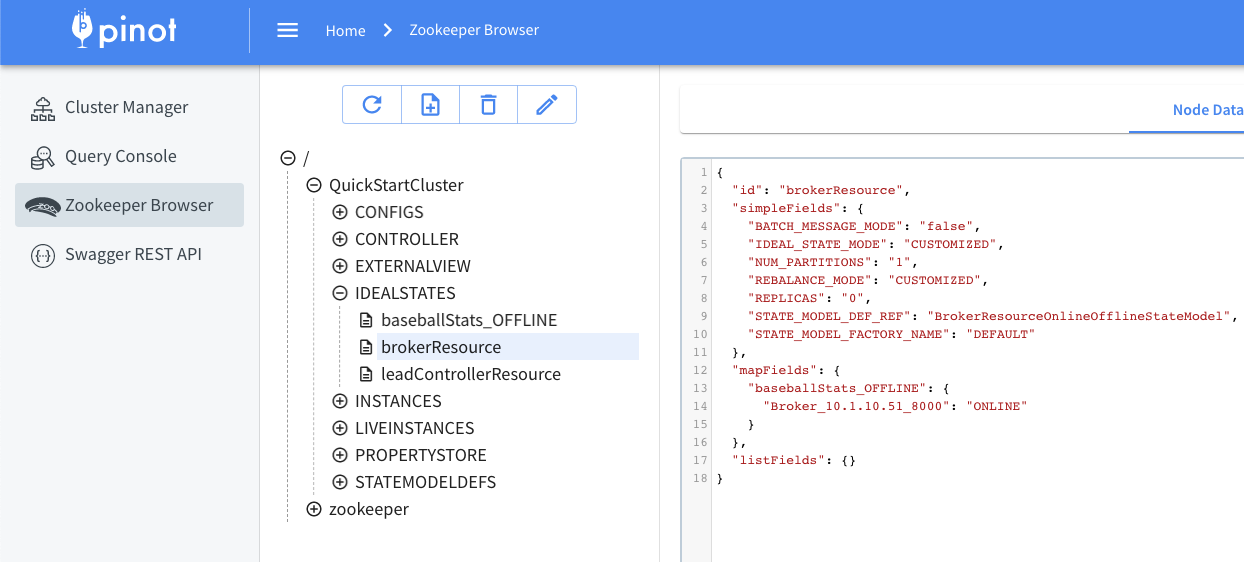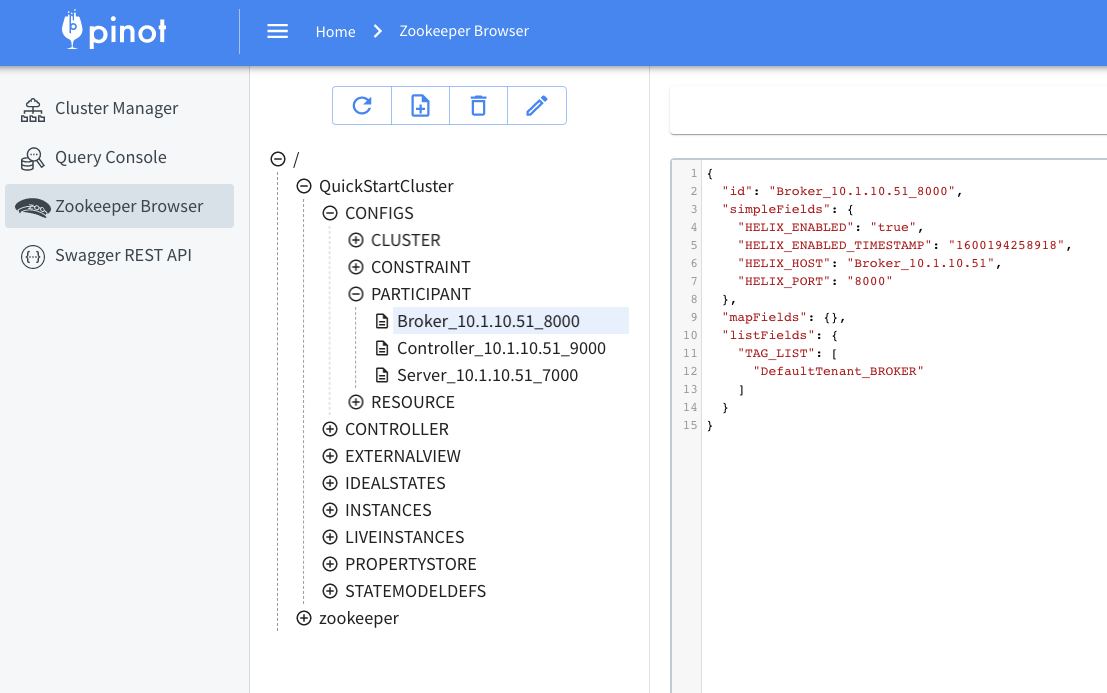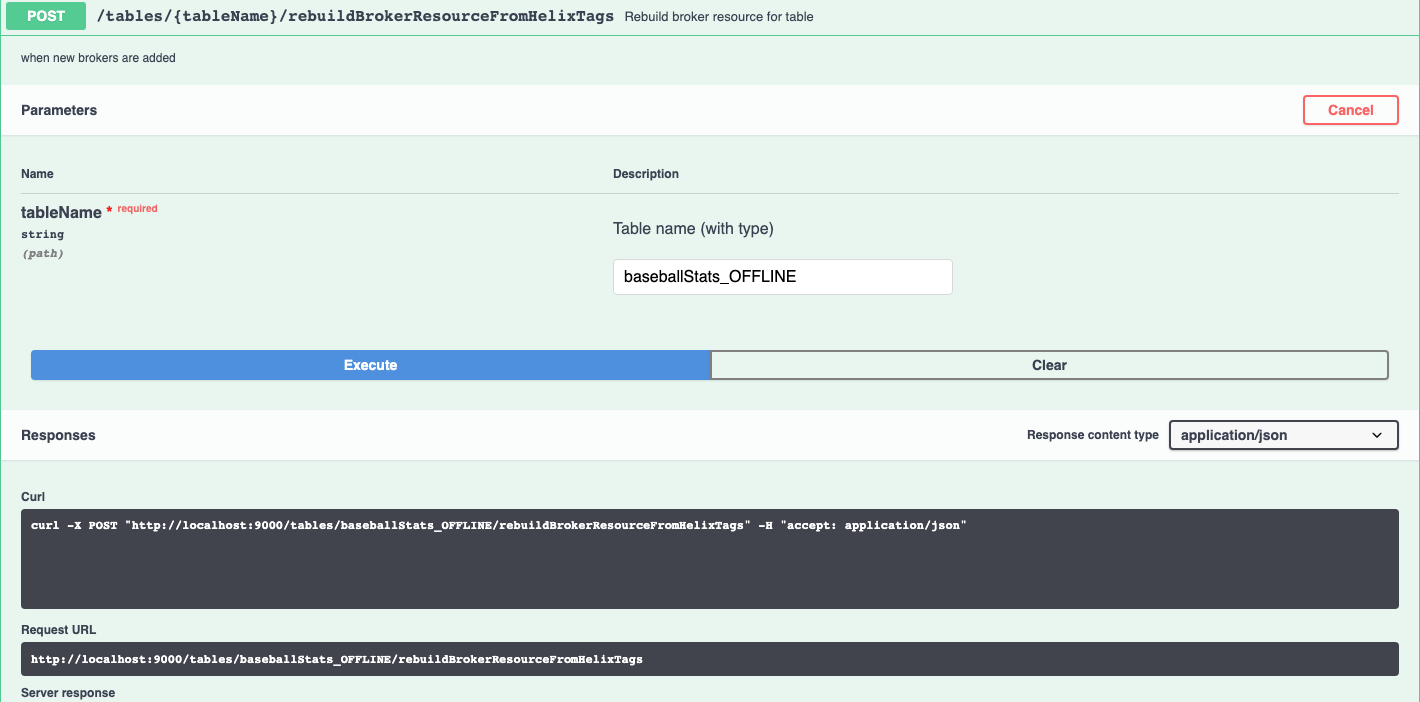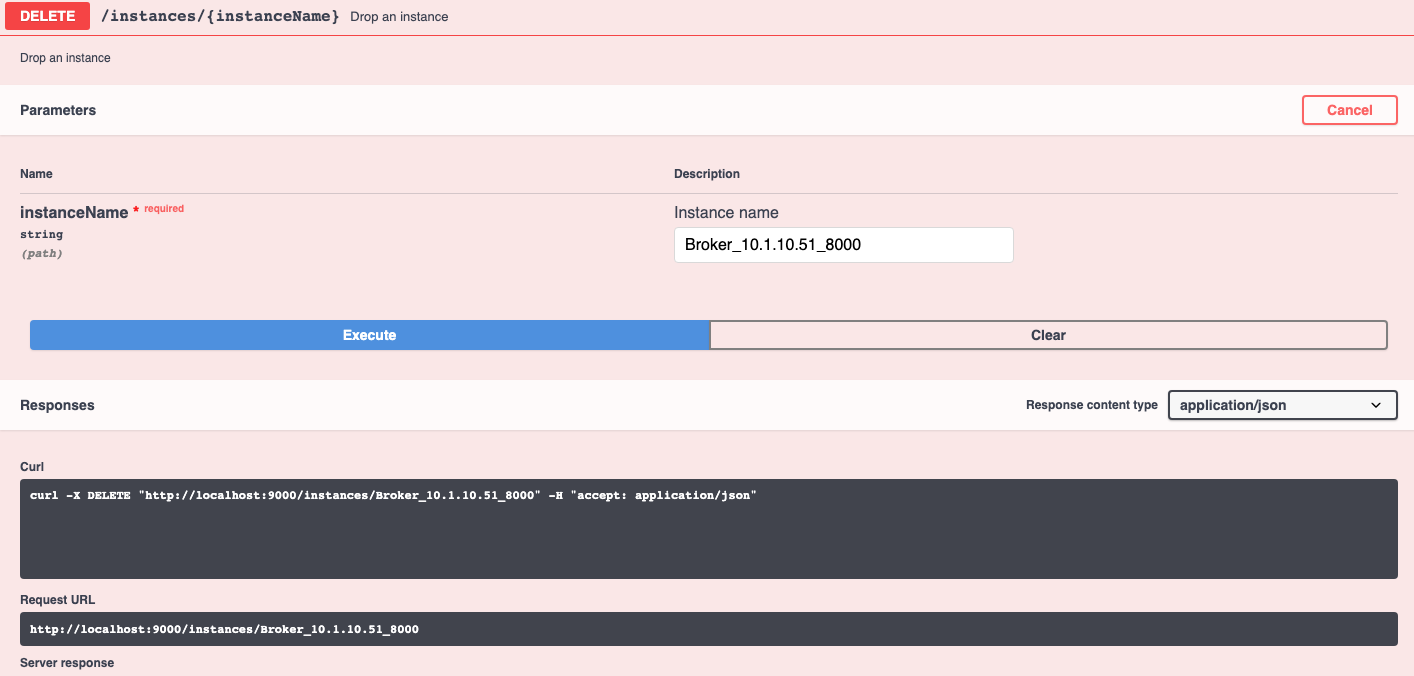
This page describes how to rebalance a table
{
"tableName": "myTable_OFFLINE",
"tenants" : {
"broker":"DefaultTenant",
"server":"DefaultTenant"
}
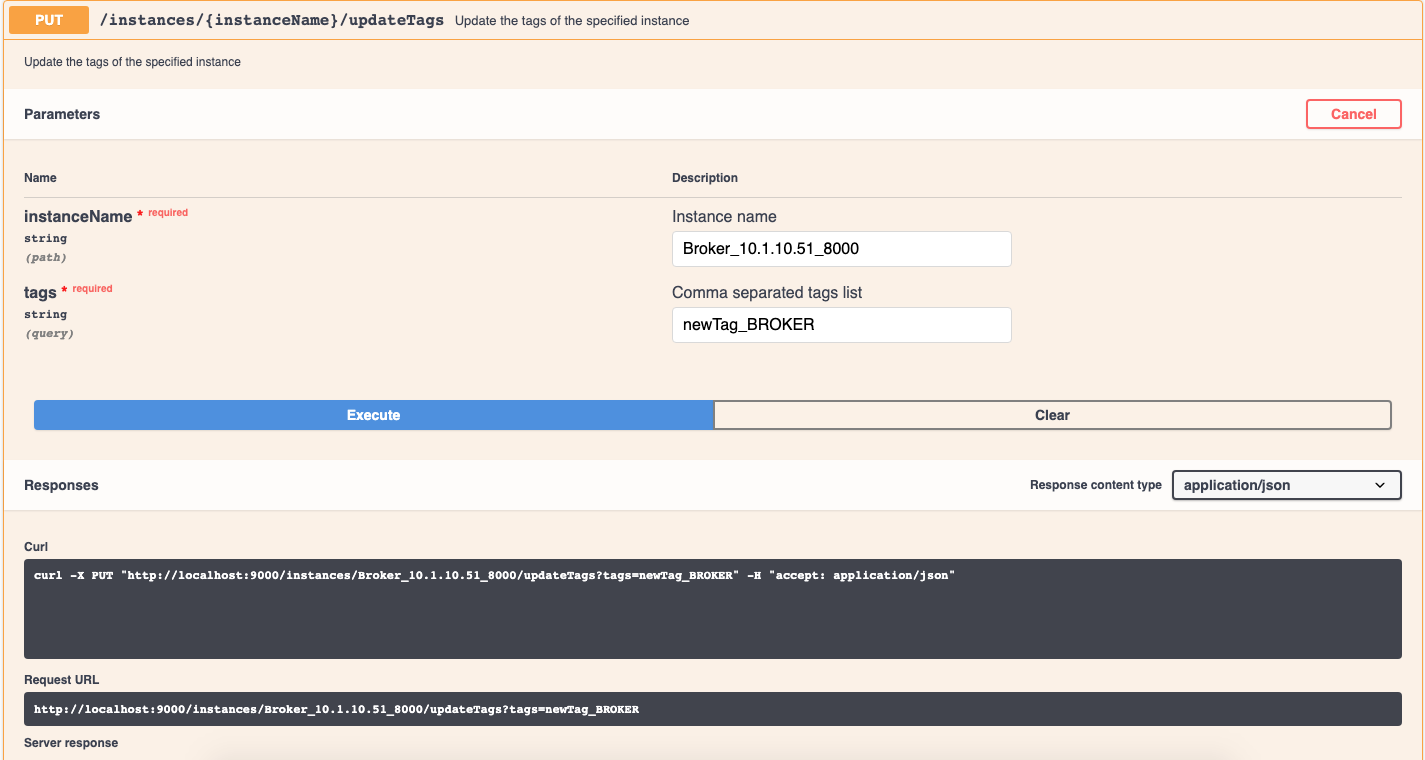
}curl -X PUT "http://localhost:9000/instances/Server_10.1.10.51_7000"
-H "accept: application/json"
-H "Content-Type: application/json"
-d "{ \"host\": \"10.1.10.51\", \"port\": \"7000\", \"type\": \"SERVER\", \"tags\": [ \"newName_OFFLINE\", \"DefaultTenant_REALTIME\" ]}"pinot.set.instance.id.to.hostname=true"REALTIME": {
...
"tenants": {
...
"server": "<tenant_name>",
...
},
...
"instanceAssignmentConfigMap": {
...
"CONSUMING": {
...
"tagPoolConfig": {
...
"tag": "<tenant_name>_REALTIME",
...
},
...
},
...
"COMPLETED": {
...
"tagPoolConfig": {
...
"tag": "<tenant_name>_REALTIME",
...
},
...
},
...
},
...
}"OFFLINE": {
...
"tenants": {
...
"server": "<tenant_name>",
...
},
...
"instanceAssignmentConfigMap": {
...
"OFFLINE": {
...
"tagPoolConfig": {
...
"tag": "<tenant_name>_OFFLINE",
...
},
...
},
...
},
...
}"instanceAssignmentConfigMap": {
...
"OFFLINE": {
...
"replicaGroupPartitionConfig": {
...
"minimizeDataMovement": true,
...
},
...
},
...
}"segmentsConfig": {
...
"minimizeDataMovement": true,
...
}curl -X GET "https://localhost:9000/rebalanceStatus/ffb38717-81cf-40a3-8f29-9f35892b01f9" -H "accept: application/json"{"tableRebalanceProgressStats": {
"startTimeMs": 1679073157779,
"status": "DONE", // IN_PROGRESS/DONE/FAILED
"timeToFinishInSeconds": 0, // Time it took for the rebalance job after it completes/fails
"completionStatusMsg": "Finished rebalancing table: airlineStats_OFFLINE with minAvailableReplicas: 1, enableStrictReplicaGroup: false, bestEfforts: false in 44 ms."
// The total amount of work required for rebalance
"initialToTargetStateConvergence": {
"_segmentsMissing": 0, // Number of segments missing in the current state but present in the target state
"_segmentsToRebalance": 31, // Number of segments that needs to be assigned to hosts so that the current state can get to the target state.
"_percentSegmentsToRebalance": 100, // Total number of replicas that needs to be assigned to hosts so that the current state can get to the target state.
"_replicasToRebalance": 279 // Remaining work to be done in %
},
// The pending work for rebalance
"externalViewToIdealStateConvergence": {
"_segmentsMissing": 0,
"_segmentsToRebalance": 0,
"_percentSegmentsToRebalance": 0,
"_replicasToRebalance": 0
},
// Additional work to catch up with the new ideal state, when the ideal
// state shifts since rebalance started.
"currentToTargetConvergence": {
"_segmentsMissing": 0,
"_segmentsToRebalance": 0,
"_percentSegmentsToRebalance": 0,
"_replicasToRebalance": 0
},
},
"timeElapsedSinceStartInSeconds": 28 // If rebalance is IN_PROGRESS, this gives the time elapsed since it started
}curl -X GET "https://localhost:9000/table/airlineStats_OFFLINE/jobstype=OFFLINE&jobTypes=TABLE_REBALANCE" -H "accept: application/json" "ffb38717-81cf-40a3-8f29-9f35892b01f9": {
"jobId": "ffb38717-81cf-40a3-8f29-9f35892b01f9",
"submissionTimeMs": "1679073157804",
"jobType": "TABLE_REBALANCE",
"REBALANCE_PROGRESS_STATS": "{\"initialToTargetStateConvergence\":{\"_segmentsMissing\":0,\"_segmentsToRebalance\":31,\"_percentSegmentsToRebalance\":100.0,\"_replicasToRebalance\":279},\"externalViewToIdealStateConvergence\":{\"_segmentsMissing\":0,\"_segmentsToRebalance\":0,\"_percentSegmentsToRebalance\":0.0,\"_replicasToRebalance\":0},\"currentToTargetConvergence\":{\"_segmentsMissing\":0,\"_segmentsToRebalance\":0,\"_percentSegmentsToRebalance\":0.0,\"_replicasToRebalance\":0},\"startTimeMs\":1679073157779,\"status\":\"DONE\",\"timeToFinishInSeconds\":0,\"completionStatusMsg\":\"Finished rebalancing table: airlineStats_OFFLINE with minAvailableReplicas: 1, enableStrictReplicaGroup: false, bestEfforts: false in 44 ms.\"}",
"tableName": "airlineStats_OFFLINE"
{
"tableName": "myTable_OFFLINE",
"tenants" : {
"broker":"DefaultTenant",
"server":"DefaultTenant"
}
}Failed to drop instance Broker_10.1.10.51_8000 -
Instance Broker_10.1.10.51_8000 is still liveFailed to drop instance Broker_172.17.0.2_8099 -
Instance Broker_172.17.0.2_8099 exists in ideal state for brokerResource{
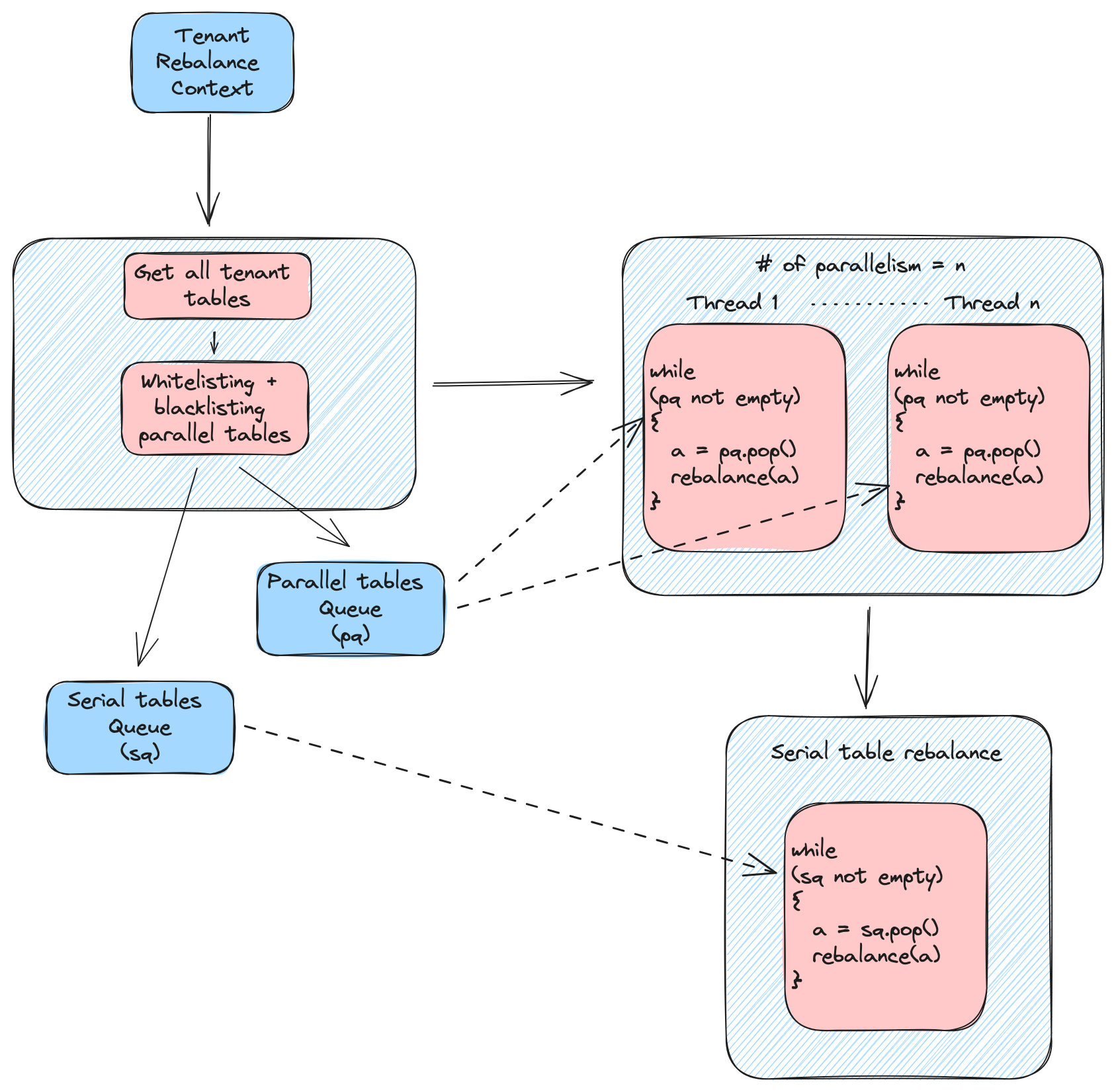
"tenantName": "DefaultTenant",
"degreeOfParallelism": 2,
"parallelWhitelist": [
"airlineStats1_OFFLINE",
"airlineStats2_OFFLINE"
],
"parallelBlacklist": [
"airlineStats1_REALTIME"
],
"verboseResult": false,
"dryRun": false,
"downtime": false,
"reassignInstances": false,
"includeConsuming": false,
"bootstrap": false,
"minAvailableReplicas": 1,
"bestEfforts": false,
"updateTargetTier": false,
"externalViewCheckIntervalInMs": 1000,
"externalViewStabilizationTimeoutInMs": 3600000
}{
"jobId": "dfbbebb7-1f62-497d-82a7-ded6e0d855e1",
"rebalanceTableResults": {
"airlineStats1_OFFLINE": {
"jobId": "2d4dc2da-1071-42b5-a20c-ac38a6d53fc4",
"status": "IN_PROGRESS",
"description": "In progress, check controller task status for the progress"
},
"airlineStats2_OFFLINE": {
"jobId": "2d4dc2da-497d-82a7-a20c-a113dfbbebb7",
"status": "IN_PROGRESS",
"description": "In progress, check controller task status for the progress"
},
"airlineStats1_REALTIME": {
"jobId": "9284f137-29c1-4c5a-a113-17b90a484403",
"status": "NO_OP",
"description": "Table is already balanced"
}
}
}{
"tenantRebalanceProgressStats": {
"startTimeMs": 1689679866904,
"timeToFinishInSeconds": 2345,
"completionStatusMsg": "Successfully rebalanced tenant DefaultTenant.",
"tableStatusMap": {
"airlineStats1_OFFLINE": "Table is already balanced",
"airlineStats2_OFFLINE": "Table rebalance in progress",
"airlineStats1_REALTIME": "Table is already balanced"
},
"totalTables": 3,
"remainingTables": 1,
"tableRebalanceJobIdMap": {
"airlineStats1_OFFLINE": "2d4dc2da-1071-42b5-a20c-ac38a6d53fc4",
"airlineStats2_OFFLINE": "2d4dc2da-497d-82a7-a20c-a113dfbbebb7",
"airlineStats1_REALTIME": "9284f137-29c1-4c5a-a113-17b90a484403"
}
},
"timeElapsedSinceStartInSeconds": 12345
}