Storing records with dynamic schemas in a table with a fixed schema.
Some domains (e.g., logging) generate records where each record can have a different set of keys, whereas Pinot tables have a relatively static schema. For records with varying keys, it's impractical to store each field in its own table column. However, most (if not all) fields may be important, so fields should not be dropped unnecessarily.
The SchemaConformingTransformer is a RecordTransformer that can transform records with dynamic schemas such that they can be ingested in a table with a static schema. The transformer primarily takes record fields that don't exist in the schema and stores them in a type of catchall field.
For example, consider this record:
Let's say the table's schema contains the following fields:
timestamp
hostname
level
message
tags.platform
tags.service
indexableExtras
unindexableExtras
Without this transformer, the HOSTNAME field and the entire tags field would be dropped when storing the record in the table. However, with this transformer, the record would be transformed into the following:
Notice that the transformer does the following:
Flattens nested fields which exist in the schema, like tags.platform
Drops some fields like HOSTNAME, where HOSTNAME must be listed as a field in the config option fieldPathsToDrop
The unindexableExtras field allows the transformer to separate fields that don't need indexing (because they are only retrieved, not searched) from those that do.
SchemaConformingTransformer Configuration
To use the transformer, add the schemaConformingTransformerConfig option in the ingestionConfig section of your table configuration, as shown in the following example.
This section contains a collection of guides that will show you how to import data from a Pinot-supported input format.
Pinot offers support for various popular input formats during ingestion. By changing the input format, you can reduce the time spent doing serialization-deserialization and speed up the ingestion.
Configuring input formats
To change the input format, adjust the recordReaderSpec config in the ingestion job specification.
The configuration consists of the following keys:
dataFormat: Name of the data format to consume.
className: Name of the class that implements the RecordReader interface. This class is used for parsing the data.
Supported input formats
Pinot supports multiple input formats out of the box. Specify the corresponding readers and the associated custom configurations to switch between formats.
CSV
CSV Record Reader supports the following configs:
fileFormat: default, rfc4180, excel, tdf, mysql
Your CSV file may have raw text fields that cannot be reliably delimited using any character. In this case, explicitly set the multiValueDelimeter field to empty in the ingestion config.
multiValueDelimiter: ''
Avro
The Avro record reader converts the data in file to a GenericRecord. A Java class or .avro file is not required. By default, the Avro record reader only supports primitive types. To enable support for rest of the Avro data types, set enableLogicalTypes to true .
We use the following conversion table to translate between Avro and Pinot data types. The conversions are done using the offical Avro methods present in org.apache.avro.Conversions.
Avro Data Type
Pinot Data Type
Comment
JSON
Thrift
Thrift requires the generated class using .thrift file to parse the data. The .class file should be available in the Pinot's classpath. You can put the files in the lib/ folder of Pinot distribution directory.
Parquet
Since 0.11.0 release, the Parquet record reader determines whether to use ParquetAvroRecordReader or ParquetNativeRecordReader to read records. The reader looks for the parquet.avro.schema or avro.schema key in the parquet file footer, and if present, uses the Avro reader.
You can change the record reader manually in case of a misconfiguration.
For the support of DECIMAL and other parquet native data types, always use ParquetNativeRecordReader.
For ParquetAvroRecordReader , you can refer to the for the type conversions.
ORC
ORC record reader supports the following data types -
ORC Data Type
Java Data Type
In LIST and MAP types, the object should only belong to one of the data types supported by Pinot.
Protocol Buffers
The reader requires a descriptor file to deserialize the data present in the files. You can generate the descriptor file (.desc) from the .proto file using the command -
Commonly, ingested data has a complex structure. For example, Avro schemas have records and arrays while JSON supports objects and arrays.
Apache Pinot's data model supports primitive data types (including int, long, float, double, BigDecimal, string, bytes), and limited multi-value types, such as an array of primitive types. Simple data types allow Pinot to build fast indexing structures for good query performance, but does require some handling of the complex structures.
There are two options for complex type handling:
Convert the complex-type data into a JSON string and then build a JSON index.
Use the built-in complex-type handling rules in the ingestion configuration.
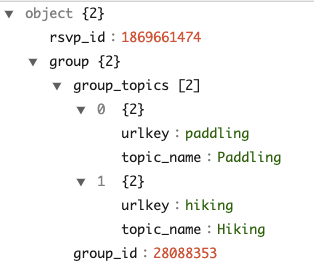
On this page, we'll show how to handle these complex-type structures with each of these two approaches. We will process some example data, consisting of the field group from the .
This object has two child fields and the child group is a nested array with elements of object type.
JSON indexing
Apache Pinot provides a powerful to accelerate the value lookup and filtering for the column. To convert an object group with complex type to JSON, add the following to your table configuration.
The config transformConfigs transforms the object group to a JSON string group_json, which then creates the JSON indexing with configuration jsonIndexColumns. To read the full spec, see .
Also, note that group is a reserved keyword in SQL and therefore needs to be quoted in transformFunction.
The columnName can't use the same name as any of the fields in the source JSON data, for example, if our source data contains the field group and we want to transform the data in that field before persisting it, the destination column name would need to be something different, like group_json.
Note that you do not need to worry about the maxLength of the field group_json on the schema, because "JSON" data type does not have a maxLength and will not be truncated. This is true even though "JSON" is stored as a string internally.
The schema will look like this:
For the full specification, see .
With this, you can start to query the nested fields under group. For more details about the supported JSON function, see ).
Ingestion configurations
Though JSON indexing is a handy way to process the complex types, there are some limitations:
It’s not performant to group by or order by a JSON field, because JSON_EXTRACT_SCALAR is needed to extract the values in the GROUP BY and ORDER BY clauses, which invokes the function evaluation.
It does not work with Pinot's such as DISTINCTCOUNTMV.
Alternatively, from Pinot 0.8, you can use the complex-type handling in ingestion configurations to flatten and unnest the complex structure and convert them into primitive types. Then you can reduce the complex-type data into a flattened Pinot table, and query it via SQL. With the built-in processing rules, you do not need to write ETL jobs in another compute framework such as Flink or Spark.
To process this complex type, you can add the configuration complexTypeConfig to the ingestionConfig. For example:
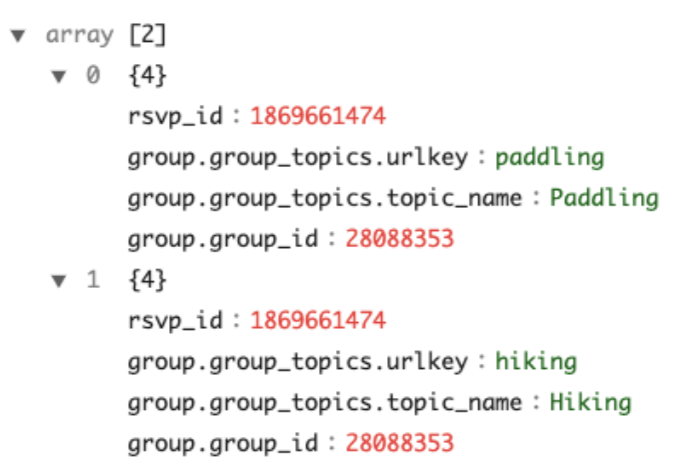
With the complexTypeConfig , all the map objects will be flattened to direct fields automatically. And with unnestFields , a record with the nested collection will unnest into multiple records. For instance, the example at the beginning will transform into two rows with this configuration example.
Note that:
The nested field group_id under group is flattened to group.group_id. The default value of the delimiter is . You can choose another delimiter by specifying the configuration delimiter under complexTypeConfig. This flattening rule also applies to maps in the collections to be unnested.
You can find the full specifications of the table config and the table schema .
You can then query the table with primitive values using the following SQL query:
. is a reserved character in SQL, so you need to quote the flattened columns in the query.
Infer the Pinot schema from the Avro schema and JSON data
When there are complex structures, it can be challenging and tedious to figure out the Pinot schema manually. To help with schema inference, Pinot provides utility tools to take the Avro schema or JSON data as input and output the inferred Pinot schema.
To infer the Pinot schema from Avro schema, you can use a command like this:
Note you can input configurations like fieldsToUnnest similar to the ones in complexTypeConfig. And this will simulate the complex-type handling rules on the Avro schema and output the Pinot schema in the file specified in outputDir.
Similarly, you can use the command like the following to infer the Pinot schema from a file of JSON objects.
You can check out an example of this run in this .
The nested array group_topics under group is unnested into the top-level, and converts the output to a collection of two rows. Note the handling of the nested field within group_topics, and the eventual top-level field of group.group_topics.urlkey. All the collections to unnest shall be included in the configuration fieldsToUnnest.
Collections not specified in fieldsToUnnestwill be serialized into JSON string, except for the array of primitive values, which will be ingested as a multi-value column by default. The behavior is defined by the collectionNotUnnestedToJson config, which takes the following values:
NON_PRIMITIVE- Converts the array to a multi-value column. (default)
ALL- Converts the array of primitive values to JSON string.