Creating Pinot Segments
Creating Pinot segments
Pinot segments can be created offline on Hadoop, or via command line from data files. Controller REST endpoint can then be used to add the segment to the table to which the segment belongs. Pinot segments can also be created by ingesting data from real-time resources (such as Kafka).
Creating segments using hadoop
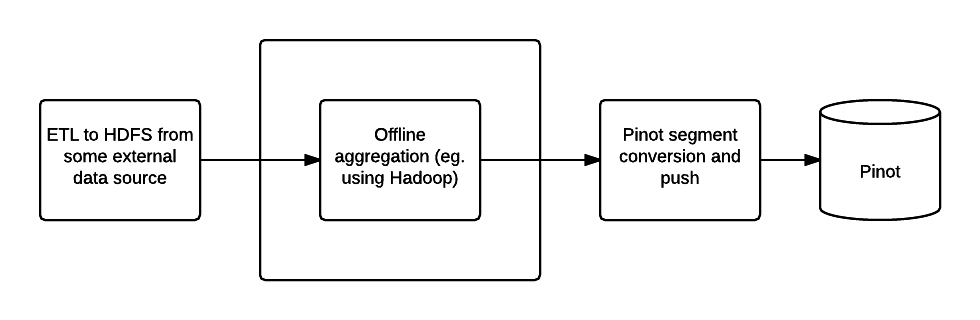
Offline Pinot workflow
To create Pinot segments on Hadoop, a workflow can be created to complete the following steps:
Pre-aggregate, clean up and prepare the data, writing it as Avro format files in a single HDFS directory
Upload segments to the Pinot cluster
Step one can be done using your favorite tool (such as Pig, Hive or Spark), Pinot provides two MapReduce jobs to do step two and three.
Configuring the job
Create a job properties configuration file, such as one below:
Executing the job
The Pinot Hadoop module contains a job that you can incorporate into your workflow to generate Pinot segments.
You can then use the SegmentTarPush job to push segments via the controller REST API.
Creating Pinot segments outside of Hadoop
Here is how you can create Pinot segments from standard formats like CSV/JSON/AVRO.
Follow the steps described in the section on to build pinot. Locate pinot-admin.sh in pinot-tools/target/pinot-tools=pkg/bin/pinot-admin.sh.
Create a top level directory containing all the CSV/JSON/AVRO files that need to be converted into segments.
Run the pinot-admin command to generate the segments. The command can be invoked as follows. Options within “[ ]” are optional. For -format, the default value is AVRO.
To configure various parameters for CSV a config file in JSON format can be provided. This file is optional, as are each of its parameters. When not provided, default values used for these parameters are described below:
fileFormat: Specify one of the following. Default is EXCEL.
Below is a sample config file.
Sample Schema:
Pushing offline segments to Pinot
You can use curl to push a segment to pinot:
Alternatively you can use the pinot-admin.sh utility to upload one or more segments:
The command uploads all the segments found in segmentDirectoryPath. The segments could be either tar-compressed (in which case it is a file under segmentDirectoryPath) or uncompressed (in which case it is a directory under segmentDirectoryPath).