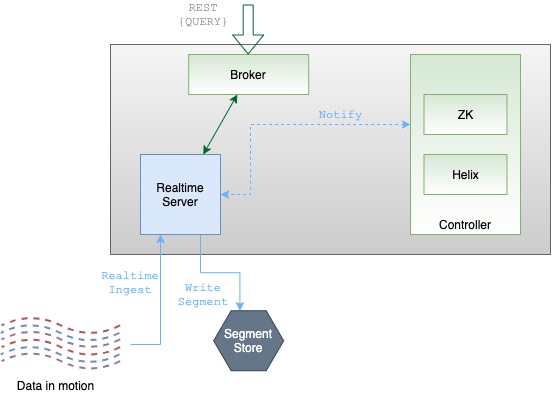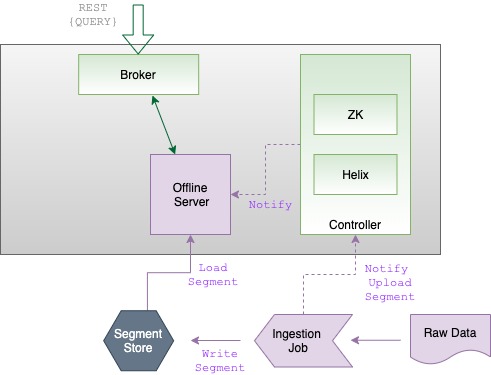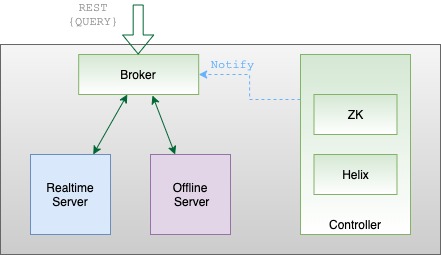
Discover the tenant component of Apache Pinot, which facilitates efficient data isolation and resource management within Pinot clusters.
docker run \
--network=pinot-demo \
--name pinot-server \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartServer \
-zkAddress localhost:2181Usage: StartServer
-serverHost <String> : Host name for controller. (required=false)
-serverPort <int> : Port number to start the server at. (required=false)
-serverAdminPort <int> : Port number to serve the server admin API at. (required=false)
-dataDir <string> : Path to directory containing data. (required=false)
-segmentDir <string> : Path to directory containing segments. (required=false)
-zkAddress <http> : Http address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Broker Starter Config file. (required=false)
-help : Print this message. (required=false)docker run \
--network=pinot-demo \
--name pinot-broker \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
-brokerPort 7000Table ATable Bbin/pinot-admin.sh AddTenant \
-name sampleBrokerTenant
-role BROKER
-instanceCount 3 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-broker-tenant.json localhost:9000/tenantsbin/pinot-admin.sh AddTenant \
-name sampleServerTenant \
-role SERVER \
-offlineInstanceCount 1 \
-realtimeInstanceCount 1 -execcurl -i -X POST -H 'Content-Type: application/json' -d @sample-server-tenant.json localhost:9000/tenants"tenants": {
"broker": "brokerTenantName",
"server": "serverTenantName"
}{
"tenantRole" : "BROKER",
"tenantName" : "sampleBrokerTenant",
"numberOfInstances" : 3
}{
"tenantRole" : "SERVER",
"tenantName" : "sampleServerTenant",
"offlineInstances" : 1,
"realtimeInstances" : 1
}curl -X GET "http://localhost:9000/periodictask/names" -H "accept: application/json"
[
"RetentionManager",
"OfflineSegmentIntervalChecker",
"RealtimeSegmentValidationManager",
"BrokerResourceValidationManager",
"SegmentStatusChecker",
"SegmentRelocator",
"StaleInstancesCleanupTask",
"TaskMetricsEmitter"
]curl -X GET "http://localhost:9000/periodictask/run?taskname=SegmentStatusChecker&tableName=jsontypetable&type=OFFLINE" -H "accept: application/json"
{
"Log Request Id": "api-09630c07",
"Controllers notified": true
}docker run \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartController \
-zkAddress localhost:2181 \
-clusterName PinotCluster \
-controllerPort 9000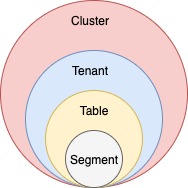
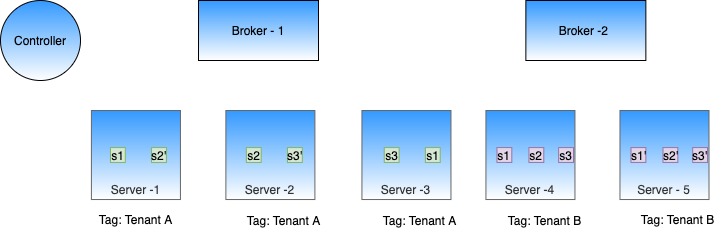
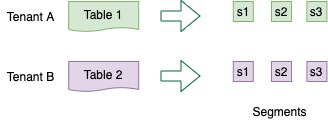
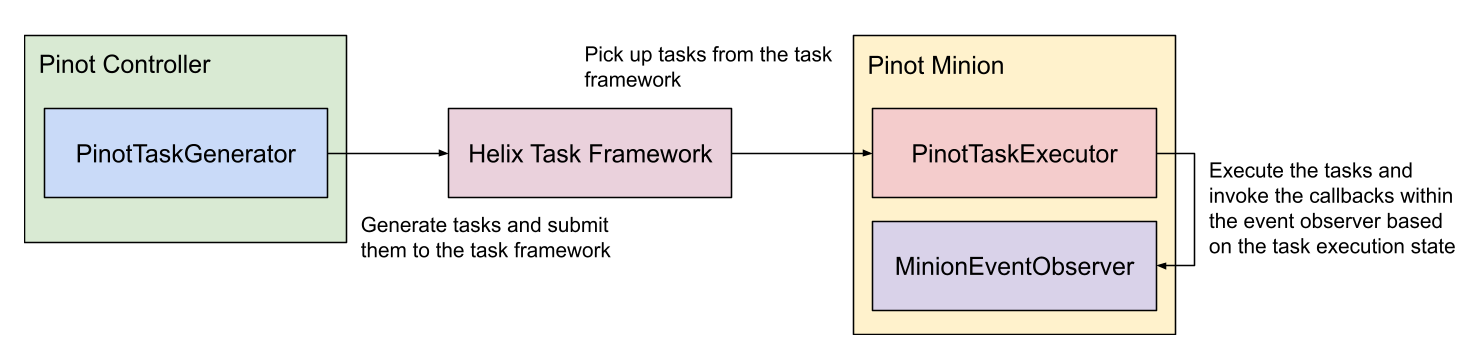
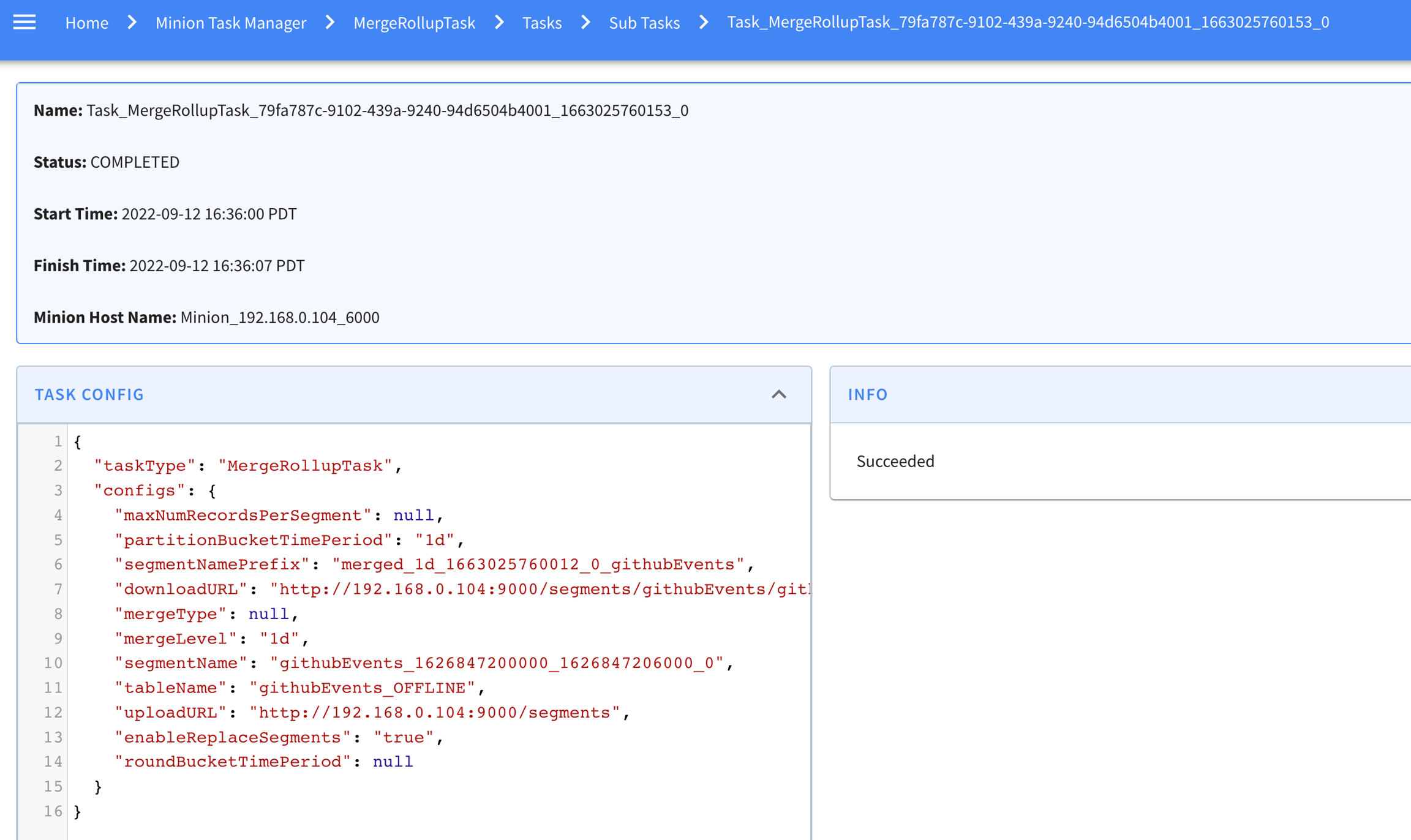
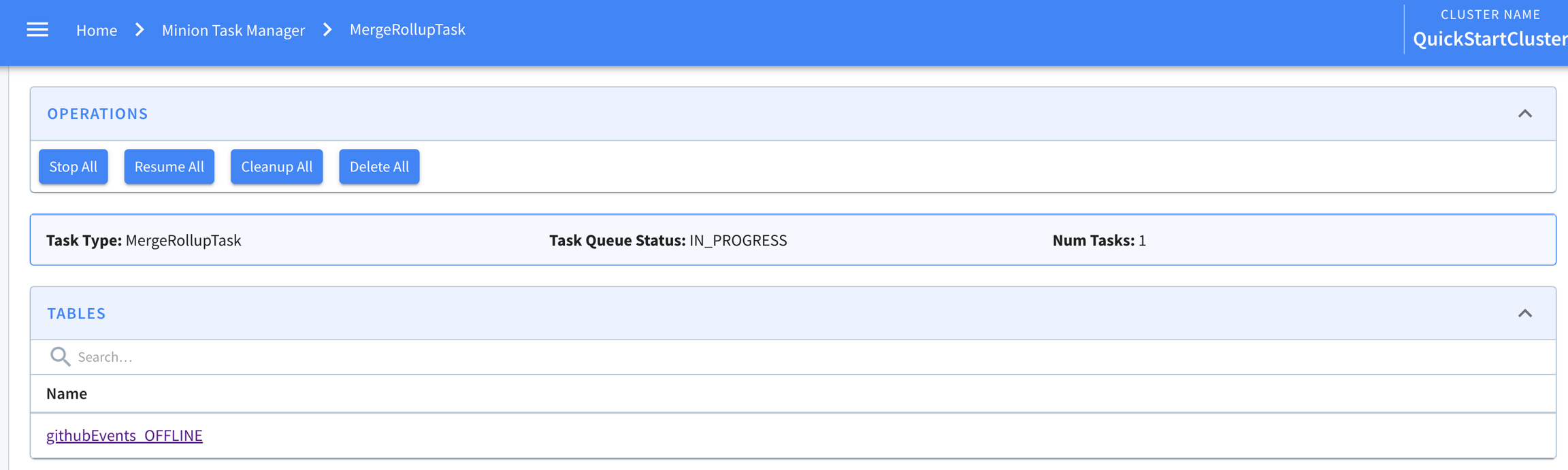
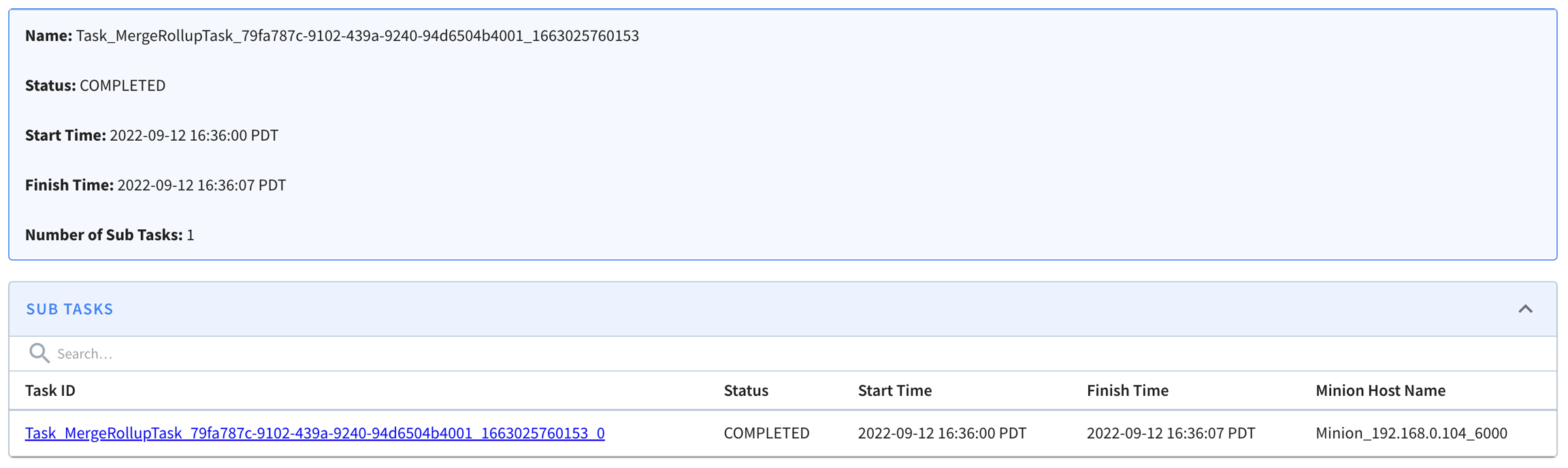
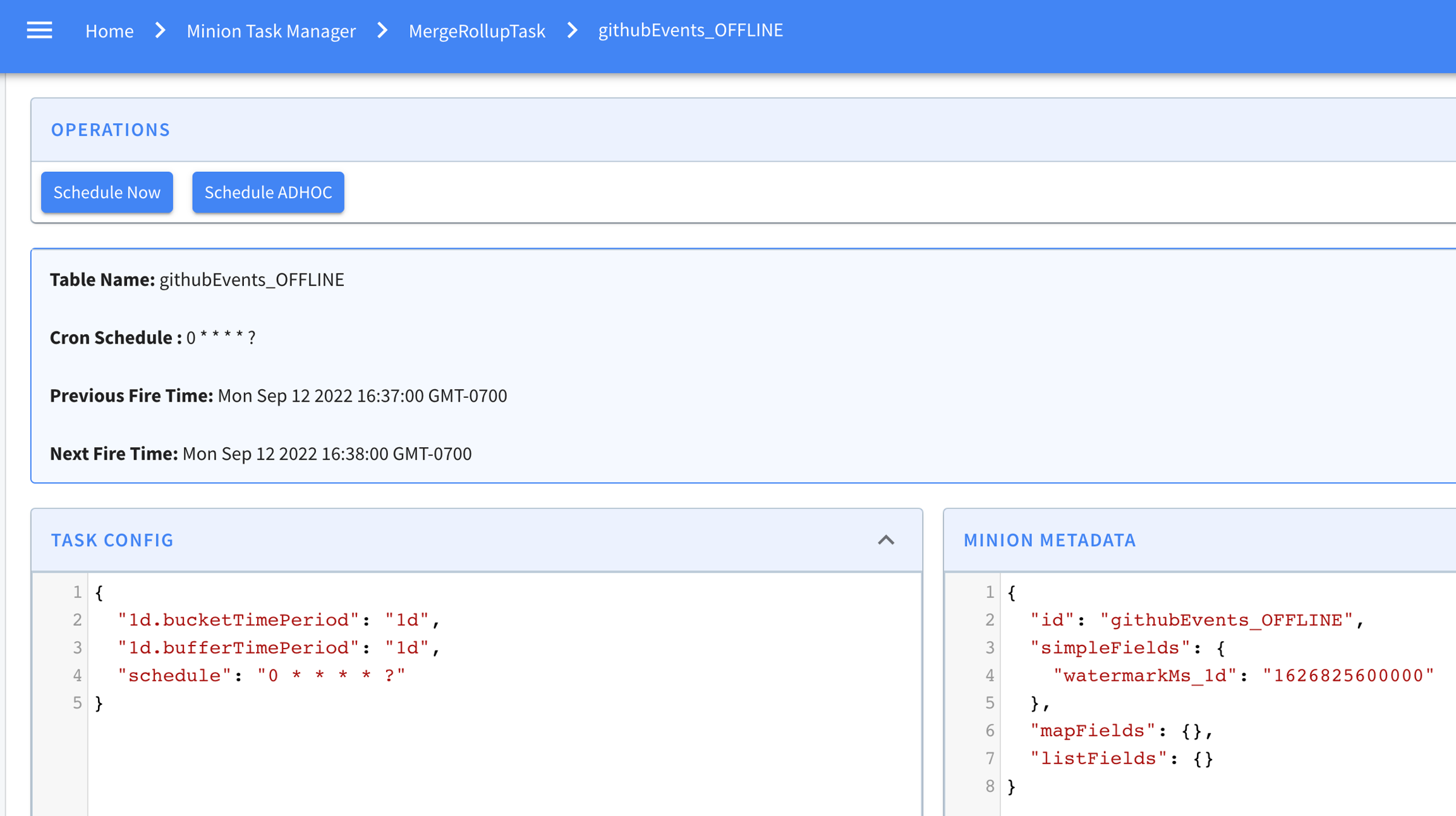
Explore the minion component in Apache Pinot, empowering efficient data movement and segment generation within Pinot clusters.
docker run \
--network=pinot-demo \
--name pinot-minion \
-d ${PINOT_IMAGE} StartMinion \
-zkAddress pinot-zookeeper:2181bin/pinot-admin.sh StartMinion \
-zkAddress localhost:2181Usage: StartMinion
-help : Print this message. (required=false)
-minionHost <String> : Host name for minion. (required=false)
-minionPort <int> : Port number to start the minion at. (required=false)
-zkAddress <http> : HTTP address of Zookeeper. (required=false)
-clusterName <String> : Pinot cluster name. (required=false)
-configFileName <Config File Name> : Minion Starter Config file. (required=false)public interface PinotTaskGenerator {
/**
* Initializes the task generator.
*/
void init(ClusterInfoAccessor clusterInfoAccessor);
/**
* Returns the task type of the generator.
*/
String getTaskType();
/**
* Generates a list of tasks to schedule based on the given table configs.
*/
List<PinotTaskConfig> generateTasks(List<TableConfig> tableConfigs);
/**
* Returns the timeout in milliseconds for each task, 3600000 (1 hour) by default.
*/
default long getTaskTimeoutMs() {
return JobConfig.DEFAULT_TIMEOUT_PER_TASK;
}
/**
* Returns the maximum number of concurrent tasks allowed per instance, 1 by default.
*/
default int getNumConcurrentTasksPerInstance() {
return JobConfig.DEFAULT_NUM_CONCURRENT_TASKS_PER_INSTANCE;
}
/**
* Performs necessary cleanups (e.g. remove metrics) when the controller leadership changes.
*/
default void nonLeaderCleanUp() {
}
}public interface PinotTaskExecutorFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the executor.
*/
String getTaskType();
/**
* Creates a new task executor.
*/
PinotTaskExecutor create();
}public interface PinotTaskExecutor {
/**
* Executes the task based on the given task config and returns the execution result.
*/
Object executeTask(PinotTaskConfig pinotTaskConfig)
throws Exception;
/**
* Tries to cancel the task.
*/
void cancel();
}public interface MinionEventObserverFactory {
/**
* Initializes the task executor factory.
*/
void init(MinionTaskZkMetadataManager zkMetadataManager);
/**
* Returns the task type of the event observer.
*/
String getTaskType();
/**
* Creates a new task event observer.
*/
MinionEventObserver create();
}public interface MinionEventObserver {
/**
* Invoked when a minion task starts.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskStart(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task succeeds.
*
* @param pinotTaskConfig Pinot task config
* @param executionResult Execution result
*/
void notifyTaskSuccess(PinotTaskConfig pinotTaskConfig, @Nullable Object executionResult);
/**
* Invoked when a minion task gets cancelled.
*
* @param pinotTaskConfig Pinot task config
*/
void notifyTaskCancelled(PinotTaskConfig pinotTaskConfig);
/**
* Invoked when a minion task encounters exception.
*
* @param pinotTaskConfig Pinot task config
* @param exception Exception encountered during execution
*/
void notifyTaskError(PinotTaskConfig pinotTaskConfig, Exception exception);
} "ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY",
"batchConfigMaps": [
{
"input.fs.className": "org.apache.pinot.plugin.filesystem.S3PinotFS",
"input.fs.prop.region": "us-west-2",
"input.fs.prop.secretKey": "....",
"input.fs.prop.accessKey": "....",
"inputDirURI": "s3://my.s3.bucket/batch/airlineStats/rawdata/",
"includeFileNamePattern": "glob:**/*.avro",
"excludeFileNamePattern": "glob:**/*.tmp",
"inputFormat": "avro"
}
]
}
},
"task": {
"taskTypeConfigsMap": {
"SegmentGenerationAndPushTask": {
"schedule": "0 */10 * * * ?",
"tableMaxNumTasks": "10"
}
}
}{
...
"task": {
"taskTypeConfigsMap": {
"myTask": {
"myProperty1": "value1",
"myProperty2": "value2"
}
}
}
}Using "POST /cluster/configs" API on CLUSTER tab in Swagger, with this payload
{
"RealtimeToOfflineSegmentsTask.timeoutMs": "600000",
"RealtimeToOfflineSegmentsTask.numConcurrentTasksPerInstance": "4"
} "task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bucketTimePeriod": "1h",
"bufferTimePeriod": "1h",
"schedule": "0 * * * * ?"
}
}
}, "task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bucketTimePeriod": "1h",
"bufferTimePeriod": "1h",
"schedule": "0 * * * * ?",
"minionInstanceTag": "tag1_MINION"
}
}
},