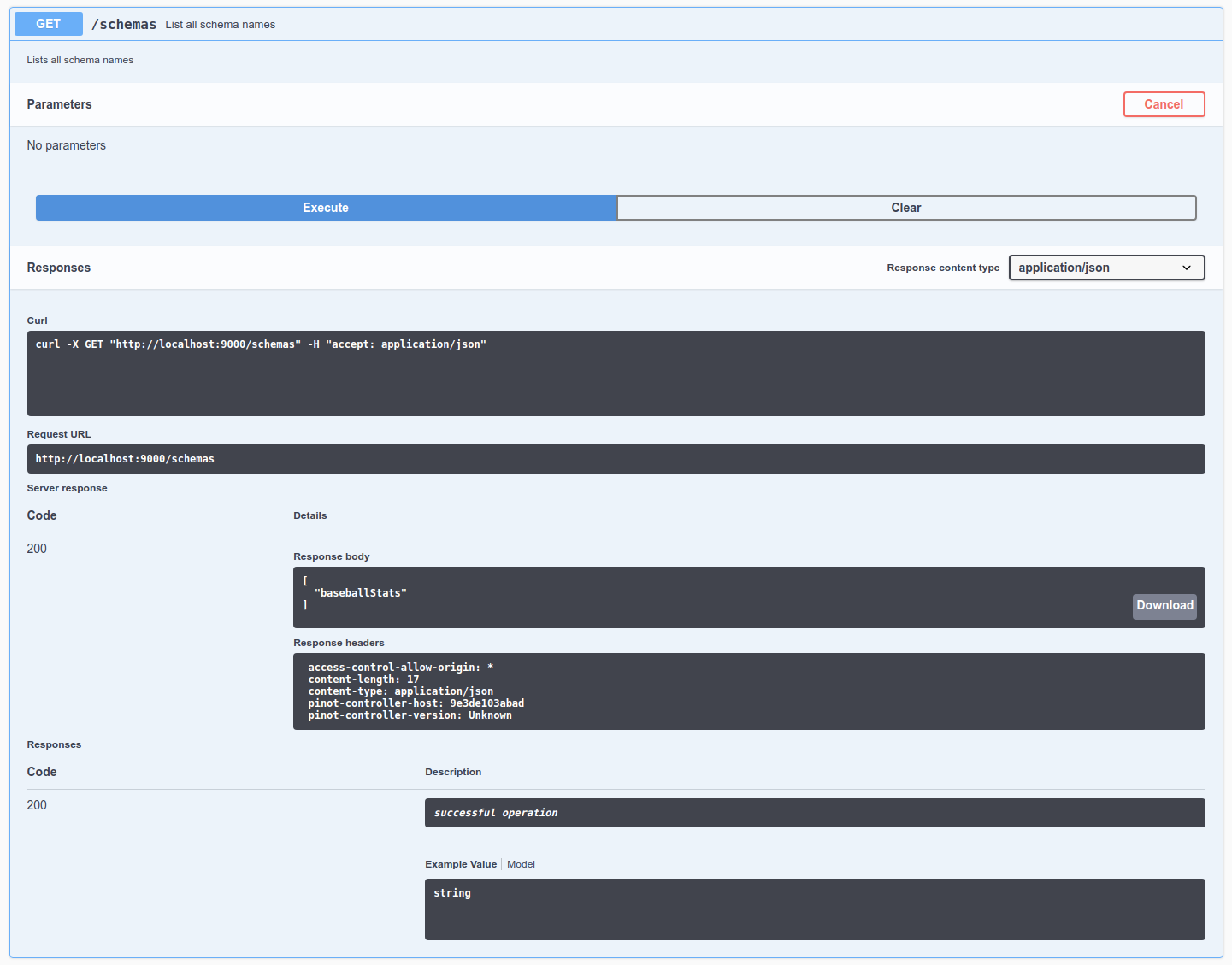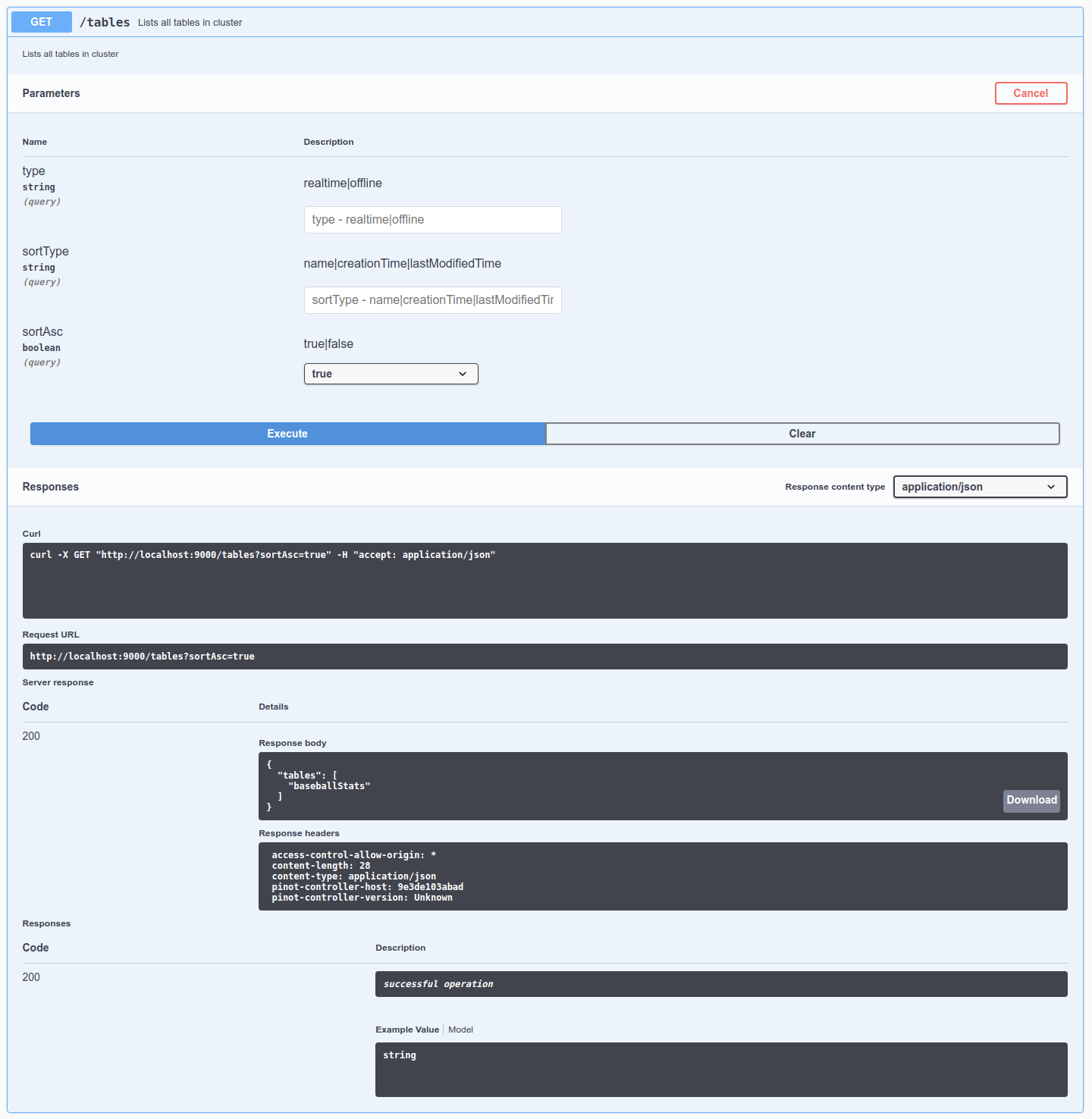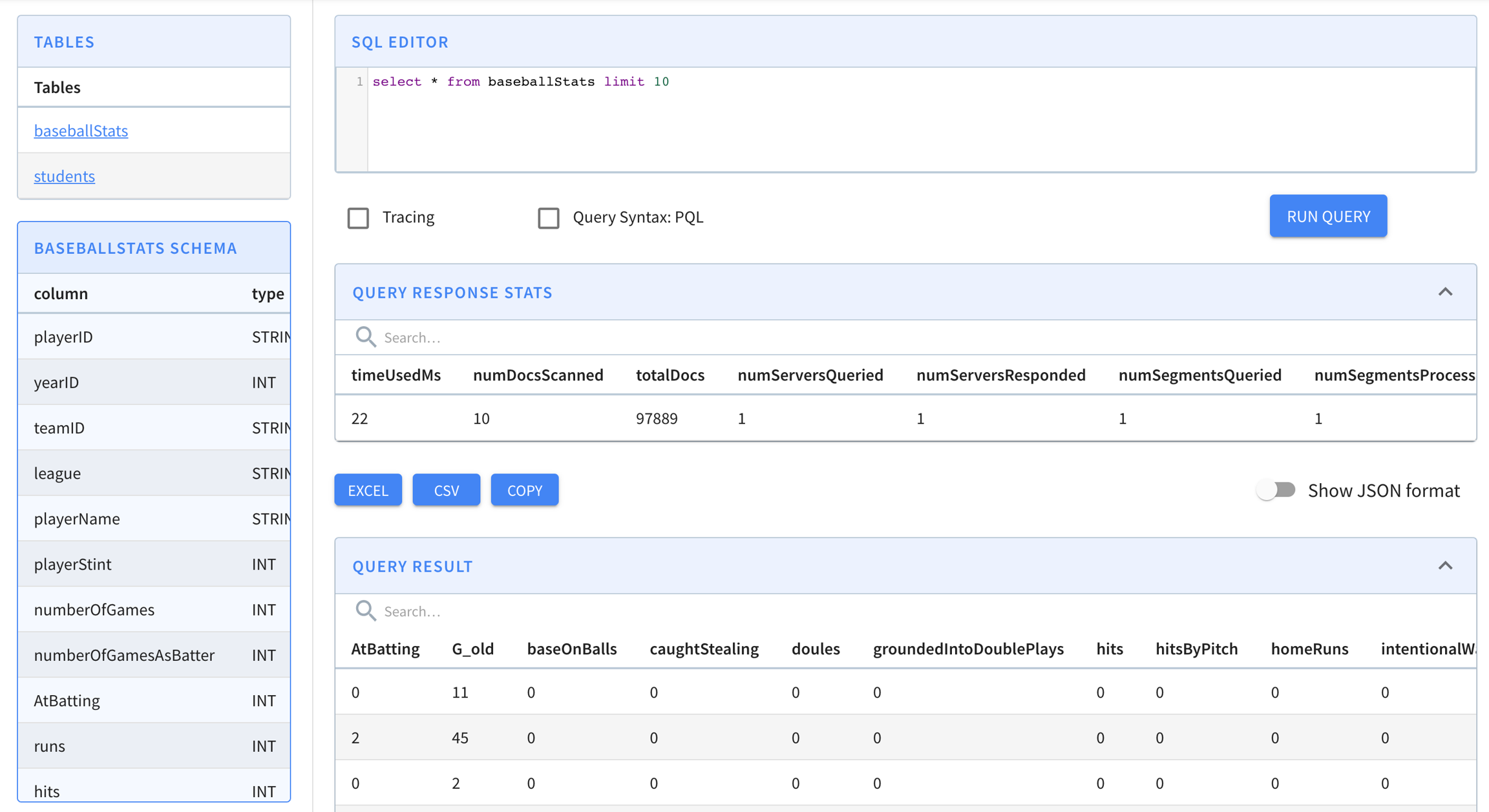
$ curl -H "Content-Type: application/json" -X POST \
-d '{"sql":"select foo, count(*) from myTable group by foo limit 100"}' \
http://localhost:8099/query/sql$ curl -k -H "Content-Type: application/json" -X POST \
-d '{"sql":"select foo, count(*) from myTable group by foo limit 100"}' \
https://localhost:8099/query/sql$ curl -H "Content-Type: application/json" -X POST \
-d '{"sql":"select foo, count(*) from myTable where foo='"'"'abc'"'"' limit 100"}' \
http://localhost:8099/query/sql$ curl -H "Content-Type: application/json" -X POST \
-
$ curl -k -H "Content-Type: application/json" -X POST \
$ curl -H "Content-Type: application/json" -X POST \
-
cd incubator-pinot/pinot-tools/target/pinot-tools-pkg
bin/pinot-admin.sh PostQuery \
-queryType sql \
-brokerPort 8000 \
-query "select count(*) from baseballStats"
2020/03/04 12:46:33.459 INFO [PostQueryCommand] [main] Executing command: PostQuery -brokerHost localhost -brokerPort 8000 -queryType sql -query select count(*) from baseballStats
2020/03/04 12:46:33.854 INFO [PostQueryCommand] [main] Result: {"resultTable":{"dataSchema":{"columnDataTypes":["LONG"],"columnNames":["count(*)"]},"rows":[[97889]]},"exceptions":[],"numServersQueried":1,"numServersResponded":1,"numSegmentsQueried":1,"numSegmentsProcessed":1,"numSegmentsMatched":1,"numConsumingSegmentsQueried":0,"numDocsScanned":97889,"numEntriesScannedInFilter":0,"numEntriesScannedPostFilter":0,"numGroupsLimitReached":false,"totalDocs":97889,"timeUsedMs":185,"segmentStatistics":[],"traceInfo":{},"minConsumingFreshnessTimeMs":0}curl -X GET "http://localhost:9000/cluster/configs" -H "accept: application/json"{
"allowParticipantAutoJoin": "true",
"enable.case.insensitive": "false",
"pinot.broker.enable.query.limit.override": "false",
"default.hyperloglog.log2m": "8"
}curl -X POST "http://localhost:9000/cluster/configs"
-H "accept: application/json"
-H "Content-Type: application/json"
-d "{ \"pinot.helix.instance.state.maxStateTransitions\" : \"20\", \"custom.cluster.prop\": \"foo\"}"{
"status": "Updated cluster config."
}curl -X DELETE "http://localhost:9000/cluster/configs/custom.cluster.prop" {
"status": "Deleted cluster config: custom.cluster.prop"
}curl -X GET "http://localhost:9000/cluster/info" -H "accept: application/json"{
"clusterName": "QuickStartCluster"
}curl -X GET "http://localhost:9000/health" -H "accept: text/plain"OKcurl -X GET "http://localhost:9000/leader/tables" -H "accept: application/json"{
"leadControllerEntryMap": {
"leadControllerResource_0": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_1": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_2": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_3": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_4": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_5": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_6": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_7": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"baseballStats_OFFLINE"
]
},
"leadControllerResource_8": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"dimBaseballTeams_OFFLINE",
"starbucksStores_OFFLINE"
]
},
"leadControllerResource_9": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"billing_OFFLINE"
]
},
"leadControllerResource_10": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_11": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_12": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_13": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"githubComplexTypeEvents_OFFLINE"
]
},
"leadControllerResource_14": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_15": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"githubEvents_OFFLINE"
]
},
"leadControllerResource_16": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_17": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_18": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_19": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"airlineStats_OFFLINE"
]
},
"leadControllerResource_20": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_21": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_22": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
},
"leadControllerResource_23": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": []
}
},
"leadControllerResourceEnabled": true
}curl -X GET "http://localhost:9000/leader/tables/baseballStats" -H "accept: application/json"{
"leadControllerEntryMap": {
"leadControllerResource_7": {
"leadControllerId": "Controller_192.168.1.24_9000",
"tableNames": [
"baseballStats"
]
}
},
"leadControllerResourceEnabled": true
}curl -X GET "http://localhost:9000/debug/tables/baseballStats?type=OFFLINE&verbosity=0" -H "accept: application/json"[
{
"tableName": "baseballStats_OFFLINE",
"numSegments": 1,
"numServers": 1,
"numBrokers": 1,
"segmentDebugInfos": [],
"serverDebugInfos": [],
"brokerDebugInfos": [],
"tableSize": {
"reportedSize": "3 MB",
"estimatedSize": "3 MB"
},
"ingestionStatus": {
"ingestionState": "HEALTHY",
"errorMessage": ""
}
}
]{
"schemaName": "baseballStats",
"dimensionFieldSpecs": [
{
"name": "playerID",
"dataType": "STRING"
},
{
"name": "yearID",
"dataType": "INT"
},
{
"name": "teamID",
"dataType": "STRING"
},
{
"name": "league",
"dataType": "STRING"
},
{
"name": "playerName",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "playerStint",
"dataType": "INT"
},
{
"name": "numberOfGames",
"dataType": "INT"
},
{
"name": "numberOfGamesAsBatter",
"dataType": "INT"
},
{
"name": "AtBatting",
"dataType": "INT"
},
{
"name": "runs",
"dataType": "INT"
},
{
"name": "hits",
"dataType": "INT"
},
{
"name": "doules",
"dataType": "INT"
},
{
"name": "tripples",
"dataType": "INT"
},
{
"name": "homeRuns",
"dataType": "INT"
},
{
"name": "runsBattedIn",
"dataType": "INT"
},
{
"name": "stolenBases",
"dataType": "INT"
},
{
"name": "caughtStealing",
"dataType": "INT"
},
{
"name": "baseOnBalls",
"dataType": "INT"
},
{
"name": "strikeouts",
"dataType": "INT"
},
{
"name": "intentionalWalks",
"dataType": "INT"
},
{
"name": "hitsByPitch",
"dataType": "INT"
},
{
"name": "sacrificeHits",
"dataType": "INT"
},
{
"name": "sacrificeFlies",
"dataType": "INT"
},
{
"name": "groundedIntoDoublePlays",
"dataType": "INT"
},
{
"name": "G_old",
"dataType": "INT"
}
]
}
$ curl -X POST \
-d '{"sql":"SELECT SUM(moo), MAX(bar), COUNT(*) FROM myTable"}' \
localhost:8099/query/sql -H "Content-Type: application/json"
{
"exceptions": [],
"minConsumingFreshnessTimeMs": 0,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 6,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 12,
"numGroupsLimitReached": false,
"numSegmentsMatched": 2,
"numSegmentsProcessed": 2,
"numSegmentsQueried": 2,
"numServersQueried": 1,
"numServersResponded": 1,
"resultTable": {
"dataSchema": {
"columnDataTypes": [
"DOUBLE",
"DOUBLE",
"LONG"
],
"columnNames": [
"sum(moo)",
"max(bar)",
"count(*)"
]
},
"rows": [
[
62335,
2019.0,
6
]
]
},
"segmentStatistics": [],
"timeUsedMs": 87,
"totalDocs": 6,
"traceInfo": {}
}$ curl -X POST \
-d '{"sql":"SELECT SUM(moo), MAX(bar) FROM myTable GROUP BY foo ORDER BY foo"}' \
localhost:8099/query/sql -H "Content-Type: application/json"
{
"exceptions": [],
"minConsumingFreshnessTimeMs": 0,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 6,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 18,
"numGroupsLimitReached": false,
"numSegmentsMatched": 2,
"numSegmentsProcessed": 2,
"numSegmentsQueried": 2,
"numServersQueried": 1,
"numServersResponded": 1,
"resultTable": {
"dataSchema": {
"columnDataTypes": [
"STRING",
"DOUBLE",
"DOUBLE"
],
"columnNames": [
"foo",
"sum(moo)",
"max(bar)"
]
},
"rows": [
[
"abc",
560.0,
2008.0
],
[
"pqr",
21760.0,
2010.0
],
[
"xyz",
40015.0,
2019.0
]
]
},
"segmentStatistics": [],
"timeUsedMs": 15,
"totalDocs": 6,
"traceInfo": {}
}curl -X POST \
-d '{"pql":"select * from flights limit 3"}' \
http://localhost:8099/query
{
"selectionResults":{
"columns":[
"Cancelled",
"Carrier",
"DaysSinceEpoch",
"Delayed",
"Dest",
"DivAirports",
"Diverted",
"Month",
"Origin",
"Year"
],
"results":[
[
"0",
"AA",
"16130",
"0",
"SFO",
[],
"0",
"3",
"LAX",
"2014"
],
[
"0",
"AA",
"16130",
"0",
"LAX",
[],
"0",
"3",
"SFO",
"2014"
],
[
"0",
"AA",
"16130",
"0",
"SFO",
[],
"0",
"3",
"LAX",
"2014"
]
]
},
"traceInfo":{},
"numDocsScanned":3,
"aggregationResults":[],
"timeUsedMs":10,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":102
}curl -X POST \
-d '{"pql":"select count(*) from flights"}' \
http://localhost:8099/query
{
"traceInfo":{},
"numDocsScanned":17,
"aggregationResults":[
{
"function":"count_star",
"value":"17"
}
],
"timeUsedMs":27,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":17
}curl -X POST \
-d '{"pql":"select count(*) from flights group by Carrier"}' \
http://localhost:8099/query
{
"traceInfo":{},
"numDocsScanned":23,
"aggregationResults":[
{
"groupByResult":[
{
"value":"10",
"group":["AA"]
},
{
"value":"9",
"group":["VX"]
},
{
"value":"4",
"group":["WN"]
}
],
"function":"count_star",
"groupByColumns":["Carrier"]
}
],
"timeUsedMs":47,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":23
}