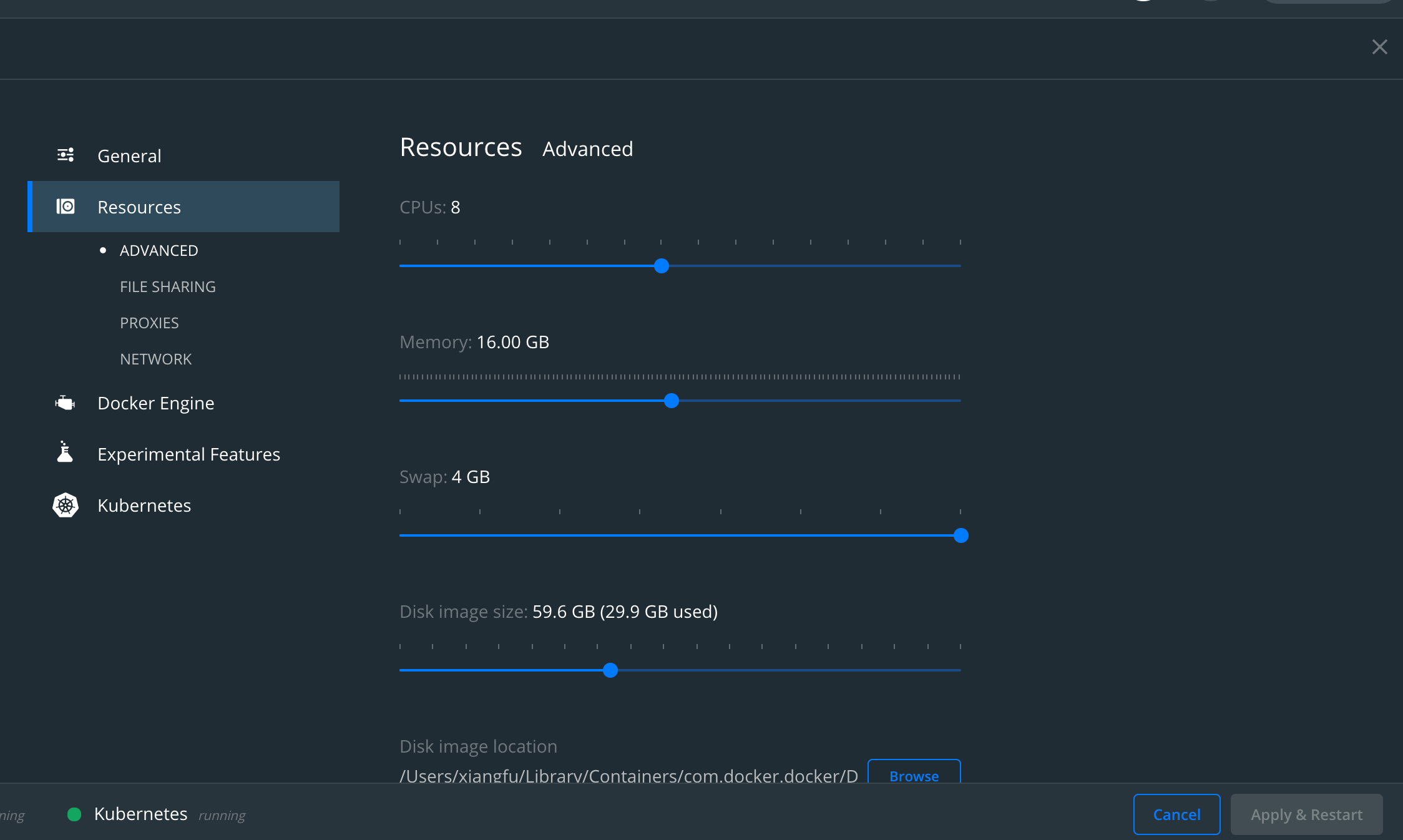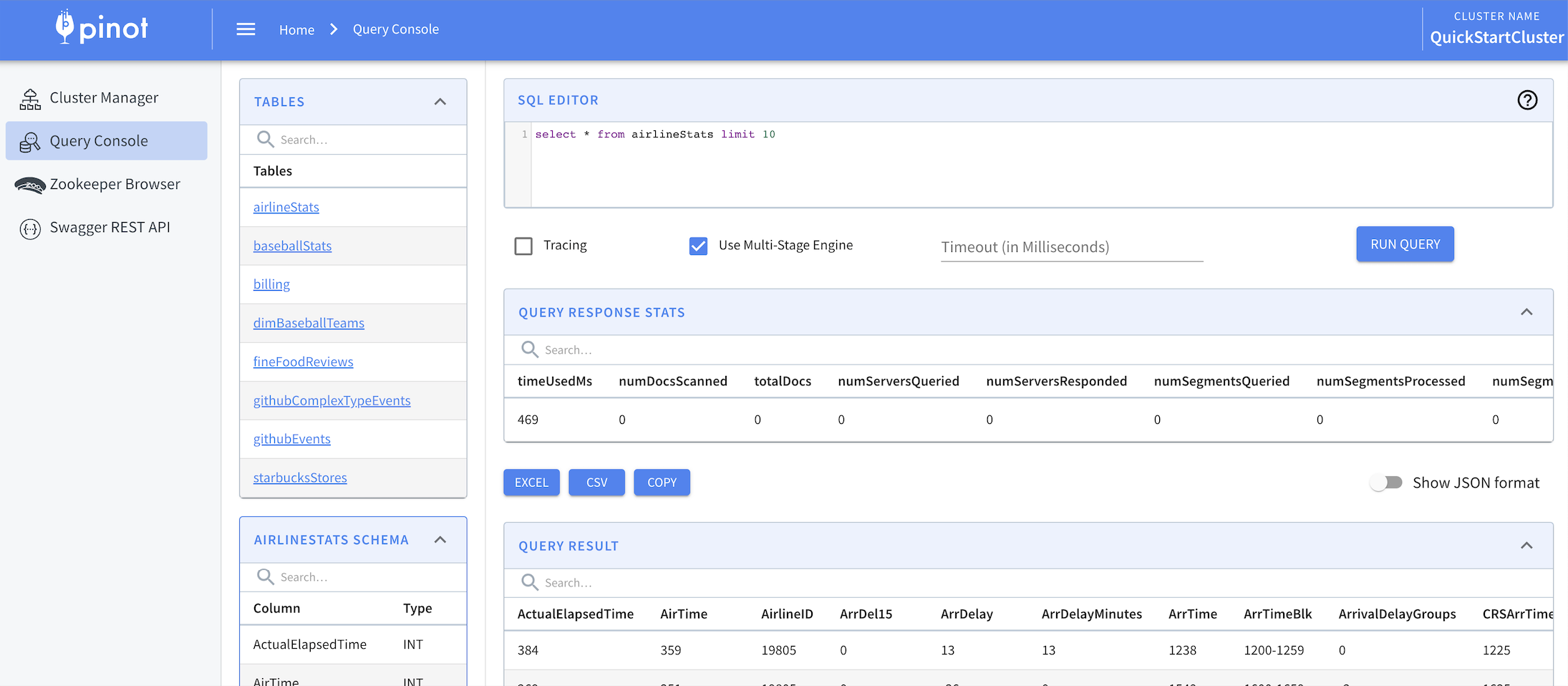
Troubleshoot issues with the multi-stage query engine (v2).
dateTimeConvertWindowHop function is not supported in v2.-- example 1: used in GROUP-BY
SELECT count(*), RandomAirports FROM airlineStats
GROUP BY RandomAirports
-- example 2: used in PREDICATE
SELECT * FROM airlineStats WHERE RandomAirports IN ('SFO', 'JFK')
-- example 3: used in ORDER-BY
SELECT count(*), RandomAirports FROM airlineStats
GROUP BY RandomAirports
ORDER BY RandomAirports DESC-- example 1: used in GROUP-BY
SELECT count(*), arrayToMv(RandomAirports) FROM airlineStats
GROUP BY arrayToMv(RandomAirports)
-- example 2: used in PREDICATE
SELECT * FROM airlineStats WHERE arrayToMv(RandomAirports) IN ('SFO', 'JFK')
-- example 3: used in ORDER-BY
SELECT count(*), arrayToMV(RandomAirports) FROM airlineStats
GROUP BY arrayToMV(RandomAirports)
ORDER BY arrayToMV(RandomAirports) DESCSELECT* from default.myTable;
SELECT * from schemaName.myTable;SELECT * from myTable;select distinctcounthll(col) from myTableselect distinctcounthll(col, 8) from myTableSELECT colA, colA, COUNT(*)
FROM myTable GROUP BY colA ORDER BY colASELECT colA AS tmpA, colA as tmpB, COUNT(*)
FROM myTable GROUP BY tmpA, tmpB ORDER BY tmpASELECT colA, colA, COUNT(*)
FROM myTable GROUP BY 1, 2 ORDER BY 1is_distinct_from(...)
isDistinctFrom(...)timestampCol >= longColCAST(timestampCol AS BITINT) >= longCol SELECT count(*) from mytable "columnNames": [
"EXPR$0"
], SELECT count(*) from mytable "columnNames": [
"count(*)"
],select add(1,2,3,4,5) from tableselect add(1, add(2,add(3, add(4,5)))) from tableTo query using distributed joins, window functions, and other multi-stage operators in real time, turn on the multi-stage query engine (v2).
aggregateMetrics setting?{
"tableConfig": {
"tableName": "...",
"ingestionConfig": {
"aggregationConfigs": [{
"columnName": "aggregatedFieldName",
"aggregationFunction": "<aggregationFunction>(<originalFieldName>)"
}]
}
}
}{"customerID":205,"product_name": "car","price":"1500.00","timestamp":1571900400000}
{"customerID":206,"product_name": "truck","price":"2200.00","timestamp":1571900400000}
{"customerID":207,"product_name": "car","price":"1300.00","timestamp":1571900400000}
{"customerID":208,"product_name": "truck","price":"700.00","timestamp":1572418800000}
{"customerID":209,"product_name": "car","price":"1100.00","timestamp":1572505200000}
{"customerID":210,"product_name": "car","price":"2100.00","timestamp":1572505200000}
{"customerID":211,"product_name": "truck","price":"800.00","timestamp":1572678000000}
{"customerID":212,"product_name": "car","price":"800.00","timestamp":1572678000000}
{"customerID":213,"product_name": "car","price":"1900.00","timestamp":1572678000000}
{"customerID":214,"product_name": "car","price":"1000.00","timestamp":1572678000000}{
"schemaName": "daily_sales_schema",
"dimensionFieldSpecs": [
{
"name": "product_name",
"dataType": "STRING"
}
],
"metricSpecs": [
{
"name": "sales_count",
"dataType": "LONG"
},
{
"name": "total_sales",
"dataType": "DOUBLE"
}
],
"dateTimeFieldSpecs": [
{
"name": "daysSinceEpoch",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}{
"tableName": "daily_sales",
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "daysSinceEpoch",
"transformFunction": "toEpochDays(timestamp)"
}
],
"aggregationConfigs": [
{
"columnName": "total_sales",
"aggregationFunction": "SUM(price)"
},
{
"columnName": "sales_count",
"aggregationFunction": "COUNT(*)"
}
]
}
"tableIndexConfig": {
"noDictionaryColumns": [
"sales_count",
"total_sales"
]
}
}curl -X POST http://localhost:9000/sql -d
'
{
"sql": "select * from baseballStats limit 10",
"trace": false,
"queryOptions": "useMultistageEngine=true"
}
'curl -X POST http://localhost:8000/query/sql -d '
{
"sql": "select * from baseballStats limit 10",
"trace": false,
"queryOptions": "useMultistageEngine=true"
}
'SET useMultistageEngine=true; -- indicator to enable the multi-stage engine.
SELECT * from baseballStats limit 10select count(*) from my_table where column IS NOT NULL select count(*) from my_table where column <> 'default_null_value' select avg(Age) from my_table select avg(Age) from my_table WHERE Age <> -1




Groovy({groovy script}, argument1, argument2...argumentN)"tableConfig": {
"tableName": ...,
"tableType": ...,
"ingestionConfig": {
"filterConfig": {
"filterFunction": "<expression>"
}
}
}"ingestionConfig": {
"filterConfig": {
"filterFunction": "Groovy({timestamp < 1589007600000}, timestamp)"
}
}"ingestionConfig": {
"filterConfig": {
"filterFunction": "Groovy({(campaign == \"X\" || campaign == \"Y\") && prices.sum() < 100}, prices, campaign)"
}
}"ingestionConfig": {
"filterConfig": {
"filterFunction": "strcmp(campaign, 'X') = 0 OR strcmp(campaign, 'Y') = 0 OR timestamp < 1589007600000"
}
}{ "tableConfig": {
"tableName": ...,
"tableType": ...,
"ingestionConfig": {
"transformConfigs": [{
"columnName": "fieldName",
"transformFunction": "<expression>"
}]
},
...
}{
"tableName": "myTable",
...
"ingestionConfig": {
"transformConfigs": [{
"columnName": "maxPrice",
"transformFunction": "Groovy({prices.max()}, prices)" // groovy function
},
{
"columnName": "hoursSinceEpoch",
"transformFunction": "toEpochHours(timestamp)" // built-in function
}]
}
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "fullName",
"transformFunction": "Groovy({firstName+' '+lastName}, firstName, lastName)"
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "maxBid",
"transformFunction": "Groovy({bids.max{ it.toBigDecimal() }}, bids)"
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "hoursSinceEpoch",
"transformFunction": "Groovy({timestamp/(1000*60*60)}, timestamp)"
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "userId",
"transformFunction": "Groovy({user_id}, user_id)"
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "firstName",
"transformFunction": "\"first Name \""
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "impressions",
"transformFunction": "Groovy({eventType == 'IMPRESSION' ? 1: 0}, eventType)"
},
{
"columnName": "clicks",
"transformFunction": "Groovy({eventType == 'CLICK' ? 1: 0}, eventType)"
}]
}"ingestionConfig": {
"transformConfigs": [{
"columnName": "map2_keys",
"transformFunction": "Groovy({map2.sort()*.key}, map2)"
},
{
"columnName": "map2_values",
"transformFunction": "Groovy({map2.sort()*.value}, map2)"
}]
}{
"userId": "12345678__foo__othertext"
}"ingestionConfig": {
"transformConfigs": [
{
"columnName": "userOid",
"transformFunction": "jsonPathString(data, '$.userId')"
},
{
"columnName": "userId",
"transformFunction": "Groovy({Long.valueOf(userOid.substring(0, 8))}, userOid)"
}
]
}








sortedColumn with streaming tablesexport PINOT_VERSION=0.10.0
export PINOT_IMAGE=apachepinot/pinot:${PINOT_VERSION}
docker pull ${PINOT_IMAGE}docker network create -d bridge pinot-demodocker run \
--network=pinot-demo \
--name pinot-zookeeper \
--restart always \
-p 2181:2181 \
-d zookeeper:3.5.6docker run \
--network pinot-demo --name=zkui \
-p 9090:9090 \
-e ZK_SERVER=pinot-zookeeper:2181 \
-d qnib/plain-zkui:latestdocker run \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181docker run \
--network=pinot-demo \
--name pinot-broker \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181export PINOT_IMAGE=apachepinot/pinot:0.3.0-SNAPSHOT
docker run \
--network=pinot-demo \
--name pinot-server \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181docker container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9e80c3fcd29b apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 18 seconds ago Up 17 seconds 8096-8099/tcp, 9000/tcp pinot-server
f4c42a5865c7 apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 21 seconds ago Up 21 seconds 8096-8099/tcp, 9000/tcp pinot-broker
a413b0013806 apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 26 seconds ago Up 25 seconds 8096-8099/tcp, 0.0.0.0:9000->9000/tcp pinot-controller
9d3b9c4d454b zookeeper:3.5.6 "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp pinot-zookeeper$ export PINOT_VERSION=0.10.0
$ tar -xvf apache-pinot-${PINOT_VERSION}-bin.tar.gz
$ cd apache-pinot-${PINOT_VERSION}-bin
$ ls
DISCLAIMER LICENSE NOTICE bin conf lib licenses query_console sample_data
$ PINOT_INSTALL_DIR=`pwd`cd apache-pinot-${PINOT_VERSION}-bin
bin/pinot-admin.sh StartZookeeperbin/pinot-admin.sh StartController \
-zkAddress localhost:2181bin/pinot-admin.sh StartBroker \
-zkAddress localhost:2181controller.helix.cluster.name=pinot-quickstart
controller.port=9000
controller.vip.host=pinot-controller
controller.vip.port=9000
controller.data.dir=/var/pinot/controller/data
controller.zk.str=pinot-zookeeper:2181
pinot.set.instance.id.to.hostname=truebin/pinot-admin.sh StartController -configFileName config/pinot-controller.confpinot.broker.client.queryPort=8099
pinot.broker.routing.table.builder.class=random
pinot.set.instance.id.to.hostname=truebin/pinot-admin.sh StartBroker -clusterName pinot-quickstart -zkAddress pinot-zookeeper:2181 -configFileName config/pinot-broker.confpinot.server.netty.port=8098
pinot.server.adminapi.port=8097
pinot.server.instance.dataDir=/var/pinot/server/data/index
pinot.server.instance.segmentTarDir=/var/pinot/server/data/segment
pinot.set.instance.id.to.hostname=truebin/pinot-admin.sh StartServer -clusterName pinot-quickstart -zkAddress pinot-zookeeper:2181 -configFileName config/pinot-server.confdocker run \
--network=pinot-demo \
--name pinot-batch-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -schemaFile examples/batch/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: a413b0013806, version: Unknown
{"status":"Table airlineStats_OFFLINE succesfully added"}bin/pinot-admin.sh AddTable \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-exec...
"tableIndexConfig": {
...
"createInvertedIndexDuringSegmentGeneration": true,
...
}
...docker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d wurstmeister/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper pinot-zookeeper:2181/kafka \
--partitions=1 --replication-factor=1 \
--create --topic flights-realtimedocker run \
--network=pinot-demo \
--name pinot-streaming-table-creation \
${PINOT_IMAGE} AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-execExecuting command: AddTable -tableConfigFile examples/docker/table-configs/airlineStats_realtime_table_config.json -schemaFile examples/stream/airlineStats/airlineStats_schema.json -controllerHost pinot-controller -controllerPort 9000 -exec
Sending request: http://pinot-controller:9000/schemas to controller: 8fbe601012f3, version: Unknown
{"status":"Table airlineStats_REALTIME succesfully added"}bin/pinot-admin.sh StartZookeeper -zkPort 2191bin/pinot-admin.sh StartKafka -zkAddress=localhost:2191/kafka -port 19092docker run \
--network=pinot-demo \
--name pinot-data-ingestion-job \
${PINOT_IMAGE} LaunchDataIngestionJob \
-jobSpecFile examples/docker/ingestion-job-specs/airlineStats.yamlSegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**/*.avro
inputDirURI: examples/batch/airlineStats/rawdata
jobType: SegmentCreationAndTarPush
outputDirURI: examples/batch/airlineStats/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://pinot-controller:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
pushJobSpec: {pushAttempts: 2, pushParallelism: 1, pushRetryIntervalMillis: 1000,
segmentUriPrefix: null, segmentUriSuffix: null}
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.avro.AvroRecordReader,
configClassName: null, configs: null, dataFormat: avro}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://pinot-controller:9000/tables/airlineStats/schema',
tableConfigURI: 'http://pinot-controller:9000/tables/airlineStats', tableName: airlineStats}
Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner
Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
Finished building StatsCollector!
Collected stats for 403 documents
Created dictionary for INT column: FlightNum with cardinality: 386, range: 14 to 7389
Using fixed bytes value dictionary for column: Origin, size: 294
Created dictionary for STRING column: Origin with cardinality: 98, max length in bytes: 3, range: ABQ to VPS
Created dictionary for INT column: Quarter with cardinality: 1, range: 1 to 1
Created dictionary for INT column: LateAircraftDelay with cardinality: 50, range: -2147483648 to 303
......
......
Pushing segment: airlineStats_OFFLINE_16085_16085_29 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16085_16085_29 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16085_16085_29 of table: airlineStats"}
Pushing segment: airlineStats_OFFLINE_16084_16084_30 to location: http://pinot-controller:9000 for table airlineStats
Sending request: http://pinot-controller:9000/v2/segments?tableName=airlineStats to controller: a413b0013806, version: Unknown
Response for pushing table airlineStats segment airlineStats_OFFLINE_16084_16084_30 to location http://pinot-controller:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16084_16084_30 of table: airlineStats"}bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile examples/batch/airlineStats/ingestionJobSpec.yamldocker run \
--network pinot-demo \
--name=loading-airlineStats-data-to-kafka \
${PINOT_IMAGE} StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList kafka:9092 -zkAddress pinot-zookeeper:2181/kafkabin/pinot-admin.sh StreamAvroIntoKafka \
-avroFile examples/stream/airlineStats/sample_data/airlineStats_data.avro \
-kafkaTopic flights-realtime -kafkaBrokerList localhost:19092 -zkAddress localhost:2191/kafkabin/pinot-admin.sh StartServer \
-zkAddress localhost:2181bin/pinot-admin.sh AddTable \
-schemaFile examples/stream/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/stream/airlineStats/airlineStats_realtime_table_config.json \
-exec