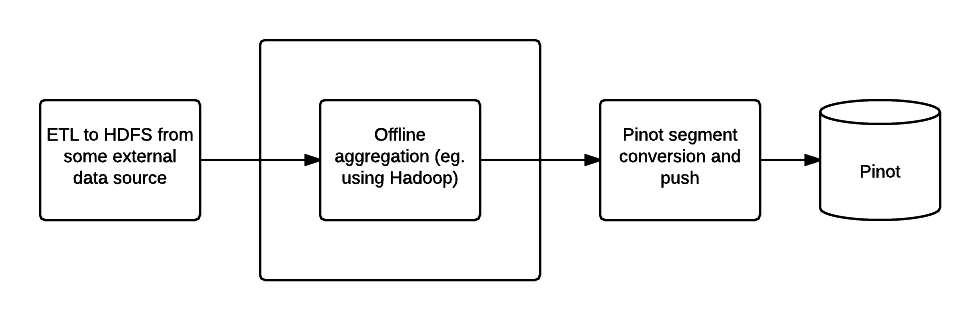
Configure AliCloud Object Storage Service (OSS) as Pinot deep storage
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
</configuration><?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>oss://your-bucket-name/</value>
</property>
<property>
<name>fs.oss.accessKeyId</name>
<value>your-access-key-id</value>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>your-access-key-secret</value>
</property>
<property>
<name>fs.oss.impl</name>
<value>com.aliyun.emr.fs.oss.OssFileSystem</value>
</property>
<property>
<name>fs.oss.endpoint</name>
<value>your-oss-endpoint</value>
</property>
</configuration>controller.data.dir=oss://your-bucket-name/path/to/segments
controller.local.temp.dir=/path/to/local/temp/directory
controller.enable.split.commit=true
pinot.controller.storage.factory.class.oss=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.controller.storage.factory.oss.hadoop.conf.path=path/to/conf/directory/
pinot.controller.segment.fetcher.protocols=file,http,oss
pinot.controller.segment.fetcher.oss.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.server.instance.enable.split.commit=true
pinot.server.storage.factory.class.oss=org.apache.pinot.plugin.filesystem.HadoopPinotFS
pinot.server.storage.factory.oss.hadoop.conf.path=path/to/conf/directory/
pinot.server.segment.fetcher.protocols=file,http,oss
pinot.server.segment.fetcher.oss.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherexecutionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentMetadataPushJobRunner'
jobType: SegmentCreationAndMetadataPush
inputDirURI: 'oss://your-bucket-name/input'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: 'oss://your-bucket-name/output'
overwriteOutput: true
pinotFSSpecs:
- scheme: oss
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
hadoop.conf.path: '/path/to/hadoop/conf'
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
pinotClusterSpecs:
- controllerURI: '<http://localhost:9000>'
timestampInEpoch,id,name,age,score
1597044264380,1,david,15,98
1597044264381,2,henry,16,97
1597044264382,3,katie,14,99
1597044264383,4,catelyn,15,96
1597044264384,5,emma,13,93
1597044264390,6,john,15,100
1597044264396,7,isabella,13,89
1597044264399,8,linda,17,91
1597044264502,9,mark,16,67
1597044264670,10,tom,14,78scala> val df = spark.read.format("csv").option("header", true).load("path/to/students.csv")
scala> df.write.option("compression","none").mode("overwrite").parquet("/path/to/batch_input/")aws s3 cp /path/to/batch_input s3://my-bucket/batch-input/ --recursive{
"schemaName": "students",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "INT"
},
{
"name": "name",
"dataType": "STRING"
},
{
"name": "age",
"dataType": "INT"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "INT"
}
],
"dateTimeFieldSpecs": [
{
"name": "timestampInEpoch",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}{
"tableName": "students",
"segmentsConfig": {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"replication": "1",
"schemaName": "students"
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"loadMode": "MMAP"
},
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant"
},
"tableType": "OFFLINE",
"metadata": {}
}pinot-admin.sh AddTable -tableConfigFile /path/to/student_table.json -schemaFile /path/to/student_schema.json -controllerHost localhost -controllerPort 9000 -execexecutionFrameworkSpec:
name: 'spark'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner'
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentMetadataPushJobRunner'
extraConfigs:
stagingDir: s3://my-bucket/spark/staging/
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
# 'SegmentCreationAndMetadataPush'
jobType: SegmentCreationAndMetadataPush
inputDirURI: 's3://my-bucket/path/to/batch-input/'
outputDirURI: 's3:///my-bucket/path/to/batch-output/'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'
recordReaderSpec:
dataFormat: 'parquet'
className: 'org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader'
tableSpec:
tableName: 'students'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000export PINOT_VERSION=0.10.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-${PINOT_VERSION}-bin
spark-submit //
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand //
--master local --deploy-mode client //
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dplugins.include=pinot-s3,pinot-parquet -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml" //
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark/pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-file-system/pinot-s3/pinot-s3-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-input-format/pinot-parquet/pinot-parquet-${PINOT_VERSION}-shaded.jar" //
--conf "spark.executor.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins-external/pinot-batch-ingestion/pinot-batch-ingestion-spark/pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-file-system/pinot-s3/pinot-s3-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-input-format/pinot-parquet/pinot-parquet-${PINOT_VERSION}-shaded.jar" //
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar -jobSpecFile /path/to/spark_job_spec.yamlbin/pinot-admin.sh PostQuery -brokerHost localhost -brokerPort 8000 -queryType sql -query "SELECT * FROM students LIMIT 10"{
"resultTable": {
"dataSchema": {
"columnNames": [
"age",
"id",
"name",
"score",
"timestampInEpoch"
],
"columnDataTypes": [
"INT",
"INT",
"STRING",
"INT",
"LONG"
]
},
"rows": [
[
15,
1,
"david",
98,
1597044264380
],
[
16,
2,
"henry",
97,
1597044264381
],
[
14,
3,
"katie",
99,
1597044264382
],
[
15,
4,
"catelyn",
96,
1597044264383
],
[
13,
5,
"emma",
93,
1597044264384
],
[
15,
6,
"john",
100,
1597044264390
],
[
13,
7,
"isabella",
89,
1597044264396
],
[
17,
8,
"linda",
91,
1597044264399
],
[
16,
9,
"mark",
67,
1597044264502
],
[
14,
10,
"tom",
78,
1597044264670
]
]
},
"exceptions": [],
"numServersQueried": 1,
"numServersResponded": 1,
"numSegmentsQueried": 1,
"numSegmentsProcessed": 1,
"numSegmentsMatched": 1,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 10,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 50,
"numGroupsLimitReached": false,
"totalDocs": 10,
"timeUsedMs": 11,
"segmentStatistics": [],
"traceInfo": {},
"minConsumingFreshnessTimeMs": 0
}.csv, .json or .avro), and are case insensitive. Note that the converter expects the .csv extension even if the data is delimited using tabs or spaces instead.# === Index segment creation job config ===
# path.to.input: Input directory containing Avro files
path.to.input=/user/pinot/input/data
# path.to.output: Output directory containing Pinot segments
path.to.output=/user/pinot/output
# path.to.schema: Schema file for the table, stored locally
path.to.schema=flights-schema.json
# segment.table.name: Name of the table for which to generate segments
segment.table.name=flights
# === Segment tar push job config ===
# push.to.hosts: Comma separated list of controllers host names to which to push
push.to.hosts=controller_host_0,controller_host_1
# push.to.port: The port on which the controller runs
push.to.port=8888mvn clean install -DskipTests -Pbuild-shaded-jar
hadoop jar pinot-hadoop-<version>-SNAPSHOT-shaded.jar SegmentCreation job.propertieshadoop jar pinot-hadoop-<version>-SNAPSHOT-shaded.jar SegmentTarPush job.propertiesbin/pinot-admin.sh CreateSegment -dataDir <input_data_dir> [-format [CSV/JSON/AVRO]] [-readerConfigFile <csv_config_file>] [-generatorConfigFile <generator_config_file>] -segmentName <segment_name> -schemaFile <input_schema_file> -tableName <table_name> -outDir <output_data_dir> [-overwrite]{
"fileFormat": "EXCEL",
"header": "col1,col2,col3,col4",
"delimiter": "\t",
"multiValueDelimiter": ","
}{
"schemaName": "flights",
"dimensionFieldSpecs": [
{
"name": "flightNumber",
"dataType": "LONG"
},
{
"name": "tags",
"dataType": "STRING",
"singleValueField": false
}
],
"metricFieldSpecs": [
{
"name": "price",
"dataType": "DOUBLE"
}
],
"timeFieldSpec": {
"incomingGranularitySpec": {
"name": "daysSinceEpoch",
"dataType": "INT",
"timeType": "DAYS"
}
}
}curl -X POST -F segment=@<segment-tar-file-path> http://controllerHost:controllerPort/segmentspinot-tools/target/pinot-tools-pkg/bin//pinot-admin.sh UploadSegment -controllerHost <hostname> -controllerPort <port> -segmentDir <segmentDirectoryPath>$ curl localhost:9000/schemas/baseballStats > baseballStats.schema{
"schemaName" : "baseballStats",
"dimensionFieldSpecs" : [ {
...
}, {
"name" : "yearsOfExperience",
"dataType" : "INT",
"defaultNullValue": 1
} ]
}bin/pinot-admin.sh AddSchema -schemaFile baseballStats.schema -exec$ curl -F [email protected] localhost:9000/schemas$ curl -X POST localhost:9000/segments/baseballStats/reload{"baseballStats_OFFLINE":{"reloadJobId":"c3989a04-9fd1-46af-85e8-00f484759ef2","reloadJobMetaZKStorageStatus":"SUCCESS","numMessagesSent":"3"}}$ curl -X GET localhost:9000/segments/segmentReloadStatus/c3989a04-9fd1-46af-85e8-00f484759ef2{
"estimatedTimeRemainingInMinutes": 0,
"timeElapsedInMinutes": 0.17655,
"totalServersQueried": 3,
"successCount": 12,
"totalSegmentCount": 12,
"totalServerCallsFailed": 0,
"metadata": {
"jobId": "c3989a04-9fd1-46af-85e8-00f484759ef2",
"messageCount": "3",
"submissionTimeMs": "1661753088066",
"jobType": "RELOAD_ALL_SEGMENTS",
"tableName": "baseballStats_OFFLINE"
}
}$ bin/pinot-admin.sh PostQuery \
-queryType sql \
-brokerPort 8000 \
-query "select playerID, yearsOfExperience from baseballStats limit 10" 2>/dev/nullExecuting command: PostQuery -brokerHost 192.168.86.234 -brokerPort 8000 -queryType sql -query select playerID, yearsOfExperience from baseballStats limit 10
Result: {"resultTable":{"dataSchema":{"columnNames":["playerID","yearsOfExperience"],"columnDataTypes":["STRING","INT"]},"rows":[["aardsda01",1],["aardsda01",1],["aardsda01",1],["aardsda01",1],["aardsda01",1],["aardsda01",1],["aardsda01",1],["aaronha01",1],["aaronha01",1],["aaronha01",1]]},"exceptions":[],"numServersQueried":1,"numServersResponded":1,"numSegmentsQueried":1,"numSegmentsProcessed":1,"numSegmentsMatched":1,"numConsumingSegmentsQueried":0,"numDocsScanned":10,"numEntriesScannedInFilter":0,"numEntriesScannedPostFilter":20,"numGroupsLimitReached":false,"totalDocs":97889,"timeUsedMs":3,"segmentStatistics":[],"traceInfo":{},"minConsumingFreshnessTimeMs":0}AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY (RECOMMENDED since they are recognized by all the AWS SDKs and CLI except for .NET), or AWS_ACCESS_KEY and AWS_SECRET_KEY (only recognized by Java SDK)- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'docker network create -d bridge pinot-demodocker run \
--name zookeeper \
--restart always \
--network=pinot-demo \
-d zookeeper:3.5.6/tmp/pinot-s3-docker/
controller.conf
server.conf
ingestionJobSpec.yamlpinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=us-west-2pinot.role=controller
pinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=us-west-2
controller.data.dir=s3://<my-bucket>/pinot-data/pinot-s3-example-docker/controller-data/
controller.local.temp.dir=/tmp/pinot-tmp-data/
controller.helix.cluster.name=pinot-s3-example-docker
controller.zk.str=zookeeper:2181
controller.port=9000
controller.enable.split.commit=true
pinot.controller.segment.fetcher.protocols=file,http,s3
pinot.controller.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherdocker run --rm -ti \
--name pinot-controller \
--network=pinot-demo \
-p 9000:9000 \
--env AWS_ACCESS_KEY_ID=<aws-access-key-id> \
--env AWS_SECRET_ACCESS_KEY=<aws-secret-access-key> \
--mount type=bind,source=/tmp/pinot-s3-docker,target=/tmp \
apachepinot/pinot:0.6.0-SNAPSHOT-ca8545b29-20201105-jdk11 StartController \
-configFileName /tmp/controller.confdocker run --rm -ti \
--name pinot-broker \
--network=pinot-demo \
--env AWS_ACCESS_KEY_ID=<aws-access-key-id> \
--env AWS_SECRET_ACCESS_KEY=<aws-secret-access-key> \
apachepinot/pinot:0.6.0-SNAPSHOT-ca8545b29-20201105-jdk11 StartBroker \
-zkAddress zookeeper:2181 -clusterName pinot-s3-example-dockerpinot.server.netty.port=8098
pinot.server.adminapi.port=8097
pinot.server.instance.dataDir=/tmp/pinot-tmp/server/index
pinot.server.instance.segmentTarDir=/tmp/pinot-tmp/server/segmentTars
pinot.server.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.server.storage.factory.s3.region=us-west-2
pinot.server.segment.fetcher.protocols=file,http,s3
pinot.server.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherdocker run --rm -ti \
--name pinot-server \
--network=pinot-demo \
--env AWS_ACCESS_KEY_ID=<aws-access-key-id> \
--env AWS_SECRET_ACCESS_KEY=<aws-secret-access-key> \
--mount type=bind,source=/tmp/pinot-s3-docker,target=/tmp \
apachepinot/pinot:0.6.0-SNAPSHOT-ca8545b29-20201105-jdk11 StartServer \
-zkAddress zookeeper:2181 -clusterName pinot-s3-example-docker \
-configFileName /tmp/server.confdocker run --rm -ti \
--name pinot-ingestion-job \
--network=pinot-demo \
apachepinot/pinot:0.6.0-SNAPSHOT-ca8545b29-20201105-jdk11 AddTable \
-controllerHost pinot-controller \
-controllerPort 9000 \
-schemaFile examples/batch/airlineStats/airlineStats_schema.json \
-tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json \
-exec# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'standalone'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
# segmentMetadataPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.IngestionJobRunner interface.
segmentMetadataPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentMetadataPushJobRunner'
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
jobType: SegmentCreationAndMetadataPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 's3://<my-bucket>/pinot-data/rawdata/airlineStats/rawdata/'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will exclude all the avro files under inputDirURI recursively.
# _excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 's3://<my-bucket>/pinot-data/pinot-s3-docker/segments/airlineStats'
# segmentCreationJobParallelism: The parallelism to create egments.
segmentCreationJobParallelism: 5
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.spi.filesystem.LocalPinotFS
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://pinot-controller:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://pinot-controller:9000/tables/airlineStats'
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://pinot-controller:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000
docker run --rm -ti \
--name pinot-ingestion-job \
--network=pinot-demo \
--env AWS_ACCESS_KEY_ID=<aws-access-key-id> \
--env AWS_SECRET_ACCESS_KEY=<aws-secret-access-key> \
--mount type=bind,source=/tmp/pinot-s3-docker,target=/tmp \
apachepinot/pinot:0.6.0-SNAPSHOT-ca8545b29-20201105-jdk11 LaunchDataIngestionJob \
-jobSpecFile /tmp/ingestionJobSpec.yamlpinot.controller.storage.factory.s3.accessKey=****************LFVX
pinot.controller.storage.factory.s3.secretKey=****************gfhzAWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY (RECOMMENDED since they are recognized by all the AWS SDKs and CLI except for .NET), or AWS_ACCESS_KEY and AWS_SECRET_KEY (only recognized by Java SDK)- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'pinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=us-west-2controller.data.dir=s3://my.bucket/pinot-data/pinot-s3-example/controller-data
controller.local.temp.dir=/tmp/pinot-tmp-data/
controller.zk.str=localhost:2181
controller.host=127.0.0.1
controller.port=9000
controller.helix.cluster.name=pinot-s3-example
pinot.controller.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.controller.storage.factory.s3.region=us-west-2
pinot.controller.segment.fetcher.protocols=file,http,s3
pinot.controller.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.controller.storage.factory.s3.disableAcl=falsebin/pinot-admin.sh StartController -configFileName conf/controller.confbin/pinot-admin.sh StartBroker -zkAddress localhost:2181 -clusterName pinot-s3-examplepinot.server.netty.port=8098
pinot.server.adminapi.port=8097
pinot.server.instance.dataDir=/tmp/pinot-tmp/server/index
pinot.server.instance.segmentTarDir=/tmp/pinot-tmp/server/segmentTars
pinot.server.storage.factory.class.s3=org.apache.pinot.plugin.filesystem.S3PinotFS
pinot.server.storage.factory.s3.region=us-west-2
pinot.server.segment.fetcher.protocols=file,http,s3
pinot.server.segment.fetcher.s3.class=org.apache.pinot.common.utils.fetcher.PinotFSSegmentFetcherpinot.controller.storage.factory.s3.disableAcl=falsebin/pinot-admin.sh StartServer -configFileName conf/server.conf -zkAddress localhost:2181 -clusterName pinot-s3-examplebin/pinot-admin.sh AddTable -schemaFile examples/batch/airlineStats/airlineStats_schema.json -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -exec# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'standalone'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
#jobType: SegmentCreationAndUriPush
jobType: SegmentCreationAndUriPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 's3://my.bucket/batch/airlineStats/rawdata/'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will exclude all the avro files under inputDirURI recursively.
# _excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 's3://my.bucket/examples/output/airlineStats/segments'
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.spi.filesystem.LocalPinotFS
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://localhost:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://localhost:9000/tables/airlineStats'
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://localhost:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000
# For Pinot version < 0.6.0, use [scheme]://[bucket.name] as prefix.
# E.g. s3://my.bucket
segmentUriPrefix: 's3://my.bucket'
segmentUriSuffix: ''bin/pinot-admin.sh LaunchDataIngestionJob -jobSpecFile ~/temp/pinot/pinot-s3-test/ingestionJobSpec.yaml2020/08/18 16:11:03.521 INFO [IngestionJobLauncher] [main] SegmentGenerationJobSpec:
!!org.apache.pinot.spi.ingestion.batch.spec.SegmentGenerationJobSpec
excludeFileNamePattern: null
executionFrameworkSpec: {extraConfigs: null, name: standalone, segmentGenerationJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner,
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner,
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner}
includeFileNamePattern: glob:**/*.avro
inputDirURI: s3://my.bucket/batch/airlineStats/rawdata/
jobType: SegmentUriPush
outputDirURI: s3://my.bucket/examples/output/airlineStats/segments
overwriteOutput: true
pinotClusterSpecs:
- {controllerURI: 'http://localhost:9000'}
pinotFSSpecs:
- {className: org.apache.pinot.spi.filesystem.LocalPinotFS, configs: null, scheme: file}
- className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs: {region: us-west-2}
scheme: s3
pushJobSpec: {pushAttempts: 2, pushParallelism: 1, pushRetryIntervalMillis: 1000,
segmentUriPrefix: '', segmentUriSuffix: ''}
recordReaderSpec: {className: org.apache.pinot.plugin.inputformat.avro.AvroRecordReader,
configClassName: null, configs: null, dataFormat: avro}
segmentNameGeneratorSpec: null
tableSpec: {schemaURI: 'http://localhost:9000/tables/airlineStats/schema', tableConfigURI: 'http://localhost:9000/tables/airlineStats',
tableName: airlineStats}
2020/08/18 16:11:03.531 INFO [IngestionJobLauncher] [main] Trying to create instance for class org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner
2020/08/18 16:11:03.654 INFO [PinotFSFactory] [main] Initializing PinotFS for scheme file, classname org.apache.pinot.spi.filesystem.LocalPinotFS
2020/08/18 16:11:03.656 INFO [PinotFSFactory] [main] Initializing PinotFS for scheme s3, classname org.apache.pinot.plugin.filesystem.S3PinotFS
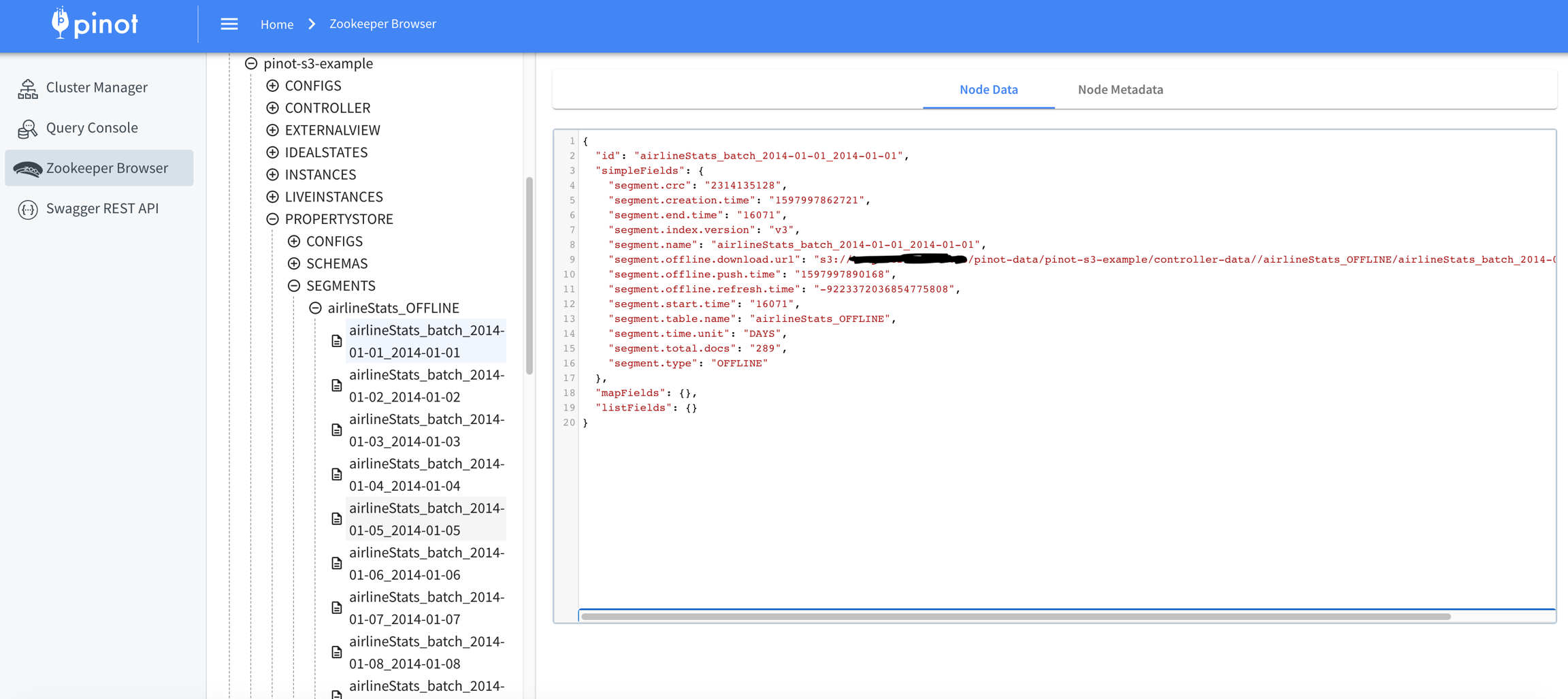
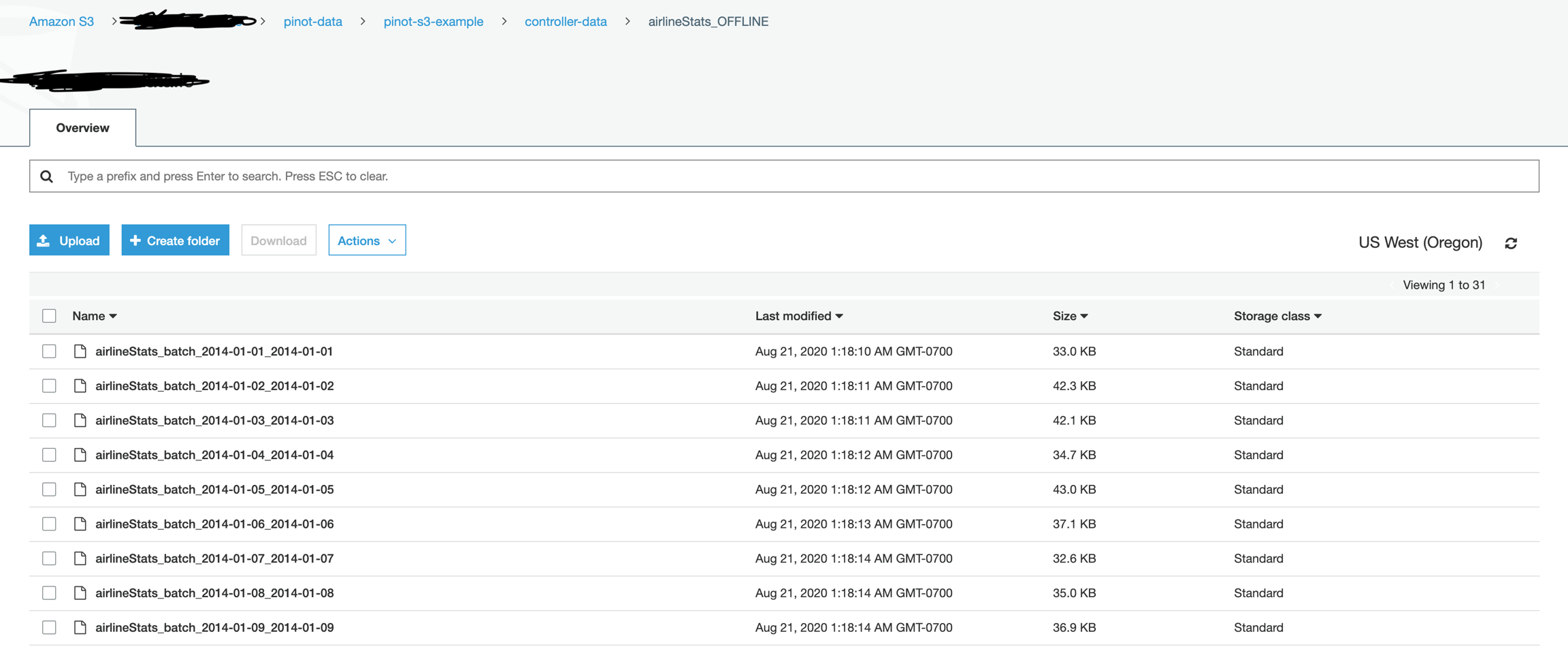
2020/08/18 16:11:05.520 INFO [SegmentPushUtils] [main] Start sending table airlineStats segment URIs: [s3://my.bucket/examples/output/airlineStats/segments/2014/01/01/airlineStats_OFFLINE_16071_16071_0.tar.gz, s3://my.bucket/examples/output/airlineStats/segments/2014/01/02/airlineStats_OFFLINE_16072_16072_1.tar.gz, s3://my.bucket/examples/output/airlineStats/segments/2014/01/03/airlineStats_OFFLINE_16073_16073_2.tar.gz, s3://my.bucket/examples/output/airlineStats/segments/2014/01/04/airlineStats_OFFLINE_16074_16074_3.tar.gz, s3://my.bucket/examples/output/airlineStats/segments/2014/01/05/airlineStats_OFFLINE_16075_16075_4.tar.gz] to locations: [org.apache.pinot.spi.ingestion.batch.spec.PinotClusterSpec@4e07b95f]
2020/08/18 16:11:05.521 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/01/airlineStats_OFFLINE_16071_16071_0.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:09.356 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:09.358 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/01/airlineStats_OFFLINE_16071_16071_0.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16071_16071_0 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:09.359 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/02/airlineStats_OFFLINE_16072_16072_1.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:09.824 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:09.825 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/02/airlineStats_OFFLINE_16072_16072_1.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16072_16072_1 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:09.825 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/03/airlineStats_OFFLINE_16073_16073_2.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:10.500 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:10.501 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/03/airlineStats_OFFLINE_16073_16073_2.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16073_16073_2 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:10.501 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/04/airlineStats_OFFLINE_16074_16074_3.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:10.967 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:10.968 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/04/airlineStats_OFFLINE_16074_16074_3.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16074_16074_3 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:10.969 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/05/airlineStats_OFFLINE_16075_16075_4.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:11.420 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:11.420 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/05/airlineStats_OFFLINE_16075_16075_4.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16075_16075_4 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:11.421 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/06/airlineStats_OFFLINE_16076_16076_5.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:11.872 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:11.873 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/06/airlineStats_OFFLINE_16076_16076_5.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16076_16076_5 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:11.877 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/07/airlineStats_OFFLINE_16077_16077_6.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:12.293 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:12.294 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/07/airlineStats_OFFLINE_16077_16077_6.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16077_16077_6 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:12.295 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/08/airlineStats_OFFLINE_16078_16078_7.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:12.672 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:12.673 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/08/airlineStats_OFFLINE_16078_16078_7.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16078_16078_7 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:12.674 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/09/airlineStats_OFFLINE_16079_16079_8.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:13.048 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:13.050 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/09/airlineStats_OFFLINE_16079_16079_8.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16079_16079_8 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:13.051 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/10/airlineStats_OFFLINE_16080_16080_9.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:13.483 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:13.485 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/10/airlineStats_OFFLINE_16080_16080_9.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16080_16080_9 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:13.486 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/11/airlineStats_OFFLINE_16081_16081_10.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:14.080 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:14.081 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/11/airlineStats_OFFLINE_16081_16081_10.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16081_16081_10 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:14.082 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/12/airlineStats_OFFLINE_16082_16082_11.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:14.477 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:14.477 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/12/airlineStats_OFFLINE_16082_16082_11.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16082_16082_11 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:14.478 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/13/airlineStats_OFFLINE_16083_16083_12.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:14.865 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:14.866 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/13/airlineStats_OFFLINE_16083_16083_12.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16083_16083_12 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:14.867 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/14/airlineStats_OFFLINE_16084_16084_13.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:15.257 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:15.258 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/14/airlineStats_OFFLINE_16084_16084_13.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16084_16084_13 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:15.258 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/15/airlineStats_OFFLINE_16085_16085_14.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:15.917 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:15.919 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/15/airlineStats_OFFLINE_16085_16085_14.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16085_16085_14 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:15.919 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/16/airlineStats_OFFLINE_16086_16086_15.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:16.719 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:16.720 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/16/airlineStats_OFFLINE_16086_16086_15.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16086_16086_15 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:16.720 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/17/airlineStats_OFFLINE_16087_16087_16.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:17.346 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:17.347 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/17/airlineStats_OFFLINE_16087_16087_16.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16087_16087_16 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:17.347 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/18/airlineStats_OFFLINE_16088_16088_17.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:17.815 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:17.816 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/18/airlineStats_OFFLINE_16088_16088_17.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16088_16088_17 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:17.816 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/19/airlineStats_OFFLINE_16089_16089_18.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:18.389 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:18.389 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/19/airlineStats_OFFLINE_16089_16089_18.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16089_16089_18 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:18.390 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/20/airlineStats_OFFLINE_16090_16090_19.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:18.978 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:18.978 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/20/airlineStats_OFFLINE_16090_16090_19.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16090_16090_19 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:18.979 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/21/airlineStats_OFFLINE_16091_16091_20.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:19.586 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:19.587 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/21/airlineStats_OFFLINE_16091_16091_20.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16091_16091_20 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:19.589 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/22/airlineStats_OFFLINE_16092_16092_21.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:20.087 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:20.087 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/22/airlineStats_OFFLINE_16092_16092_21.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16092_16092_21 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:20.088 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/23/airlineStats_OFFLINE_16093_16093_22.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:20.550 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:20.551 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/23/airlineStats_OFFLINE_16093_16093_22.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16093_16093_22 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:20.552 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/24/airlineStats_OFFLINE_16094_16094_23.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:20.978 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:20.979 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/24/airlineStats_OFFLINE_16094_16094_23.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16094_16094_23 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:20.979 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/25/airlineStats_OFFLINE_16095_16095_24.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:21.626 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:21.628 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/25/airlineStats_OFFLINE_16095_16095_24.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16095_16095_24 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:21.628 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/26/airlineStats_OFFLINE_16096_16096_25.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:22.121 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:22.122 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/26/airlineStats_OFFLINE_16096_16096_25.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16096_16096_25 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:22.123 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/27/airlineStats_OFFLINE_16097_16097_26.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:22.679 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:22.679 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/27/airlineStats_OFFLINE_16097_16097_26.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16097_16097_26 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:22.680 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/28/airlineStats_OFFLINE_16098_16098_27.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:23.373 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:23.374 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/28/airlineStats_OFFLINE_16098_16098_27.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16098_16098_27 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:23.375 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/29/airlineStats_OFFLINE_16099_16099_28.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:23.787 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:23.788 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/29/airlineStats_OFFLINE_16099_16099_28.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16099_16099_28 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:23.788 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/30/airlineStats_OFFLINE_16100_16100_29.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:24.298 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:24.299 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/30/airlineStats_OFFLINE_16100_16100_29.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16100_16100_29 of table: airlineStats_OFFLINE"}
2020/08/18 16:11:24.299 INFO [SegmentPushUtils] [main] Sending table airlineStats segment URI: s3://my.bucket/examples/output/airlineStats/segments/2014/01/31/airlineStats_OFFLINE_16101_16101_30.tar.gz to location: http://localhost:9000 for
2020/08/18 16:11:24.987 INFO [FileUploadDownloadClient] [main] Sending request: http://localhost:9000/v2/segments to controller: localhost, version: Unknown
2020/08/18 16:11:24.987 INFO [SegmentPushUtils] [main] Response for pushing table airlineStats segment uri s3://my.bucket/examples/output/airlineStats/segments/2014/01/31/airlineStats_OFFLINE_16101_16101_30.tar.gz to location http://localhost:9000 - 200: {"status":"Successfully uploaded segment: airlineStats_OFFLINE_16101_16101_30 of table: airlineStats_OFFLINE"}# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'spark'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner'
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
jobType: SegmentCreationAndUriPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 's3://my.bucket/batch/airlineStats/rawdata/'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**/*.avro' will exclude all the avro files under inputDirURI recursively.
# _excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 's3://my.bucket/examples/output/airlineStats/segments'
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
configs:
'hadoop.conf.path': ''
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: 'us-west-2'
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://localhost:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://localhost:9000/tables/airlineStats'
# segmentNameGeneratorSpec: defines how to init a SegmentNameGenerator.
segmentNameGeneratorSpec:
# type: Current supported type is 'simple' and 'normalizedDate'.
type: normalizedDate
# configs: Configs to init SegmentNameGenerator.
configs:
segment.name.prefix: 'airlineStats_batch'
exclude.sequence.id: true
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://localhost:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# pushParallelism: push job parallelism, default is 1.
pushParallelism: 2
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000${SPARK_HOME}/bin/spark-submit \
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand \
--master "local[2]" \
--deploy-mode client \
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml" \
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" \
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \
-jobSpecFile ${PINOT_DISTRIBUTION_DIR}/examples/sparkIngestionJobSpec.yamlpinot.controller.storage.factory.s3.accessKey=****************LFVX
pinot.controller.storage.factory.s3.secretKey=****************gfhz-Dplugins.dir=${CLASSPATH}/var/pinot/airlineStats/rawdata/2014/01/01/airlineStats_data_2014-01-01.avro
/var/pinot/airlineStats/rawdata/2014/01/02/airlineStats_data_2014-01-02.avro
/var/pinot/airlineStats/rawdata/2014/01/03/airlineStats_data_2014-01-03.avro
/var/pinot/airlineStats/rawdata/2014/01/04/airlineStats_data_2014-01-04.avro
/var/pinot/airlineStats/rawdata/2014/01/05/airlineStats_data_2014-01-05.avro
/var/pinot/airlineStats/rawdata/2014/01/06/airlineStats_data_2014-01-06.avro
/var/pinot/airlineStats/rawdata/2014/01/07/airlineStats_data_2014-01-07.avro
/var/pinot/airlineStats/rawdata/2014/01/08/airlineStats_data_2014-01-08.avro
/var/pinot/airlineStats/rawdata/2014/01/09/airlineStats_data_2014-01-09.avro
/var/pinot/airlineStats/rawdata/2014/01/10/airlineStats_data_2014-01-10.avro
/var/pinot/airlineStats/rawdata/2014/01/11/airlineStats_data_2014-01-11.avro
/var/pinot/airlineStats/rawdata/2014/01/12/airlineStats_data_2014-01-12.avro
/var/pinot/airlineStats/rawdata/2014/01/13/airlineStats_data_2014-01-13.avro
/var/pinot/airlineStats/rawdata/2014/01/14/airlineStats_data_2014-01-14.avro
/var/pinot/airlineStats/rawdata/2014/01/15/airlineStats_data_2014-01-15.avro
/var/pinot/airlineStats/rawdata/2014/01/16/airlineStats_data_2014-01-16.avro
/var/pinot/airlineStats/rawdata/2014/01/17/airlineStats_data_2014-01-17.avro
/var/pinot/airlineStats/rawdata/2014/01/18/airlineStats_data_2014-01-18.avro
/var/pinot/airlineStats/rawdata/2014/01/19/airlineStats_data_2014-01-19.avro
/var/pinot/airlineStats/rawdata/2014/01/20/airlineStats_data_2014-01-20.avro
/var/pinot/airlineStats/rawdata/2014/01/21/airlineStats_data_2014-01-21.avro
/var/pinot/airlineStats/rawdata/2014/01/22/airlineStats_data_2014-01-22.avro
/var/pinot/airlineStats/rawdata/2014/01/23/airlineStats_data_2014-01-23.avro
/var/pinot/airlineStats/rawdata/2014/01/24/airlineStats_data_2014-01-24.avro
/var/pinot/airlineStats/rawdata/2014/01/25/airlineStats_data_2014-01-25.avro
/var/pinot/airlineStats/rawdata/2014/01/26/airlineStats_data_2014-01-26.avro
/var/pinot/airlineStats/rawdata/2014/01/27/airlineStats_data_2014-01-27.avro
/var/pinot/airlineStats/rawdata/2014/01/28/airlineStats_data_2014-01-28.avro
/var/pinot/airlineStats/rawdata/2014/01/29/airlineStats_data_2014-01-29.avro
/var/pinot/airlineStats/rawdata/2014/01/30/airlineStats_data_2014-01-30.avro
/var/pinot/airlineStats/rawdata/2014/01/31/airlineStats_data_2014-01-31.avro# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'standalone'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
jobType: SegmentCreationAndTarPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 'examples/batch/airlineStats/rawdata'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will exclude all the avro files under inputDirURI recursively.
# _excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 'examples/batch/airlineStats/segments'
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# Create a separated metadata only tar gz file to reduce the data transfer of segment metadata push job.
createMetadataTarGz: true
# Job parallelism for segment creation
segmentCreationJobParallelism: 4
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.spi.filesystem.LocalPinotFS
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://localhost:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://localhost:9000/tables/airlineStats'
# segmentNameGeneratorSpec: defines how to init a SegmentNameGenerator.
segmentNameGeneratorSpec:
# type: Current supported type is 'simple' and 'normalizedDate'.
type: normalizedDate
# configs: Configs to init SegmentNameGenerator.
configs:
segment.name.prefix: 'airlineStats_batch'
exclude.sequence.id: true
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://localhost:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# Job parallelism for segment push
pushParallelism: 4
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000
# Applicable for URI and METADATA push types.
#If true, and if segment was not already in the deep store, move it to deep store.
copyToDeepStoreForMetadataPush: false
# Prefer using segment metadata tar gz file to push segment if exists.
preferMetadataTarGz: truebin/pinot-admin.sh AddTable -schemaFile examples/batch/airlineStats/airlineStats_schema.json -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -execbin/pinot-admin.sh LaunchDataIngestionJob -jobSpecFile examples/batch/airlineStats/ingestionJobSpec.yaml/var/pinot/airlineStats/segments/2014/01/01/airlineStats_batch_2014-01-01_2014-01-01.tar.gz
/var/pinot/airlineStats/segments/2014/01/02/airlineStats_batch_2014-01-02_2014-01-02.tar.gz
/var/pinot/airlineStats/segments/2014/01/03/airlineStats_batch_2014-01-03_2014-01-03.tar.gz
/var/pinot/airlineStats/segments/2014/01/04/airlineStats_batch_2014-01-04_2014-01-04.tar.gz
/var/pinot/airlineStats/segments/2014/01/05/airlineStats_batch_2014-01-05_2014-01-05.tar.gz
/var/pinot/airlineStats/segments/2014/01/06/airlineStats_batch_2014-01-06_2014-01-06.tar.gz
/var/pinot/airlineStats/segments/2014/01/07/airlineStats_batch_2014-01-07_2014-01-07.tar.gz
/var/pinot/airlineStats/segments/2014/01/08/airlineStats_batch_2014-01-08_2014-01-08.tar.gz
/var/pinot/airlineStats/segments/2014/01/09/airlineStats_batch_2014-01-09_2014-01-09.tar.gz
/var/pinot/airlineStats/segments/2014/01/10/airlineStats_batch_2014-01-10_2014-01-10.tar.gz
/var/pinot/airlineStats/segments/2014/01/11/airlineStats_batch_2014-01-11_2014-01-11.tar.gz
/var/pinot/airlineStats/segments/2014/01/12/airlineStats_batch_2014-01-12_2014-01-12.tar.gz
/var/pinot/airlineStats/segments/2014/01/13/airlineStats_batch_2014-01-13_2014-01-13.tar.gz
/var/pinot/airlineStats/segments/2014/01/14/airlineStats_batch_2014-01-14_2014-01-14.tar.gz
/var/pinot/airlineStats/segments/2014/01/15/airlineStats_batch_2014-01-15_2014-01-15.tar.gz
/var/pinot/airlineStats/segments/2014/01/16/airlineStats_batch_2014-01-16_2014-01-16.tar.gz
/var/pinot/airlineStats/segments/2014/01/17/airlineStats_batch_2014-01-17_2014-01-17.tar.gz
/var/pinot/airlineStats/segments/2014/01/18/airlineStats_batch_2014-01-18_2014-01-18.tar.gz
/var/pinot/airlineStats/segments/2014/01/19/airlineStats_batch_2014-01-19_2014-01-19.tar.gz
/var/pinot/airlineStats/segments/2014/01/20/airlineStats_batch_2014-01-20_2014-01-20.tar.gz
/var/pinot/airlineStats/segments/2014/01/21/airlineStats_batch_2014-01-21_2014-01-21.tar.gz
/var/pinot/airlineStats/segments/2014/01/22/airlineStats_batch_2014-01-22_2014-01-22.tar.gz
/var/pinot/airlineStats/segments/2014/01/23/airlineStats_batch_2014-01-23_2014-01-23.tar.gz
/var/pinot/airlineStats/segments/2014/01/24/airlineStats_batch_2014-01-24_2014-01-24.tar.gz
/var/pinot/airlineStats/segments/2014/01/25/airlineStats_batch_2014-01-25_2014-01-25.tar.gz
/var/pinot/airlineStats/segments/2014/01/26/airlineStats_batch_2014-01-26_2014-01-26.tar.gz
/var/pinot/airlineStats/segments/2014/01/27/airlineStats_batch_2014-01-27_2014-01-27.tar.gz
/var/pinot/airlineStats/segments/2014/01/28/airlineStats_batch_2014-01-28_2014-01-28.tar.gz
/var/pinot/airlineStats/segments/2014/01/29/airlineStats_batch_2014-01-29_2014-01-29.tar.gz
/var/pinot/airlineStats/segments/2014/01/30/airlineStats_batch_2014-01-30_2014-01-30.tar.gz
/var/pinot/airlineStats/segments/2014/01/31/airlineStats_batch_2014-01-31_2014-01-31.tar.gzwget https://downloads.apache.org/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
tar xvf spark-2.4.6-bin-hadoop2.7.tgz
cd spark-2.4.6-bin-hadoop2.7
./bin/spark-shell --master 'local[2]'# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'spark'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: examples/batch/airlineStats/staging
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
jobType: SegmentCreationAndTarPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 'examples/batch/airlineStats/rawdata'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will exclude all the avro files under inputDirURI recursively.
# excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 'examples/batch/airlineStats/segments'
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://localhost:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://localhost:9000/tables/airlineStats'
# segmentNameGeneratorSpec: defines how to init a SegmentNameGenerator.
segmentNameGeneratorSpec:
# type: Current supported type is 'simple' and 'normalizedDate'.
type: normalizedDate
# configs: Configs to init SegmentNameGenerator.
configs:
segment.name.prefix: 'airlineStats_batch'
exclude.sequence.id: true
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://localhost:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# pushParallelism: push job parallelism, default is 1.
pushParallelism: 2
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000export PINOT_VERSION=0.10.0-SNAPSHOT
export PINOT_DISTRIBUTION_DIR=${PINOT_ROOT_DIR}/build/
cd ${PINOT_DISTRIBUTION_DIR}
${SPARK_HOME}/bin/spark-submit \
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand \
--master "local[2]" \
--deploy-mode client \
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml" \
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar" \
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \
-jobSpecFile ${PINOT_DISTRIBUTION_DIR}/examples/batch/airlineStats/sparkIngestionJobSpec.yaml# executionFrameworkSpec: Defines ingestion jobs to be running.
executionFrameworkSpec:
# name: execution framework name
name: 'hadoop'
# segmentGenerationJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentGenerationJobRunner interface.
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentGenerationJobRunner'
# segmentTarPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentTarPushJobRunner interface.
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentTarPushJobRunner'
# segmentUriPushJobRunnerClassName: class name implements org.apache.pinot.spi.batch.ingestion.runner.SegmentUriPushJobRunner interface.
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.hadoop.HadoopSegmentUriPushJobRunner'
# extraConfigs: extra configs for execution framework.
extraConfigs:
# stagingDir is used in distributed filesystem to host all the segments then move this directory entirely to output directory.
stagingDir: examples/batch/airlineStats/staging
# jobType: Pinot ingestion job type.
# Supported job types are:
# 'SegmentCreation'
# 'SegmentTarPush'
# 'SegmentUriPush'
# 'SegmentCreationAndTarPush'
# 'SegmentCreationAndUriPush'
jobType: SegmentCreationAndTarPush
# inputDirURI: Root directory of input data, expected to have scheme configured in PinotFS.
inputDirURI: 'examples/batch/airlineStats/rawdata'
# includeFileNamePattern: include file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will include all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will include all the avro files under inputDirURI recursively.
includeFileNamePattern: 'glob:**/*.avro'
# excludeFileNamePattern: exclude file name pattern, supported glob pattern.
# Sample usage:
# 'glob:*.avro' will exclude all avro files just under the inputDirURI, not sub directories;
# 'glob:**\/*.avro' will exclude all the avro files under inputDirURI recursively.
# _excludeFileNamePattern: ''
# outputDirURI: Root directory of output segments, expected to have scheme configured in PinotFS.
outputDirURI: 'examples/batch/airlineStats/segments'
# overwriteOutput: Overwrite output segments if existed.
overwriteOutput: true
# pinotFSSpecs: defines all related Pinot file systems.
pinotFSSpecs:
- # scheme: used to identify a PinotFS.
# E.g. local, hdfs, dbfs, etc
scheme: file
# className: Class name used to create the PinotFS instance.
# E.g.
# org.apache.pinot.spi.filesystem.LocalPinotFS is used for local filesystem
# org.apache.pinot.plugin.filesystem.AzurePinotFS is used for Azure Data Lake
# org.apache.pinot.plugin.filesystem.HadoopPinotFS is used for HDFS
className: org.apache.pinot.plugin.filesystem.HadoopPinotFS
# recordReaderSpec: defines all record reader
recordReaderSpec:
# dataFormat: Record data format, e.g. 'avro', 'parquet', 'orc', 'csv', 'json', 'thrift' etc.
dataFormat: 'avro'
# className: Corresponding RecordReader class name.
# E.g.
# org.apache.pinot.plugin.inputformat.avro.AvroRecordReader
# org.apache.pinot.plugin.inputformat.csv.CSVRecordReader
# org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
# org.apache.pinot.plugin.inputformat.json.JSONRecordReader
# org.apache.pinot.plugin.inputformat.orc.ORCRecordReader
# org.apache.pinot.plugin.inputformat.thrift.ThriftRecordReader
className: 'org.apache.pinot.plugin.inputformat.avro.AvroRecordReader'
# tableSpec: defines table name and where to fetch corresponding table config and table schema.
tableSpec:
# tableName: Table name
tableName: 'airlineStats'
# schemaURI: defines where to read the table schema, supports PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_schema.json
# http://localhost:9000/tables/myTable/schema
schemaURI: 'http://localhost:9000/tables/airlineStats/schema'
# tableConfigURI: defines where to reade the table config.
# Supports using PinotFS or HTTP.
# E.g.
# hdfs://path/to/table_config.json
# http://localhost:9000/tables/myTable
# Note that the API to read Pinot table config directly from pinot controller contains a JSON wrapper.
# The real table config is the object under the field 'OFFLINE'.
tableConfigURI: 'http://localhost:9000/tables/airlineStats'
# segmentNameGeneratorSpec: defines how to init a SegmentNameGenerator.
segmentNameGeneratorSpec:
# type: Current supported type is 'simple' and 'normalizedDate'.
type: normalizedDate
# configs: Configs to init SegmentNameGenerator.
configs:
segment.name.prefix: 'airlineStats_batch'
exclude.sequence.id: true
# pinotClusterSpecs: defines the Pinot Cluster Access Point.
pinotClusterSpecs:
- # controllerURI: used to fetch table/schema information and data push.
# E.g. http://localhost:9000
controllerURI: 'http://localhost:9000'
# pushJobSpec: defines segment push job related configuration.
pushJobSpec:
# pushParallelism: push job parallelism, default is 1.
pushParallelism: 2
# pushAttempts: number of attempts for push job, default is 1, which means no retry.
pushAttempts: 2
# pushRetryIntervalMillis: retry wait Ms, default to 1 second.
pushRetryIntervalMillis: 1000export PINOT_VERSION=0.10.0-SNAPSHOT
export PINOT_DISTRIBUTION_DIR=${PINOT_ROOT_DIR}/build/
export HADOOP_CLIENT_OPTS="-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml"
hadoop jar \
${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \
org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand \
-jobSpecFile ${PINOT_DISTRIBUTION_DIR}/examples/batch/airlineStats/hadoopIngestionJobSpec.yamldocker run --rm -ti -e JAVA_OPTS="-Xms8G -Dlog4j2.configurationFile=/opt/pinot/conf/pinot-admin-log4j2.xml -Dplugins.dir=/opt/pinot/plugins" --name pinot-data-ingestion-job apachepinot/pinot:latest LaunchDataIngestionJob -jobSpecFile /path/to/ingestion_job_spec.yaml