Segments for offline tables are constructed outside of Pinot, typically in Hadoop via map-reduce jobs and ingested into Pinot via REST API provided by the Controller. Pinot provides libraries to create Pinot segments out of input files in AVRO, JSON or CSV formats in a hadoop job, and push the constructed segments to the controllers via REST APIs.
When an Offline segment is ingested, the controller looks up the table’s configuration and assigns the segment to the servers that host the table. It may assign multiple servers for each segment depending on the number of replicas configured for that table.
Pinot supports different segment assignment strategies that are optimized for various use cases.
Once segments are assigned, Pinot servers get notified via Helix to “host” the segment. The segments are downloaded from the remote segment store to the local storage, untarred, and memory-mapped.
Once the server has loaded (memory-mapped) the segment, Helix notifies brokers of the availability of these segments. The brokers start to include the new segments for queries. Brokers support different routing strategies depending on the type of table, the segment assignment strategy, and the use case.
Data in offline segments are immutable (Rows cannot be added, deleted, or modified). However, segments may be replaced with modified data.
Starting from release-0.11.0, Pinot supports uploading offline segments to real-time tables. This is useful when user wants to bootstrap a real-time table with some initial data, or add some offline data to a real-time table without changing the data stream. Note that this is different from the setup, and no time boundary is maintained between the offline segments and the real-time segments.
Ingesting Real-time Data
Segments for real-time tables are constructed by Pinot servers with rows ingested from data streams such as Kafka. Rows ingested from streams are made available for query processing as soon as they are ingested, thus enabling applications such as those that need real-time charts on analytics.
In large scale installations, data in streams is typically split across multiple stream partitions. The underlying stream may provide consumer implementations that allow applications to consume data from any subset of partitions, including all partitions (or, just from one partition).
A pinot table can be configured to consume from streams in one of two modes:
LowLevel: This is the preferred mode of consumption. Pinot creates independent partition-level consumers for each partition. Depending on the the configured number of replicas, multiple consumers may be created for each partition, taking care that no two replicas exist on the same server host. Therefore you need to provision at least as many hosts as the number of replicas configured.
HighLevel: Pinot creates one stream-level consumer that consumes from all partitions. Each message consumed could be from any of the partitions of the stream. Depending on the configured number of replicas, multiple stream-level consumers are created, taking care that no two replicas exist on the same server host. Therefore you need to provision exactly as many hosts as the number of replicas configured.
Of course, the underlying stream should support either mode of consumption in order for a Pinot table to use that mode. Kafka has support for both of these modes. See for more information on the support of other data streams in Pinot.
In either mode, Pinot servers store the ingested rows in volatile memory until either one of the following conditions are met:
A certain number of rows are consumed
The consumption has gone on for a certain length of time
(See on how to set these values, or have pinot compute them for you)
Upon reaching either one of these limits, the servers do the following:
Pause consumption
Persist the rows consumed so far into non-volatile storage
Continue consuming new rows into volatile memory again.
The persisted rows form what we call a completed segment (as opposed to a consuming segment that resides in volatile memory).
In LowLevel mode, the completed segments are persisted the into local non-volatile store of pinot server as well as the segment store of the pinot cluster (See ). This allows for easy and automated mechanisms for replacing pinot servers, or expanding capacity, etc. Pinot has that ensure that the completed segment is equivalent across all replicas.
During segment completion, one winner is chosen by the controller from all the replicas as the committer server. The committer server builds the segment and uploads it to the controller. All the other non-committer servers follow one of these two paths:
If the in-memory segment is equivalent to the committed segment, the non-committer server also builds the segment locally and replaces the in-memory segment
If the in-memory segment is non equivalent to the committed segment, the non-committer server downloads the segment from the controller.
For more details on this protocol, refer to .
In HighLevel mode, the servers persist the consumed rows into local store (and not the segment store). Since consumption of rows can be from any partition, it is not possible to guarantee equivalence of segments across replicas.
To query using distributed joins, window functions, and other multi-stage operators in real time, turn on the multi-stage query engine (v2).
To query using distributed joins, window functions, and other multi-stage operators in real time, you must enable the multi-stage query engine (v2). To enable v2, do any of the following:
Programmatically access the multi-stage query engine:
Query
Query outside of the APIs
To learn more about what the multi-stage query engine is, see .
Enable the multi-stage query engine in the Query Console
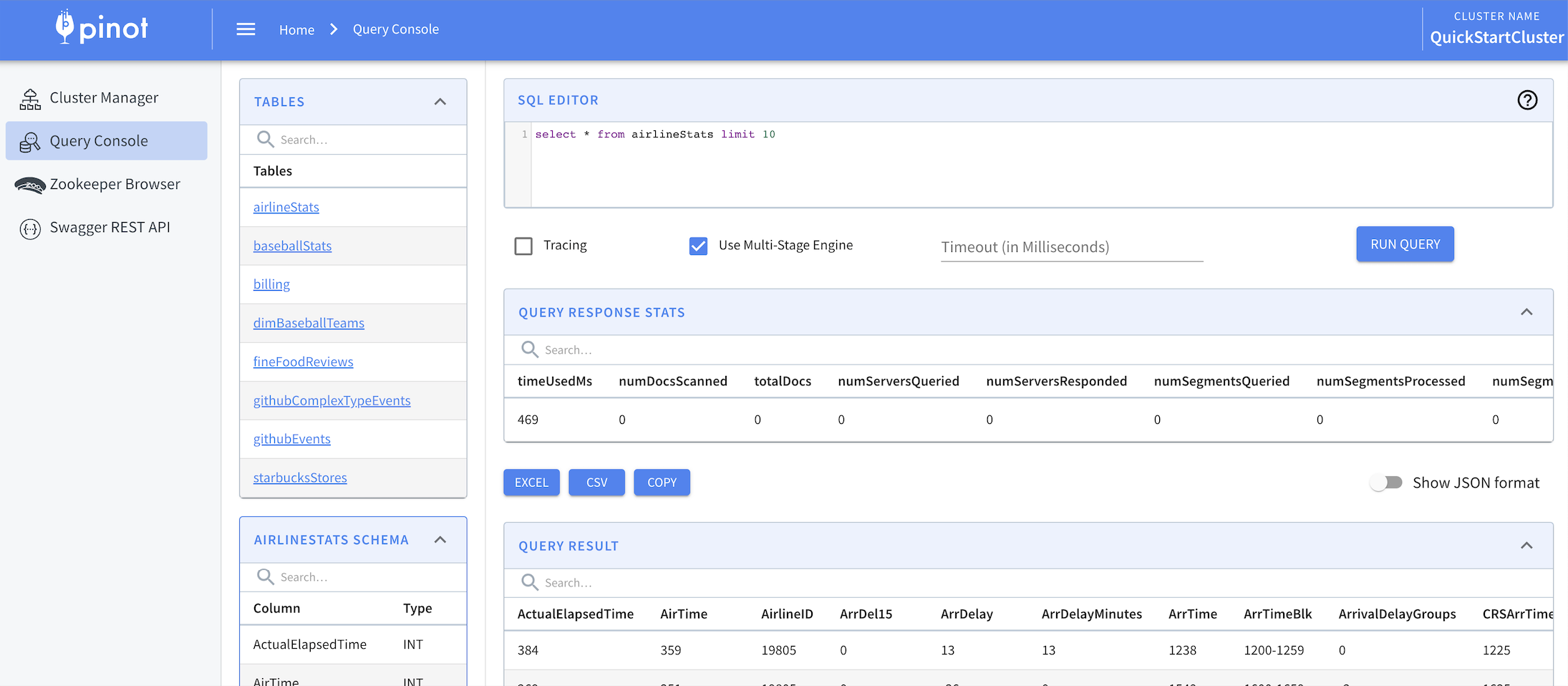
To enable the multi-stage query engine, in the Pinot Query Console, select the Use Multi-Stage Engine check box.
Programmatically access the multi-stage query engine
To query the Pinot multi-stage query engine, use REST APIs or the query option:
Use REST APIs
The Controller admin API and the Broker query API allow optional JSON payload for configuration. For example:
Use the query option
To enable the multi-stage engine via a query outside of the API, add the useMultistageEngine=true option to the top of your query.
For example:
Null value support
Multi-stage engine warning
This document describes null handling for the . At this time, the (v2) does not support null handling. Queries involving null values in a multi-stage environment may return unexpected results.
Null handling is defined in two different parts: at ingestion and at query time.
By default, null handling is disabled (nullHandlingEnabled=false) in the Table index configuration (tableIndexConfig). When null support is disabled, IS NOT NULL evaluates to true, and IS NULL evaluates to false. For example, the predicate in the query below matches all records.
Enable basic null support
To enable basic null support (IS NULL and IS NOT NULL) and generate the null index, in the Table index configuration (tableIndexConfig), set nullHandlingEnabled=true.
When null support is enabled, IS NOT NULL and IS NULL evaluate to true or false according to whether a null is detected.
Important
You MUST SET enableNullHandling=true; before you query. Just having "nullHandlingEnabled: true," set in your table config does not automatically provide enableNullHandling=true when you execute a query. Basic null handling supports IS NOT NULL and IS NULL predicates. Advanced null handling adds SQL compatibility.
Example workarounds to handle null values
If you're not able to generate the null index for your use case, you may filter for null values using a default value specified in your schema or a specific value included in your query.
The following example queries work when the null value is not used in a dataset. Errors may occur if the specified null value is a valid value in the dataset.
Filter for default null value(s) specified in your schema
Specify a default null value (defaultNullValue) in your schema for dimension fields, (dimensionFieldSpecs), metric fields (metricFieldSpecs), and date time fields (dateTimeFieldSpecs).
To filter out the specified default null value, for example, you could write a query like the following:
Filter for a specific value in your query
Filter for a specific value in your query that will not be included in the dataset. For example, to calculate the average age, use -1 to indicate the value of Age is null.
Rewrite the following query:
To cover null values as follows:
Advanced null handling support
Under development to improve performance for advanced null handling.
Pinot provides advanced null handling support similar to standard SQL null handling. Because this feature carries a notable performance impact (even queries without null values), this feature is not enabled by default. For optimal query latency, we recommend enabling basic null support.
Enable advanced null handling
To enable NULL handling, do the following:
To enable null handling during ingestion, in tableIndexConfig, set**nullHandlingEnabled=true**.
To enable null handling for queries, set the**enableNullHandling** query option.
Important
You MUST SET enableNullHandling=true; before you query. Just having "nullHandlingEnabled: true," set in your table config does not automatically provide enableNullHandling=true when you execute a query. Basic null handling supports IS NOT NULL and IS NULL predicates. Advanced null handling adds SQL compatibility.
Ingestion time
To store the null values in a segment, you must enable the nullHandlingEnabled in tableIndexConfig section before ingesting the data.
During real-time or offline ingestion, Pinot checks to see if null handling is enabled, and stores null values in the segment itself. Data ingested when null handling is disabled does not store null values, and should be ingested again.
The nullHandlingEnabled configuration affects all columns in a Pinot table.
Column-level null support is under development.
Query time
By default, null usage in the predicate is disabled.
For handling nulls in aggregation functions, explicitly enable the null support by setting the query option enableNullHandling to true. Configure this option in one of the following ways:
Set enableNullHandling=true at the beginning of the query.
If using JDBC, set the connection option enableNullHandling=true (either in the URL or as a property).
When this option is enabled, the Pinot query engine uses a different execution path that checks null predicates. Therefore, some indexes may not be usable, and the query is significantly more expensive. This is the main reason why null handling is not enabled by default.
If the query includes a IS NULL or IS NOT NULL predicate, Pinot fetches the NULL value vector for the corresponding column within FilterPlanNode and retrieves the corresponding bitmap that represents all document IDs containing NULL values for that column. This bitmap is then used to create a BitmapBasedFilterOperator to do the filtering operation.
We are continuously improving the v2 multi-stage query engine. A few limitations to call out:
Support for multi-value columns is limited
Support for multi-value columns is limited to projections, and predicates must use the arrayToMv function. For example, to successfully run the following query:
You must include arrayToMv in the query as follows:
Schema and other prefixes are not supported
Schema and other prefixes are not supported in queries. For example, the following queries are notsupported:
Queries without prefixes are supported:
Modifying query behavior based on the cluster config is not supported
Modifying query behavior based on the cluster configuration is not supported. distinctcounthll, distinctcounthllmv, distinctcountrawhll, and `distinctcountrawhllmv` use a different default value of log2mParam in the multi-stage v2 engine. In v2, this value can no longer be configured. Therefore, the following query may produce different results in v1 and v2 engine:
To ensure v2 returns the same result, specify the log2mParam value in your query:
Ambiguous reference to a projected column in statement clauses
If a column is repeated more than once in SELECT statement, that column requires disambiguate aliasing. For example, in the following query, the reference to colA is ambiguous whether it's to the first or second projected colA:
The solution is to rewrite the query either use aliasing:
Or use index-based referencing:
Tightened restriction on function naming
Pinot single-stage query engine automatically removes the underscore _ character from function names. So co_u_n_t()is equivalent to count().
In v2, function naming restrictions were tightened, so the underscore(_) character is only allowed to separate word boundaries in a function name. Also camel case is supported in function names. For example, the following function names are allowed:
Tightened restriction on function signature and type matching
Pinot single-stage query engine automatically do implicit type casts in many of the situations, for example when running the following:
it will automatically convert both values to long datatypes before comparison. This behavior however could cause issues and thus it is not so widely applied in the v2 engine. In the v2 engine, a stricter datatype conformance is enforced. the example above should be explicitly written as:
Default names for projections with function calls
Default names for projections with function calls are different between v1 and v2.
For example, in v1, the following query:
Returns the following result:
In v2, the following function:
Returns the following result:
Table names and column names are case sensitive
In v2, table and column names and are case sensitive. In v1 they were not. For example, the following two queries are not equivalent in v2:
select * from myTable
select * from mytable
Note: Function names are not case sensitive in v2 or v1.
Arbitrary number of arguments isn't supported
An arbitrary number of arguments is no longer supported in v2. For example, in v1, the following query worked:
In v2, this query must be rewritten as follows:
NULL function support
IS NULL and IS NOT NULL functions do not work correctly in v2.
Using the COUNT function on a NULL column does not work correctly in v2.
Custom transform function support
The histogram function is not supported in v2.
The timeConvert function is not supported in v2, see dateTimeConvert for more details.
Custom aggregate function support
aggregate function that requires literal input (such as percentile, firstWithTime) might result in a non-compilable query plan when used in v2.
Troubleshoot errors
Troubleshoot semantic/runtime errors and timeout errors.
Semantic/runtime errors
Try downloading the latest docker image or building from the latest master commit.
We continuously push bug fixes for the multi-stage engine so bugs you encountered might have already been fixed in the latest master build.
Try rewriting your query.
Timeout errors
Try reducing the size of the table(s) used.
Add higher selectivity filters to the tables.
Try executing part of the subquery or a simplified version of the query first.
Ingestion Aggregations
Many data analytics use-cases only need aggregated data. For example, data used in charts can be aggregated down to one row per time bucket per dimension combination.
Doing this results in much less storage and better query performance. Configuring this for a table is done via the Aggregation Config in the .
Aggregation Config
The aggregation config controls the aggregations that happen during real-time data ingestion. Offline aggregations must be handled separately.
select count(*) from my_table where column IS NOT NULL
select count(*) from my_table where column <> 'default_null_value'
select avg(Age) from my_table
select avg(Age) from my_table WHERE Age <> -1
curl -X POST http://localhost:9000/sql -d
'
{
"sql": "select * from baseballStats limit 10",
"trace": false,
"queryOptions": "useMultistageEngine=true"
}
'
curl -X POST http://localhost:8000/query/sql -d '
{
"sql": "select * from baseballStats limit 10",
"trace": false,
"queryOptions": "useMultistageEngine=true"
}
'
SET useMultistageEngine=true; -- indicator to enable the multi-stage engine.
SELECT * from baseballStats limit 10
The dateTimeConvertWindowHop function is not supported in v2.
Array & Map-related functions are not supported in v2.
Some functions previously supported in the single-stage query engine (v1) may have a new way to express in the multi-stage engine (v2). Check and see if you are using any non-standard SQL functions or semantics.
This helps to determine the selectivity and scale of the query being executed.
Try adding more servers.
The new multi-stage engine runs distributed across the entire cluster, so adding more servers to partitioned queries such as GROUP BY aggregates, and equality JOINs help speed up the query runtime.
-- example 1: used in GROUP-BY
SELECT count(*), RandomAirports FROM airlineStats
GROUP BY RandomAirports
-- example 2: used in PREDICATE
SELECT * FROM airlineStats WHERE RandomAirports IN ('SFO', 'JFK')
-- example 3: used in ORDER-BY
SELECT count(*), RandomAirports FROM airlineStats
GROUP BY RandomAirports
ORDER BY RandomAirports DESC
-- example 1: used in GROUP-BY
SELECT count(*), arrayToMv(RandomAirports) FROM airlineStats
GROUP BY arrayToMv(RandomAirports)
-- example 2: used in PREDICATE
SELECT * FROM airlineStats WHERE arrayToMv(RandomAirports) IN ('SFO', 'JFK')
-- example 3: used in ORDER-BY
SELECT count(*), arrayToMV(RandomAirports) FROM airlineStats
GROUP BY arrayToMV(RandomAirports)
ORDER BY arrayToMV(RandomAirports) DESC
SELECT* from default.myTable;
SELECT * from schemaName.myTable;
SELECT * from myTable;
select distinctcounthll(col) from myTable
select distinctcounthll(col, 8) from myTable
SELECT colA, colA, COUNT(*)
FROM myTable GROUP BY colA ORDER BY colA
SELECT colA AS tmpA, colA as tmpB, COUNT(*)
FROM myTable GROUP BY tmpA, tmpB ORDER BY tmpA
SELECT colA, colA, COUNT(*)
FROM myTable GROUP BY 1, 2 ORDER BY 1
is_distinct_from(...)
isDistinctFrom(...)
timestampCol >= longCol
CAST(timestampCol AS BITINT) >= longCol
SELECT count(*) from mytable
"columnNames": [
"EXPR$0"
],
SELECT count(*) from mytable
"columnNames": [
"count(*)"
],
select add(1,2,3,4,5) from table
select add(1, add(2,add(3, add(4,5)))) from table
Below is a description of the config, which is defined in the ingestion config of the table config.
Requirements
The following are required for ingestion aggregation to work:
Ingestion aggregation config is effective only for real-time tables. (There is no ingestion time aggregation support for offline tables. We need use Merge/Rollup Task or pre-process aggregations in the offline data flow using batch processing engines like Spark/MapReduce).
aggregatedFieldName must be in the Pinot schema and originalFieldName must not exist in Pinot schema
Example Scenario
Here is an example of sales data, where only the daily sales aggregates per product are needed.
Example Input Data
Schema
Note that the schema only reflects the final table structure.
Table Config
From the below aggregation config example, note that price exists in the input data while total_sales exists in the Pinot Schema.
Example Final Table
product_name
sales_count
total_sales
daysSinceEpoch
car
2
2800.00
18193
truck
1
2200.00
18193
truck
Allowed Aggregation Functions
function name
notes
MAX
MIN
SUM
COUNT
Specify as COUNT(*)
DISTINCTCOUNTHLL
Not available yet, but coming soon
Frequently Asked Questions
Why not use a Startree?
Startrees can only be added to real-time segments after the segments has sealed, and creating startrees is CPU-intensive. Ingestion Aggregation works for consuming segments and uses no additional CPU.
Startrees take additional memory to store, while ingestion aggregation stores less data than the original dataset.
When to not use ingestion aggregation?
If the original rows in non-aggregated form are needed, then ingestion-aggregation cannot be used.
I already use the aggregateMetrics setting?
The aggregateMetrics works the same as Ingestion Aggregation, but only allows for the SUM function.
The current changes are backward compatible, so no need to change your table config unless you need a different aggregation function.
Does this config work for offline data?
Ingestion Aggregation only works for real-time ingestion. For offline data, the offline process needs to generate the aggregates separately.
Why do all metrics need to be aggregated?
If a metric isn't aggregated then it will result in more than one row per unique set of dimensions.
Raw source data often needs to undergo some transformations before it is pushed to Pinot.
Transformations include extracting records from nested objects, applying simple transform functions on certain columns, filtering out unwanted columns, as well as more advanced operations like joining between datasets.
A preprocessing job is usually needed to perform these operations. In streaming data sources you might write a Samza job and create an intermediate topic to store the transformed data.
For simple transformations, this can result in inconsistencies in the batch/stream data source and increase maintenance and operator overhead.
To make things easier, Pinot supports transformations that can be applied via the .
A transformation function cannot mix Groovy and built-in functions - you can only use one type of function at a time.
Groovy functions
Groovy functions can be defined using the syntax:
Any valid Groovy expression can be used.
⚠️Enabling Groovy
Allowing execuatable Groovy in ingestion transformation can be a security vulnerability. If you would like to enable Groovy for ingestion, you can set the following controller config.
controller.disable.ingestion.groovy=false
If not set, Groovy for ingestion transformation is disabled by default.
Inbuilt Pinot functions
All the functions defined in this directory annotated with @ScalarFunction (e.g. toEpochSeconds) are supported ingestion transformation functions.
Below are some commonly used built-in Pinot functions for ingestion transformations.
DateTime functions
These functions enable time transformations.
toEpochXXX
Converts from epoch milliseconds to a higher granularity.
Function name
Description
toEpochSeconds
Converts epoch millis to epoch seconds.
Usage:"toEpochSeconds(millis)"
toEpochMinutes
Converts epoch millis to epoch minutes
Usage: "toEpochMinutes(millis)"
toEpochHours
Converts epoch millis to epoch hours
Usage: "toEpochHours(millis)"
toEpochDays
Converts epoch millis to epoch days
Usage: "toEpochDays(millis)"
toEpochXXXRounded
Converts from epoch milliseconds to another granularity, rounding to the nearest rounding bucket. For example, 1588469352000 (2020-05-01 42:29:12) is 26474489 minutesSinceEpoch. `toEpochMinutesRounded(1588469352000) = 26474480 (2020-05-01 42:20:00)
Function Name
Description
toEpochSecondsRounded
Converts epoch millis to epoch seconds, rounding to nearest rounding bucket"toEpochSecondsRounded(millis, 30)"
toEpochMinutesRounded
Converts epoch millis to epoch seconds, rounding to nearest rounding bucket"toEpochMinutesRounded(millis, 10)"
toEpochHoursRounded
Converts epoch millis to epoch seconds, rounding to nearest rounding bucket"toEpochHoursRounded(millis, 6)"
toEpochDaysRounded
Converts epoch millis to epoch seconds, rounding to nearest rounding bucket"toEpochDaysRounded(millis, 7)"
fromEpochXXX
Converts from an epoch granularity to milliseconds.
Function Name
Description
fromEpochSeconds
Converts from epoch seconds to milliseconds
"fromEpochSeconds(secondsSinceEpoch)"
fromEpochMinutes
Converts from epoch minutes to milliseconds
"fromEpochMinutes(minutesSinceEpoch)"
fromEpochHours
Converts from epoch hours to milliseconds
"fromEpochHours(hoursSinceEpoch)"
fromEpochDays
Converts from epoch days to milliseconds
"fromEpochDays(daysSinceEpoch)"
Simple date format
Converts simple date format strings to milliseconds and vice-a-versa, as per the provided pattern string.
Function name
Description
Converts from milliseconds to a formatted date time string, as per the provided pattern
"toDateTime(millis, 'yyyy-MM-dd')"
Converts a formatted date time string to milliseconds, as per the provided pattern
Converts a JSON/AVRO complex object to a string. This json map can then be queried using function.
"json_format(jsonMapField)"
Types of transformation
Filtering
Records can be filtered as they are being ingested. A filter function can be specified in the filterConfigs in the ingestionConfigs of the table config.
If the expression evaluates to true, the record will be filtered out. The expressions can use any of the transform functions described in the previous section.
Consider a table that has a column timestamp. If you want to filter out records that are older than timestamp 1589007600000, you could apply the following function:
Consider a table that has a string column campaign and a multi-value column double column prices. If you want to filter out records where campaign = 'X' or 'Y' and sum of all elements in prices is less than 100, you could apply the following function:
Filter config also supports SQL-like expression of built-in scalar functions for filtering records (starting v 0.11.0+). Example:
Column Transformation
Transform functions can be defined on columns in the ingestion config of the table config.
For example, imagine that our source data contains the prices and timestamp fields. We want to extract the maximum price and store that in the maxPrices field and convert the timestamp into the number of hours since the epoch and store it in the hoursSinceEpoch field. You can do this by applying the following transformation:
Below are some examples of commonly used functions.
String concatenation
Concat firstName and lastName to get fullName
Find an element in an array
Find max value in array bids
Time transformation
Convert timestamp from MILLISECONDS to HOURS
Column name change
Change name of the column from user_id to userId
Extract value from a column containing space
Pinot doesn't support columns that have spaces, so if a source data column has a space, we'll need to store that value in a column with a supported name. To extract the value from first Name into the column firstName, run the following:
Ternary operation
If eventType is IMPRESSION set impression to 1. Similar for CLICK.
AVRO Map
Store an AVRO Map in Pinot as two multi-value columns. Sort the keys, to maintain the mapping.
1) The keys of the map as map_keys
2) The values of the map as map_values
Chaining transformations
Transformations can be chained. This means that you can use a field created by a transformation in another transformation function.
For example, we might have the following JSON document in the data field of our source data:
We can apply one transformation to extract the userId and then another one to pull out the numerical part of the identifier:
Flattening
There are 2 kinds of flattening:
One record into many
This is not natively supported as of yet. You can write a custom Decoder/RecordReader if you want to use this. Once the Decoder generates the multiple GenericRows from the provided input record, a List<GenericRow> should be set into the destination GenericRow, with the key $MULTIPLE_RECORDS_KEY$. The segment generation drivers will treat this as a special case and handle the multiple records case.
Set up Pinot by starting each component individually
Start Pinot Components using docker
Prerequisites
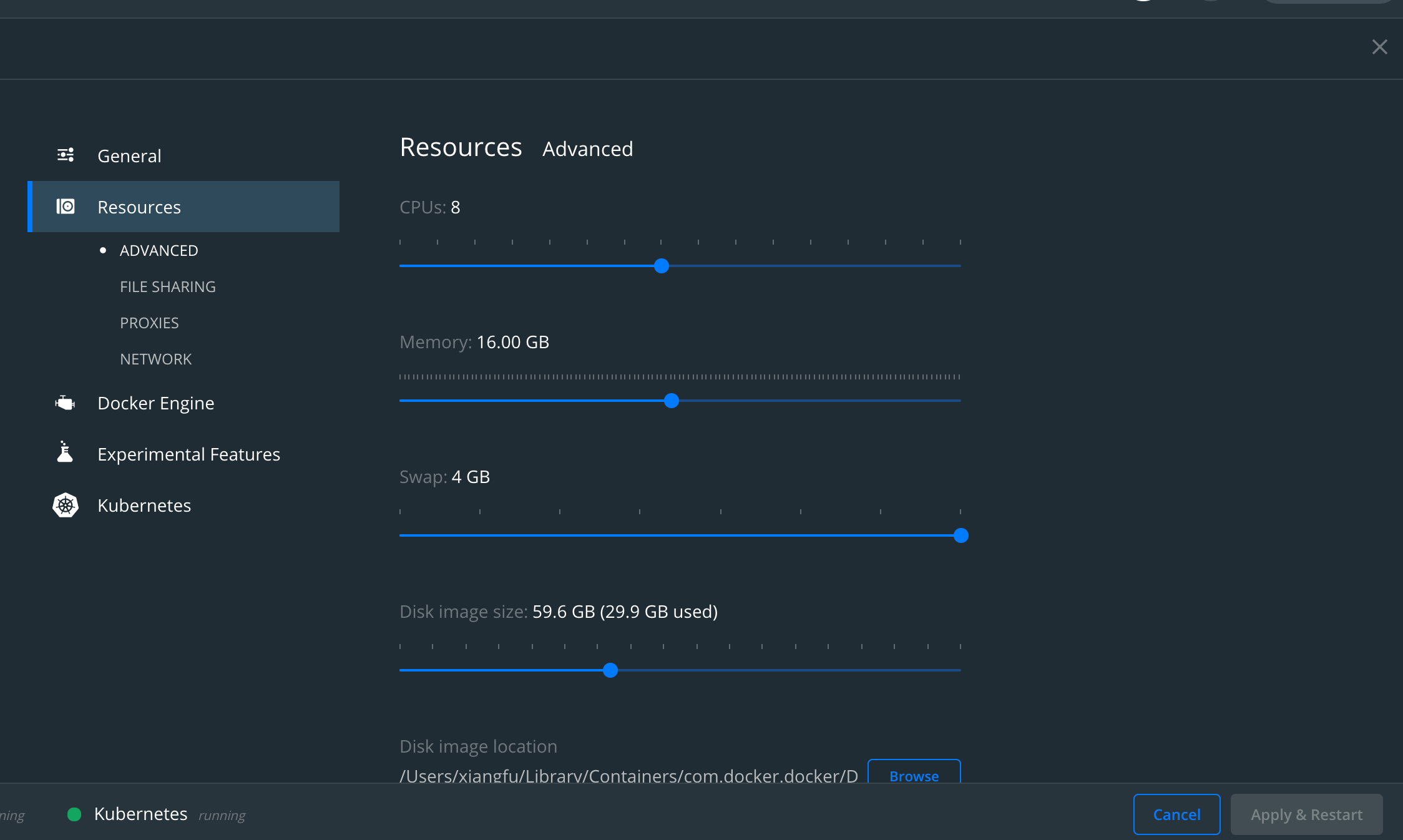
If running locally, ensure your docker cluster has enough resources, below is a sample config.
Pull Docker image
You can try out pre-built Pinot all-in-one Docker image.
(Optional) You can also follow the instructions to build your own images.
0. Create a network
Create an isolated bridge network in Docker.
1. Start Zookeeper
Start Zookeeper in daemon.
Start to browse Zookeeper data at .
2. Start Pinot Controller
Start Pinot Controller in daemon and connect to Zookeeper.
3. Start Pinot Broker
Start Pinot Broker in daemon and connect to Zookeeper.
4. Start Pinot Server
Start Pinot Server in daemon and connect to Zookeeper.
Now all Pinot related components are started as an empty cluster.
You can run below command to check container status.
Sample Console Output
Download Pinot Distribution from
Start Pinot components via launcher scripts
Start Zookeeper
Start Pinot Controller
See for more details .
Start Pinot Broker
Start Pinot Using Config Files
Often times we need to customized the setup of Pinot components. Hence user can compile a config file and use it to start Pinot components.
Below are the examples config files and sample command to start Pinot.
Pinot Controller
Below is a sample pinot-controller.conf used in HelmChart setup.
In order to run Pinot Controller, the command is:
Configure Controller
Below are some configurations you can set in Pinot Controller. You can head over to for complete list of available configs.
Config Name
Description
Default Value
Pinot Broker
Below is a sample pinot-broker.conf used in HelmChart setup.
In order to run Pinot Broker, the command is:
Configure Broker
Below are some configurations you can set in Pinot Broker. You can head over to for complete list of available configs.
Config Name
Description
Default Value
Pinot Server
Below is a sample pinot-server.conf used in HelmChart setup.
In order to run Pinot Server, the command is:
Configure Server
Below are some outstanding configurations you can set in Pinot Server. You can head over to for complete list of available configs.
Config Name
Description
Default Value
Create and Configure table
A TABLE in regular database world is represented as <TABLE>_OFFLINE and/or <TABLE>_REALTIME in Pinot depending on the ingestion mode (batch, real-time, hybrid)
See for all possible batch/streaming tables.
Batch Table Creation
See for table configuration details and how to customize it.
Sample Console Output
Automatically add an inverted index to your batch table
By default, the inverted index type is the only type of index that isn't created automatically during segment generation. Instead, they are generated when the segments are loaded on the server. But, waiting to build indexes until load time increases the startup time and takes up resources with every new segment push, which increases the time for other operations such as rebalance.
To automatically create an inverted index during segment generation, add an entry to your in the table configuration file.
This setting works with .
When set to true, Pinot creates an inverted index for the columns that you specify in the invertedIndexColumns list in the table configuration.
This setting is false by default.
Set createInvertedIndexDuringSegmentGeneration to true in your table config, as follows:
When you update this setting in your table configuration, you must to apply the inverted index to all existing segments.
Streaming Table Creation
See for table configuration details and how to customize it.
Start Kafka
Create a Kafka Topic
Create a Streaming table
Sample output
Start Kafka-Zookeeper
Start Kafka
Use sortedColumn with streaming tables
For tables, you can use a sorted index with sortedColumn to sort data when generating segments as the segment is created. See for more information.
A sorted forward index can be used as an inverted index with better performance, but with the limitation that the search is only applied to one column per table. See to learn more.
Load Data
Now that the table is configured, let's load some data. Data can be loaded in batch mode or streaming mode. See page for details. Loading data involves generating pinot segments from raw data and pushing them to the pinot cluster.
Load Data in Batch
User can always generate and push segments to Pinot via standalone scripts or using frameworks such as Hadoop or Spark. See this for more details on setting up Data Ingestion Jobs.
Below example goes with the standalone mode.
Sample Console Output
JobSpec yaml file has all the information regarding data format, input data location and pinot cluster coordinates. Note that this assumes that the controller is RUNNING to fetch the table config and schema. If not, you will have to configure the spec to point at their location. See for more details.
Load Data in Streaming
Kafka
Run below command to stream JSON data into Kafka topic: flights-realtime
Run below command to stream JSON data into Kafka topic: flights-realtime
Start Pinot Controller
Pinot Controller Port
9000
controller.vip.host
The VIP hostname used to set the download URL for segments
${controller.host}
controller.vip.port
The VIP port used to set the download URL for segments
${controller.port}
controller.data.dir
Directory to host segment data
${java.io.tmpdir}/PinotController
controller.zk.str
Zookeeper URL
localhost:2181
cluster.tenant.isolation.enable
Enable Tenant Isolation, default is single tenant cluster
true
Timeout for Broker Query in Milliseconds
10000
pinot.broker.enable.query.limit.override
Configuration to enable Query LIMIT Override to protect Pinot Broker and Server from fetch too many records back.
false
pinot.broker.query.response.limit
When config pinot.broker.enable.query.limit.override is enabled, reset limit for selection query if it exceeds this value.
2147483647
pinot.broker.startup.minResourcePercent
Configuration to consider the broker ServiceStatus as being STARTED if the percent of resources (tables) that are ONLINE for this this broker has crossed the threshold percentage of the total number of tables that it is expected to serve
100.0
Port for Pinot Server Admin UI
8097
pinot.server.instance.dataDir
Directory to hold all the data
${java.io.tmpDir}/PinotServer/index
pinot.server.instance.segmentTarDir
Directory to hold temporary segments downloaded from Controller or Deep Store
${java.io.tmpDir}/PinotServer/segmentTar
pinot.server.query.executor.timeout
Timeout for Server to process Query in Milliseconds
15000
Create stream table
controller.helix.cluster.name
Pinot Cluster name
PinotCluster
controller.host
Pinot Controller Host
Required if config pinot.set.instance.id.to.hostname is false.
pinot.set.instance.id.to.hostname
When enabled, use server hostname to infer controller.host
false
instanceId
Unique id to register Pinot Broker in the cluster.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9e80c3fcd29b apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 18 seconds ago Up 17 seconds 8096-8099/tcp, 9000/tcp pinot-server
f4c42a5865c7 apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 21 seconds ago Up 21 seconds 8096-8099/tcp, 9000/tcp pinot-broker
a413b0013806 apachepinot/pinot:0.3.0-SNAPSHOT "./bin/pinot-admin.s…" 26 seconds ago Up 25 seconds 8096-8099/tcp, 0.0.0.0:9000->9000/tcp pinot-controller
9d3b9c4d454b zookeeper:3.5.6 "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp pinot-zookeeper
$ export PINOT_VERSION=0.10.0
$ tar -xvf apache-pinot-${PINOT_VERSION}-bin.tar.gz
$ cd apache-pinot-${PINOT_VERSION}-bin
$ ls
DISCLAIMER LICENSE NOTICE bin conf lib licenses query_console sample_data
$ PINOT_INSTALL_DIR=`pwd`
cd apache-pinot-${PINOT_VERSION}-bin
bin/pinot-admin.sh StartZookeeper