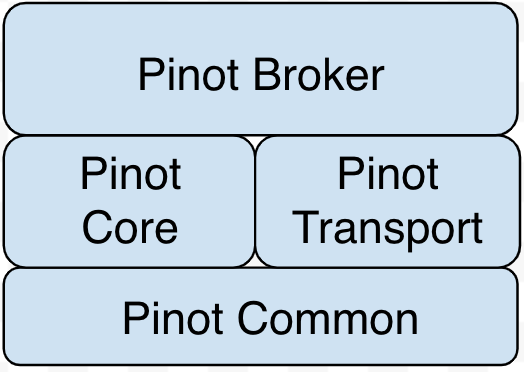
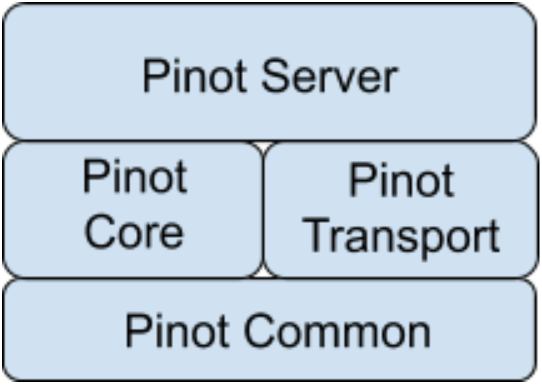
Before you begin to contribute, make sure you have reviewed Dev Environment Setup and Code Modules and Organization sections and that you have created your own fork of the pinot source code.
Pinot Enhancement Proposal Workflow
The Apache Pinot community encourages members to contribute to the overall growth and success of the project. All contributors are expected to follow the following guidelines when proposing an enhancement (aka PEP - Pinot Enhancement Proposal):
All enhancements, regardless of scope/size, must start with a . The issue should clearly state the following information:
Why the feature is needed (e.g. describing the use case).
It may also include an initial idea/proposal on how as well.
Once the Github issue is filed:
The PMC would decide if a detailed proposal/design-doc is required or can simply be followed by a PR.
There should be enough time (e.g. 5 business days) given for the PMC to review the issue/proposal before moving to implementation.
One +1 and zero -1 votes from the PMC may be used to proceed with the implementation.
The PMC would use the following guideline when deciding whether a PEP requires an explicit proposal/design doc, or can simply be followed by a PR that includes a link to the Github issue.
Any new major feature, subsystem, or piece of functionality.
Any change that may potentially create backward incompatibility:
Any change that impacts the public interfaces of the project.
If the requests get at least one +1 and no -1 from the PMC to directly go to the PR stage, the requestor can then submit the PR along with a link to the Github issue.
If the request requires a proposal, then the requestor is expected to provide a proposal design doc before submitting a PR for review. The design doc should have public read and comment access. (If your organization does not allow public access, look to other freely available platforms to host your document). The design doc must include the following:
Motivation: Describe the problem to be solved including the details on why such as use-case, etc.
Proposed Change: Describe the new thing that needs to be done. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences, depending on the scope of the change. Also, describe “How” with details and possible POC.
New or Changed Public Interfaces: impact to any of the "compatibility commitments" described above. We want to call these out in particular so everyone thinks about them.
The proposal/design doc should be in a google doc that has comment access enabled by default to any community member (should not require asking for permissions). Only exceptions are small features where the initial proposal in the issue is generally accepted. Once the proposal/design doc is approved (all questions/comments resolved), it must be transferred into a common Google Drive where all Pinot proposal/design docs must be submitted.
If there are meetings/discussions offline with a subset of members, the meeting notes should be captured and added to the doc.
General Guidelines
Smaller PRs that are easier to review
Create a design document
If your change is relatively minor, you can skip this step. If you are adding new major feature, we suggest that you add a design document and solicit comments from the community before submitting any code.
is a list of current design documents.
Create an issue for the change
Create a Pinot issue for the change you would like to make. Provide information on why the change is needed and how you plan to address it. Use the conversations on the issue as a way to validate assumptions and the right way to proceed. Be sure to review sections on and .
If you have a design document, refer to the design documents in your Issue. You may even want to create multiple issues depending on the extent of your change.
Once you are clear about what you want to do, proceed with the next steps listed below.
Create a branch for your change
Make the necessary changes. If the changes you plan to make are too big, make sure you break it down into smaller tasks.
Making the changes
Follow the recommendations/best-practices noted here when you are making changes.
Code documentation
Ensure your code is adequately documented. Some things to consider for documentation:
Always include class level java docs. At the top class level, we are looking for information about what functionality is provided by the class, what state is maintained by the class, whether there are concurrency/thread-safety concerns and any exceptional behavior that the class might exhibit.
Document public methods and their parameters.
Ensure there is adequate logging for positive paths as well as exceptional paths. As a corollary to this, ensure logs are not noisy.
Do not use System.out.println to log messages. Use the slf4j loggers.
Use logging levels correctly: set level to debug
Exceptions and Exception-Handling
Where possible, throw specific exceptions, preferably checked exceptions, so the callers can easily determine what the erroneous conditions that need to be handled are.
Avoid catching broad exceptions (i.e., catch (Exception e) blocks), except for when this is in the run() method of a thread/runnable.
Current Pinot code does not strictly adhere to this, but we would like to change this over time and adopt best practices around exception handling.
Backward and Forward compatibility changes
If you are making any changes to state stored, either in Zookeeper or in segments, make sure you consider both backward and forward compatibility issues.
For backward compatibility, consider cases where one component is using the new version and another is still on the old version. E.g., when the request format between broker and server is updated, consider resulting behaviors when a new broker is talking to an older server. Will it break?
For forward compatibility, consider rollback cases. E.g., consider what happens when state persisted by new code is handled by old code. Does the old code skip over new fields?
External libraries
Be cautious about pulling in external dependencies. You will need to consider multiple things when faced with a need to pull in a new library.
What capability is the addition of the library providing you with? Can existing libraries provide this functionality (may be with a little bit of effort)?
Is the external library maintained by an active community of contributors?
What are the licensing terms for the library. For more information about handling licenses, see .
Testing your changes
Automated tests are always recommended for contributions. Make sure you write tests so that:
You verify the correctness of your contribution. This serves as proof to you as well as the reviewers.
You future proof your contributions against code refactors or other changes. While this may not always be possible (see ), it's a good goal to aim for.
Identify a list of tests for the changes you have made. Depending on the scope of changes, you may need one or more of the following tests:
Unit Tests
Make sure your code has the necessary class or method level unit tests. It is important to write both positive case as well as negative case tests. Document your tests well and add meaningful assertions in the tests; when the assertions fail, ensure that the right messages are logged with information that allows other to debug.
Integration Tests
Add integration tests to cover End-to-End paths without relying on mocking (see note below). You MUST
Testing Guidelines
Mocking
Use to mock classes to control specific behaviors - e.g., simulate various error conditions.
Validate assumptions in tests
Make sure that adequate asserts are added in the tests to verify that the tests are passing for the right reasons.
Write reliable tests
Make sure you are writing tests that are reliable. If the tests depend on asynchronous events to be fired, do not add sleep to your tests. Where possible, use appropriate mocking or condition based triggers.
License Headers for newly added files
All source code files should have license headers. To automatically add the header for any new file you plan to checkin, run in pinot top-level folder:
Note
If you checkin third-party code or files, make sure you review Apache guidelines:
Once you determine the code you are pulling in adhere to the guidelines above, go ahead pull the changes in. Do not add license headers for them. Follow these instructions to ensure we are compliant with Apache Licensing process:
Under pinot/licenses add a LICENSE-<newlib> file that has the license terms of the included library.
Update the pinot/LICENSE file to indicate the newly added library file paths under the corresponding supported Licenses.
Update the exclusion rules for
If attention to the licensing terms in not paid early on, they will be caught much later in the process, when we prepare to make a new release. Updating code at that time to work with the right libraries at that time might require bigger refactoring changes and delay the release process.
Creating a Pull Request (PR)
Verifying code-style
Run the following command to verify the code-style before posting a PR
Run tests
Before you create a review request for the changes, make sure you have run the corresponding unit tests for your changes. You can run individual tests via the IDE or via maven command-line. Finally run all tests locally by running mvn clean install -Pbin-dist.
For changes that are related to performance issues or race conditions, it is hard to write reliable tests, so we recommend running manual stress tests to validate the changes. You MUST note the manual tests done in the PR description.
Once you receive comments on github on your changes, be sure to respond to them on github and address the concerns. If any discussions happen offline for the changes in question, make sure to capture the outcome of the discussion, so others can follow along as well.
It is possible that while your change is being reviewed, other changes were made to the master branch. Be sure to pull rebase your change on the new changes thus:
When you have addressed all comments and have an approved PR, one of the committers can merge your PR.
After your change is merged, check to see if any documentation needs to be updated. If so, create a PR for documentation.
Update Documentation
Usually for new features, functionalities, API changes, documentation update is required to keep users up to date and keep track of our development.
Follow this link to accordingly