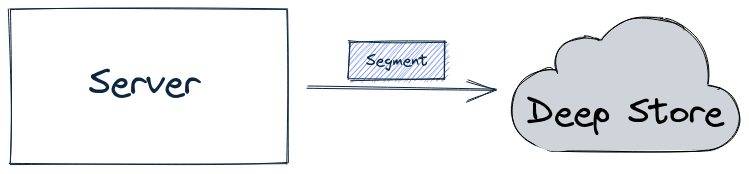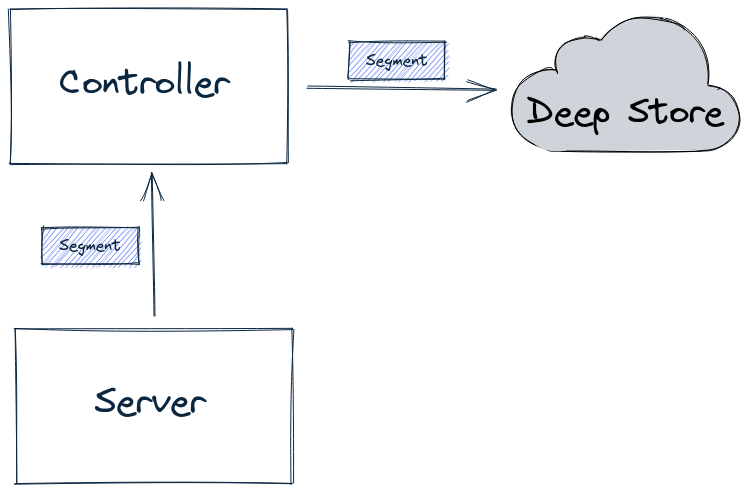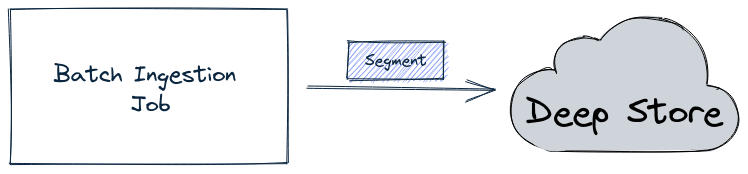
In this Apache Pinot concepts guide, we'll learn how segment retention works.
Discover the segment component in Apache Pinot for efficient data storage and querying within Pinot clusters, enabling optimized data processing and analysis.
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 'examples/batch/baseballStats/rawdata'
includeFileNamePattern: 'glob:**/*.csv'
excludeFileNamePattern: 'glob:**/*.tmp'
outputDirURI: 'examples/batch/baseballStats/segments'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
tableSpec:
tableName: 'baseballStats'
schemaURI: 'http://localhost:9000/tables/baseballStats/schema'
tableConfigURI: 'http://localhost:9000/tables/baseballStats'
segmentNameGeneratorSpec:
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yamlSegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**/*.avro
inputDirURI: examples/batch/airlineStats/rawdata
jobType: SegmentCreationAndTarPush
outputDirURI: examples/batch/airlineStats/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://pinot-controller:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
pushJobSpec: {pushAttempts: 2, pushParallelism: 1, pushRetryIntervalMillis: 1000,
segmentUriPrefix: null, segmentUriSuffix: null}
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.avro.AvroRecordReader,
configClassName: null, configs: null, dataFormat: avro}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://pinot-controller:9000/tables/airlineStats/schema',
tableConfigURI: 'http://pinot-controller:9000/tables/airlineStats', tableName: airlineStats}
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Finished building StatsCollector!
Collected stats for 403 documents
Created dictionary for INT column: FlightNum with cardinality: 386, range: 14 to 7389
Using fixed bytes value dictionary for column: Origin, size: 294
Created dictionary for STRING column: Origin with cardinality: 98, max length in bytes: 3, range: ABQ to VPS
Created dictionary for INT column: Quarter with cardinality: 1, range: 1 to 1
Created dictionary for INT column: LateAircraftDelay with cardinality: 50, range: -2147483648 to 303
......
......
Pushing segment: airlineStats_OFFLINE_16085_16085_29 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16085_16085_29 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16085_16085_29 of table: airlineStats"}
Pushing segment: airlineStats_OFFLINE_16084_16084_30 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16084_16084_30 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16084_16084_30 of table: airlineStats"}bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile examples/batch/airlineStats/ingestionJobSpec.yamlinputDirURI: 'examples/batch/airlineStats/rawdata/${year}/${month}/${day}'
outputDirURI: 'examples/batch/airlineStats/segments/${year}/${month}/${day}'docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yaml
-values year=2014 month=01 day=03docker run \
--network pinot-demo \
--name=loading-airlineStats-data-to-kafka \
${PINOT_IMAGE} StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList kafka:9092 -zkAddress pinot-zookeeper:2181/kafkabin/pinot-admin.sh StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList localhost:19092 -zkAddress localhost:2191/kafka