Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
{
"tableIndexConfig": {
"invertedIndexColumns": [
"column_name",
...
],
...
}
}{
"tableIndexConfig": {
"sortedColumn": [
"column_name"
],
...
}
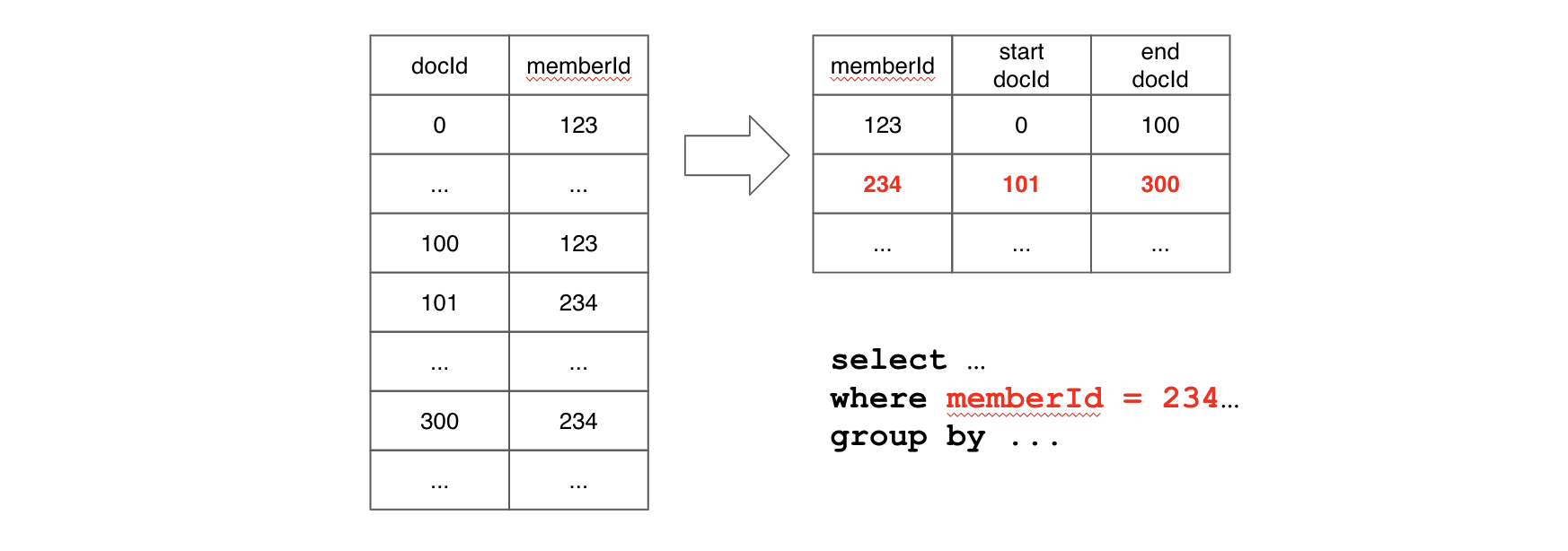
}$ grep memberId <segment_name>/v3/metadata.properties | grep isSorted
column.memberId.isSorted = truecurl -X GET \
"http://localhost:9000/segments/baseballStats/metadata?columns=playerID&columns=teamID" \
-H "accept: application/json" 2>/dev/null | \
jq -c '.[] | . as $parent |
.columns[] |
[$parent .segmentName, .columnName, .sorted]'["baseballStats_OFFLINE_0","teamID",false]
["baseballStats_OFFLINE_0","playerID",false]{
"tableIndexConfig": {
"noDictionaryColumns": [
"column_name",
...
],
...
}
}"fieldConfigList":[
{
"name":"columnA",
"encodingType":"DICTIONARY",
"indexTypes":["INVERTED"],
"properties": {
"forwardIndexDisabled": "true"
}
}
]SELECT columnA
FROM myTable
WHERE columnA = 10SELECT *
FROM myTableSELECT SUM(columnB)
FROM myTable
GROUP BY columnASELECT SUM(columnB), columnA
FROM myTable
GROUP BY columnA
ORDER BY columnASELECT MIN(columnA)
FROM myTable
GROUP BY columnB
HAVING MIN(columnA) > 100
ORDER BY columnBSELECT SUM(columnA), AVG(columnA)
FROM myTableSELECT MAX(ADD(columnA, columnB))
FROM myTableSELECT DISTINCT columnA
FROM myTableSELECT columnB
FROM myTable
WHERE columnA > 1000This page describes configuring the bloom filter for Apache Pinot
This page describes configuring the range index for Apache Pinot
SELECT COUNT(*)
FROM baseballStats
WHERE hits > 11{
"tableIndexConfig": {
"rangeIndexColumns": [
"column_name",
...
],
...
}
}10.05fppSELECT COUNT(*)
FROM baseballStats
WHERE playerID = 12345"tableIndexConfig": {
"invertedIndexColumns": ["foo"],
...
}"tableIndexConfig": {
"invertedIndexColumns": ["foo", "bar"],
...
}curl -X POST \
"http://localhost:9000/segments/myTable/reload" \
-H "accept: application/json"SELECT COUNT(*) FROM Foo WHERE TEXT_CONTAINS (<column_name>, <search_expression>)SELECT COUNT(*) FROM Foo WHERE TEXT_CONTAINS (<column_name>, "foo.*")SELECT COUNT(*) FROM Foo WHERE TEXT_CONTAINS (<column_name>, ".*bar")SELECT COUNT(*) FROM Foo WHERE TEXT_CONTAINS (<column_name>, "foo")SELECT COUNT(*) FROM Foo WHERE TEXT_CONTAINS ("col1", "foo") AND TEXT_CONTAINS ("col2", "bar")"fieldConfigList":[
{
"name":"text_col_1",
"encodingType":"RAW",
"indexTypes": ["TEXT"],
"properties":{"fstType":"native"}
}
]{
"tableIndexConfig": {
"bloomFilterColumns": [
"playerID",
...
],
...
},
...
}{
"tableIndexConfig": {
"bloomFilterConfigs": {
"playerID": {
"fpp": 0.01,
"maxSizeInBytes": 1000000,
"loadOnHeap": true
},
...
},
...
},
...
}TIMESTAMP data type introduced in the Pinot 0.8.0 release stores value as millisecond epoch long value.select count(*),
datetrunc('WEEK', ts) as tsWeek
from airlineStats
WHERE tsWeek > fromDateTime('2014-01-16', 'yyyy-MM-dd')
group by tsWeek
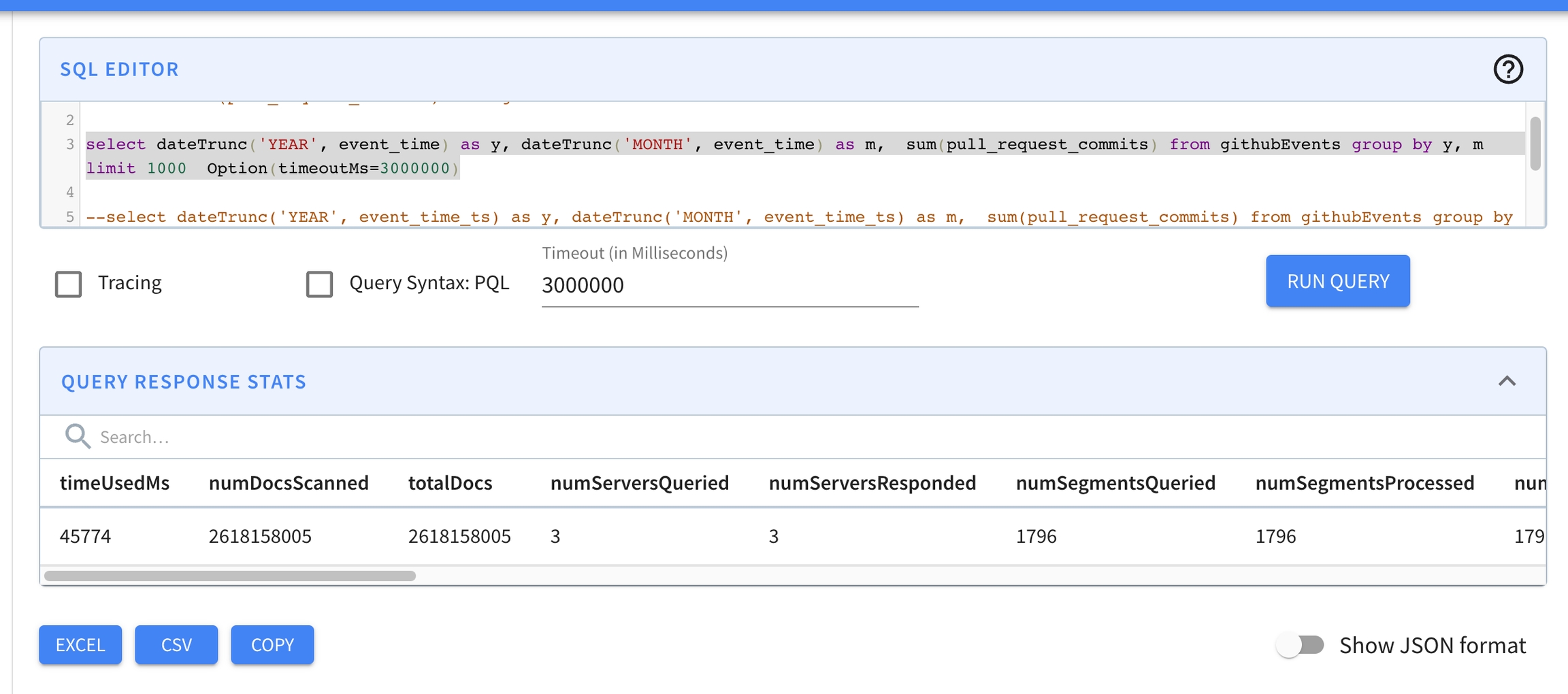
limit 10select dateTrunc('YEAR', event_time) as y,
dateTrunc('MONTH', event_time) as m,
sum(pull_request_commits)
from githubEvents
group by y, m
limit 1000
Option(timeoutMs=3000000){
"tableName": "airlineStats",
"tableType": "OFFLINE",
"segmentsConfig": {
"timeColumnName": "DaysSinceEpoch",
"timeType": "DAYS",
"segmentPushType": "APPEND",
"segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy",
"replication": "1"
},
"tenants": {},
"fieldConfigList": [
{
"name": "ts",
"encodingType": "DICTIONARY",
"indexTypes": ["TIMESTAMP"],
"timestampConfig": {
"granularities": [
"DAY",
"WEEK",
"MONTH"
]
}
}
],
"tableIndexConfig": {
"loadMode": "MMAP"
},
"metadata": {
"customConfigs": {}
},
"ingestionConfig": {}
}
ST_LinestringST_PolygonST_MultiPolygonST_Distance(loc1, loc2) < x{
"dataType": "BYTES",
"name": "location_st_point",
"transformFunction": "toSphericalGeography(stPoint(lon,lat))"
}{
"fieldConfigList": [
{
"name": "location_st_point",
"encodingType":"RAW",
"indexTypes":["H3"],
"properties": {
"resolutions": "5"
}
}
],
"tableIndexConfig": {
"loadMode": "MMAP",
"noDictionaryColumns": [
"location_st_point"
]
},
}SELECT address, ST_DISTANCE(location_st_point, ST_Point(-122, 37, 1))
FROM starbucksStores
WHERE ST_DISTANCE(location_st_point, ST_Point(-122, 37, 1)) < 5000
limit 1000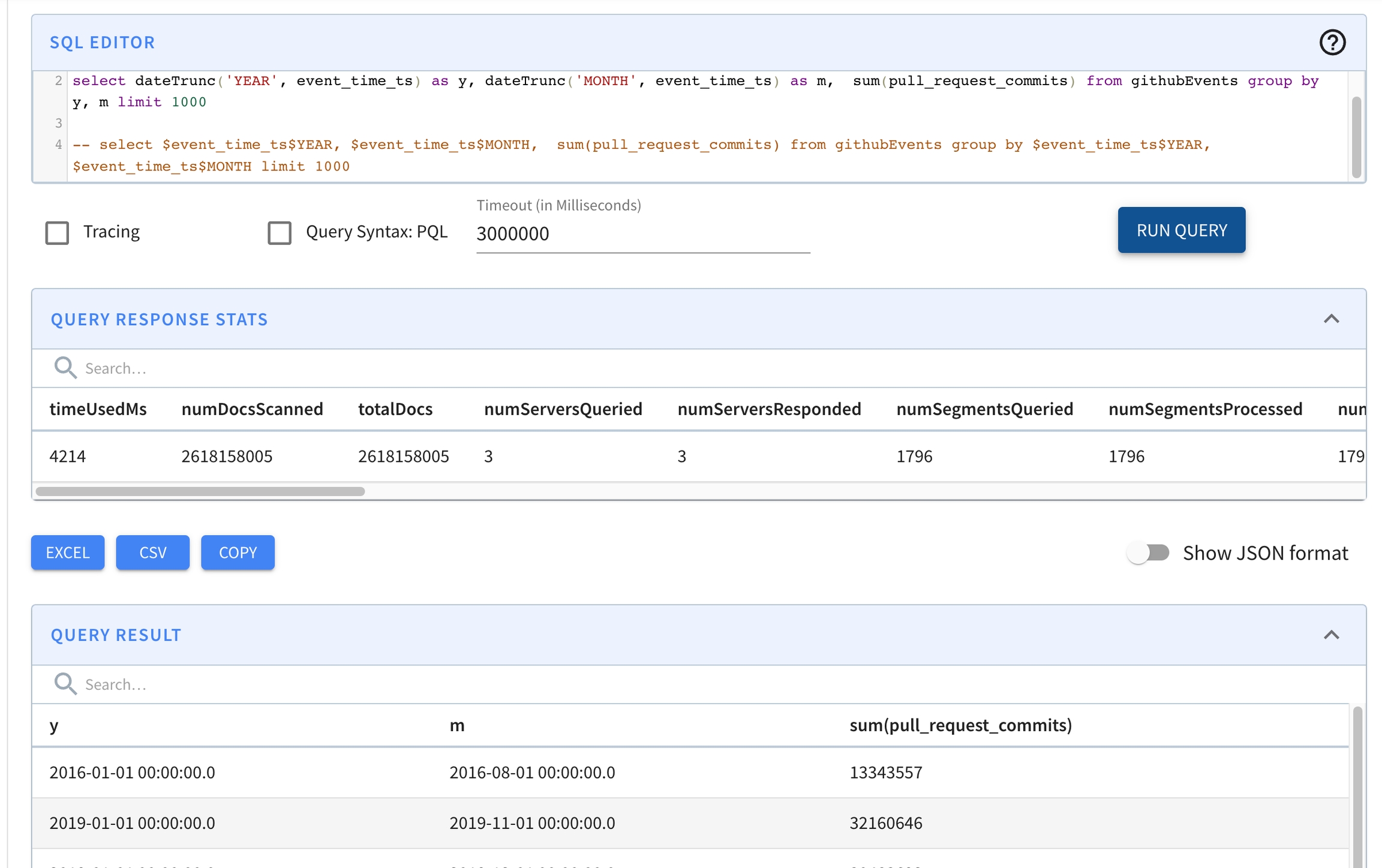
This page describes configuring the JSON index for Apache Pinot.
0.12.0:{
"name": "adam",
"age": 30,
"country": "us",
"addresses":
[
{
"number" : 112,
"street" : "main st",
"country" : "us"
},
{
"number" : 2,
"street" : "second st",
"country" : "us"
},
{
"number" : 3,
"street" : "third st",
"country" : "ca"
}
]
}SELECT *
FROM mytable
WHERE JSON_EXTRACT_SCALAR(person, '$.name', 'STRING') = 'adam'{
"tableIndexConfig": {
"jsonIndexConfigs": {
"person": {
"maxLevels": 2,
"excludeArray": false,
"disableCrossArrayUnnest": true,
"includePaths": null,
"excludePaths": null,
"excludeFields": null
},
...
},
...
}
}{
"name": "adam",
"age": 20,
"addresses": [
{
"country": "us",
"street": "main st",
"number": 1
},
{
"country": "ca",
"street": "second st",
"number": 2
}
],
"skills": [
"english",
"programming"
]
}{
"name": "adam",
"age": 20,
"addresses[0].country": "us",
"addresses[0].street": "main st",
"addresses[0].number": 1,
"skills[0]": "english"
},
{
"name": "adam",
"age": 20,
"addresses[0].country": "us",
"addresses[0].street": "main st",
"addresses[0].number": 1,
"skills[1]": "programming"
},
{
"name": "adam",
"age": 20,
"addresses[1].country": "ca",
"addresses[1].street": "second st",
"addresses[1].number": 2,
"skills[0]": "english"
},
{
"name": "adam",
"age": 20,
"addresses[1].country": "ca",
"addresses[1].street": "second st",
"addresses[1].number": 2,
"skills[1]": "programming"
}{
"name": "adam",
"age": 20
}{
"name": "adam",
"age": 20,
"skills[0]": "english"
},
{
"name": "adam",
"age": 20,
"skills[1]": "programming"
}{
"name": "adam",
"age": 20
}{
"name": "adam",
"age": 20,
"addresses[0].country": "us",
"addresses[0].street": "main st",
"addresses[0].number": 1
},
{
"name": "adam",
"age": 20,
"addresses[0].country": "us",
"addresses[0].street": "main st",
"addresses[0].number": 1
},
{
"name": "adam",
"age": 20,
"skills[0]": "english"
},
{
"name": "adam",
"age": 20,
"skills[1]": "programming"
}{
"name": "adam",
"addresses[0].country": "us"
},
{
"name": "adam",
"addresses[1].country": "ca"
}{
"name": "adam",
"addresses[0].country": "us",
"addresses[0].street": "main st",
"skills[0]": "english"
},
{
"name": "adam",
"addresses[0].country": "us",
"addresses[0].street": "main st",
"skills[1]": "programming"
},
{
"name": "adam",
"addresses[1].country": "ca",
"addresses[1].street": "second st",
"skills[0]": "english"
},
{
"name": "adam",
"addresses[1].country": "ca",
"addresses[1].street": "second st",
"skills[1]": "programming"
}{
"name": "adam",
"addresses[0].country": "us",
"addresses[0].number": 1,
"skills[0]": "english"
},
{
"name": "adam",
"addresses[0].country": "us",
"addresses[0].number": 1,
"skills[1]": "programming"
},
{
"name": "adam",
"addresses[1].country": "ca",
"addresses[1].number": 2,
"skills[0]": "english"
},
{
"name": "adam",
"addresses[1].country": "ca",
"addresses[1].number": 2,
"skills[1]": "programming"
}{
"tableIndexConfig": {
"jsonIndexColumns": [
"person",
...
],
...
}
}SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.name"=''adam'' AND "$.addresses[*].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].number"=112')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.phone" IS NOT NULL')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].floor" IS NULL')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].street"=''main st'' AND "$.addresses[*].country"=''ca''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[*].street"=''main st''') AND JSON_MATCH(person, '"$.addresses[*].country"=''ca''')SELECT ...
FROM mytable
WHERE JSON_MATCH(person, '"$.addresses[0].street"=''main st''') AND JSON_MATCH(person, '"$.addresses[1].street"=''second st''')["item1", "item2", "item3"]SELECT ...
FROM mytable
WHERE JSON_MATCH(arrayCol, '"$[*]"=''item1''')SELECT ...
FROM mytable
WHERE JSON_MATCH(arrayCol, '"$[1]"=''item2''')123
1.23
"Hello World"SELECT ...
FROM mytable
WHERE JSON_MATCH(valueCol, '"$"=123')nullSELECT ...
FROM mytable
WHERE JSON_MATCH(nullableCol, '"$" IS NULL')This page talks about support for text search in Pinot.
SELECT COUNT(*)
FROM Foo
WHERE STRING_COL = 'ABCDCD'
AND INT_COL > 2000
SELECT COUNT(*)
FROM Foo
WHERE TEXT_MATCH (<column_name>, '<search_expression>')109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-
109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
95.29.198.15 - - [12/Dec/2015:18:32:10 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
95.29.198.15 - - [12/Dec/2015:18:32:11 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
109.184.11.34 - - [12/Dec/2015:18:32:56 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
109.184.11.34 - - [12/Dec/2015:18:32:56 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
91.227.29.79 - - [12/Dec/2015:18:33:51 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'GET')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'post AND administrator AND index')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(ACCESS_LOG_COL, 'post AND administrator AND index AND firefox')Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Java, Python, C++, Machine learning, building and deploying large scale production systems, concurrency, multi-threading, CPU processing
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
Amazon EC2, AWS, hadoop, big data, spark, building high performance scalable systems, building and deploying large scale production systems, concurrency, multi-threading, Java, C++, CPU processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Kubernetes, cluster management, operating systems, concurrency, multi-threading, apache airflow, Apache Spark,
Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systems
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND "gpu processing"')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" AND (Java C++)')SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560988800000 AND 1568764800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560988800000 AND 1568764800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1545436800000 AND 1553212800000 GROUP BY dimensionCol3 TOP 2500
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1537228800000 AND 1537660800000 GROUP BY dimensionCol3 TOP 2500
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1561366800000 AND 1561370399999 AND dimensionCol3 = 2019062409 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1563807600000 AND 1563811199999 AND dimensionCol3 = 2019072215 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1563811200000 AND 1563814799999 AND dimensionCol3 = 2019072216 LIMIT 10000
SELECT dimensionCol2, dimensionCol4, timestamp, dimensionCol5, dimensionCol6 FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1566327600000 AND 1566329400000 AND dimensionCol3 = 2019082019 LIMIT 10000
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560834000000 AND 1560837599999 AND dimensionCol3 = 2019061805 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560870000000 AND 1560871800000 AND dimensionCol3 = 2019061815 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560871800001 AND 1560873599999 AND dimensionCol3 = 2019061815 LIMIT 0
SELECT count(dimensionCol2) FROM FOO WHERE dimensionCol1 = 18616904 AND timestamp BETWEEN 1560873600000 AND 1560877199999 AND dimensionCol3 = 2019061816 LIMIT 0SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"group by"')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"select count"')SELECT COUNT(*)
FROM MyTable
WHERE TEXT_MATCH(QUERY_LOG_COL, '"timestamp between" AND "group by"')"fieldConfigList":[
{
"name":"text_col_1",
"encodingType":"RAW",
"indexTypes":["TEXT"]
},
{
"name":"text_col_2",
"encodingType":"RAW",
"indexTypes":["TEXT"]
}
]"tableIndexConfig": {
"noDictionaryColumns": [
"text_col_1",
"text_col_2"
]}"a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it",
"no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "than", "there", "these",
"they", "this", "to", "was", "will", "with", "those""fieldConfigList":[
{
"name":"text_col_1",
"encodingType":"RAW",
"indexType":"TEXT",
"properties": {
"stopWordInclude": "incl1, incl2, incl3",
"stopWordExclude": "it"
}
}
]SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...)
SELECT * FROM Foo WHERE TEXT_MATCH(...)SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...) AND some_other_column_1 > 20000
SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(...) AND some_other_column_1 > 20000 AND some_other_column_2 < 100000SELECT COUNT(*) FROM Foo WHERE TEXT_MATCH(text_col_1, ....) AND TEXT_MATCH(text_col_2, ...)Java, C++, worked on open source projects, coursera machine learning
Machine learning, Tensor flow, Java, Stanford university,
Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Java, Python, C++, Machine learning, building and deploying large scale production systems, concurrency, multi-threading, CPU processing
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
Amazon EC2, AWS, hadoop, big data, spark, building high performance scalable systems, building and deploying large scale production systems, concurrency, multi-threading, Java, C++, CPU processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Kubernetes, cluster management, operating systems, concurrency, multi-threading, apache airflow, Apache Spark,
Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systems
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,
C++, Java, Python, realtime streaming systems, Machine learning, spark, Kubernetes, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distribution
Database engine, OLAP systems, OLTP transaction processing at large scale, concurrency, multi-threading, GO, building large scale systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Distributed systems"')Distributed systems, Java, C++, Go, distributed query engines for analytics and data warehouses, Machine learning, spark, Kubernetes, transaction processing
Distributed systems, database development, columnar query engine, database kernel, storage, indexing and transaction processing, building large scale systems
Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
Distributed systems, Java, database engine, cluster management, docker image building and distribution
Distributed systems, Apache Kafka, publish-subscribe, building and deploying large scale production systems, concurrency, multi-threading, C++, CPU processing, Java
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distributionDistributed data processing, systems design experienceSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"query processing"')Apache spark, Java, C++, query processing, transaction processing, distributed storage, concurrency, multi-threading, apache airflow
Databases, columnar query processing, Apache Arrow, distributed systems, Machine learning, cluster management, docker image building and distribution"SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, 'Java')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND "Tensor Flow"')Machine learning, Tensor flow, Java, Stanford university,
C++, Python, Tensor flow, database kernel, storage, indexing and transaction processing, building large scale systems, Machine learning
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"Machine learning" AND gpu AND python')CUDA, GPU, Python, Machine learning, database kernel, storage, indexing and transaction processing, building large scale systems
CUDA, GPU processing, Tensor flow, Pandas, Python, Jupyter notebook, spark, Machine learning, building high performance scalable systemsSELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" Java C++')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, '"distributed systems" AND (Java C++)')SELECT SKILLS_COL
FROM MyTable
WHERE TEXT_MATCH(SKILLS_COL, 'stream*')Distributed systems, Java, realtime streaming systems, Machine learning, spark, Kubernetes, distributed storage, concurrency, multi-threading
Big data stream processing, Apache Flink, Apache Beam, database kernel, distributed query engines for analytics and data warehouses
Realtime stream processing, publish subscribe, columnar processing for data warehouses, concurrency, Java, multi-threading, C++,
C++, Java, Python, realtime streaming systems, Machine learning, spark, Kubernetes, transaction processing, distributed storage, concurrency, multi-threading, apache airflowSELECT SKILLS_COL
FROM MyTable
WHERE text_match(SKILLS_COL, '/.*Exception/')TEXT_MATCH(column, '"machine learning"')TEXT_MATCH(column, '"Java C++"')TEXT_MATCH(column, 'Java AND C++')This page describes the indexing techniques available in Apache Pinot.
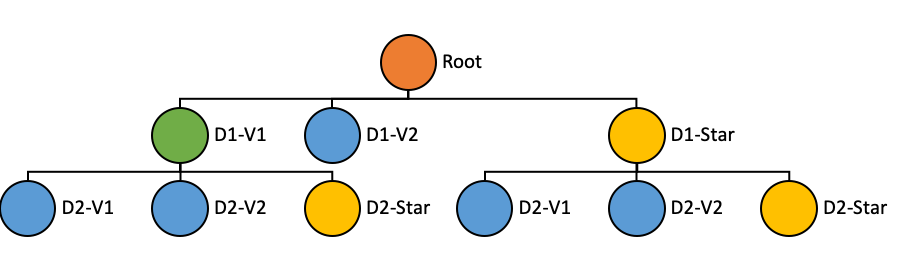
SELECT SUM(Impressions)
FROM myTable
WHERE Country = 'USA'
AND Browser = 'Chrome'
GROUP BY Locale"tableIndexConfig": {
"starTreeIndexConfigs": [{
"dimensionsSplitOrder": [
"Country",
"Browser",
"Locale"
],
"skipStarNodeCreationForDimensions": [
],
"functionColumnPairs": [
"SUM__Impressions"
],
"maxLeafRecords": 10000
}],
...
}