
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
The following summarizes Pinot's releases, from the latest one to the earliest one.
void aggregate(int length, AggregationResultHolder aggregationResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupBySV(int length, int[] groupKeyArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupByMV(int length, int[][] groupKeysArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);collectorTypemergeTypejsonExtractScalar
2020/03/09 23:37:19.879 ERROR [HelixTaskExecutor] [CallbackProcessor@b808af5-pinot] [pinot-broker] [] Message cannot be processed: 78816abe-5288-4f08-88c0-f8aa596114fe, {CREATE_TIMESTAMP=1583797034542, MSG_ID=78816abe-5288-4f08-88c0-f8aa596114fe, MSG_STATE=unprocessable, MSG_SUBTYPE=REFRESH_SEGMENT, MSG_TYPE=USER_DEFINE_MSG, PARTITION_NAME=fooBar_OFFLINE, RESOURCE_NAME=brokerResource, RETRY_COUNT=0, SRC_CLUSTER=pinot, SRC_INSTANCE_TYPE=PARTICIPANT, SRC_NAME=Controller_hostname.domain,com_9000, TGT_NAME=Broker_hostname,domain.com_6998, TGT_SESSION_ID=f6e19a457b80db5, TIMEOUT=-1, segmentName=fooBar_559, tableName=fooBar_OFFLINE}{}{}
java.lang.UnsupportedOperationException: Unsupported user defined message sub type: REFRESH_SEGMENT
at org.apache.pinot.broker.broker.helix.TimeboundaryRefreshMessageHandlerFactory.createHandler(TimeboundaryRefreshMessageHandlerFactory.java:68) ~[pinot-broker-0.2.1172.jar:0.3.0-SNAPSHOT-c9d88e47e02d799dc334d7dd1446a38d9ce161a3]
at org.apache.helix.messaging.handling.HelixTaskExecutor.createMessageHandler(HelixTaskExecutor.java:1096) ~[helix-core-0.9.1.509.jar:0.9.1.509]
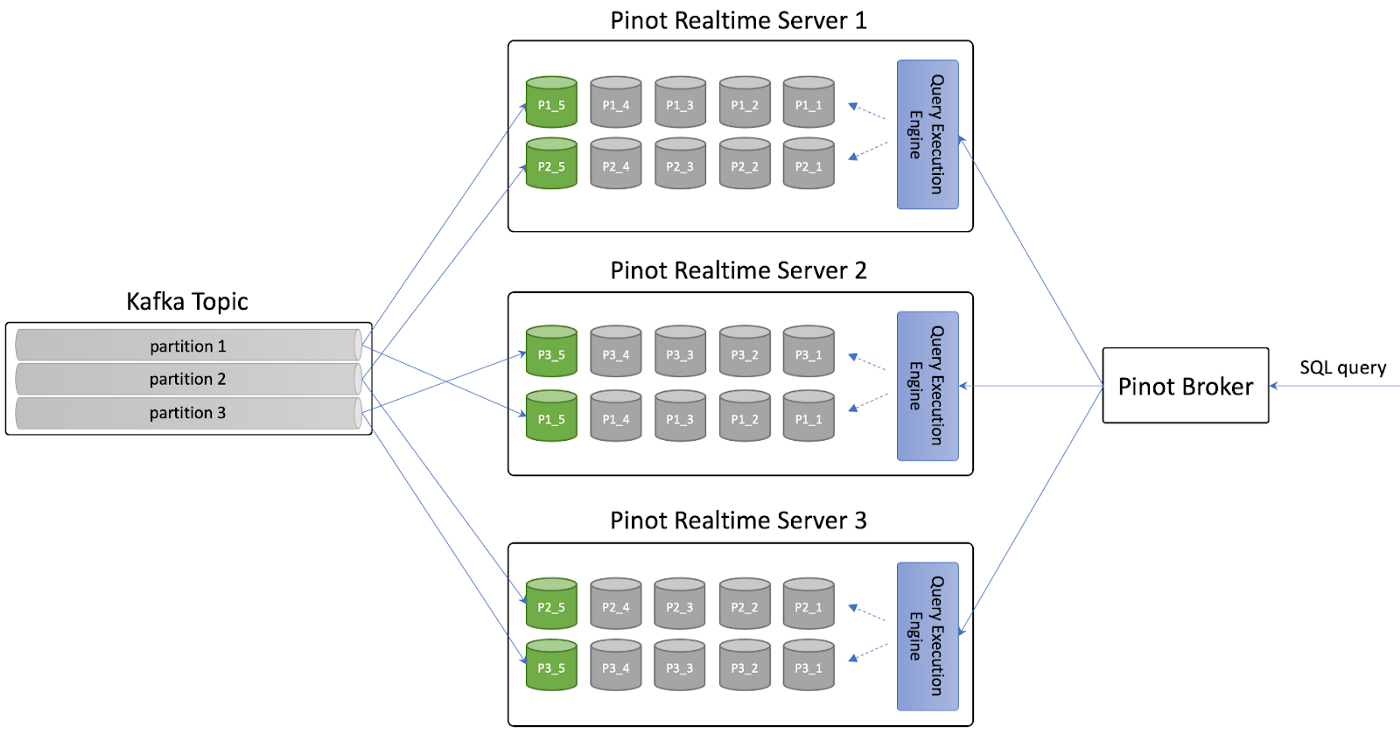
at org.apache.helix.messaging.handling.HelixTaskExecutor.onMessage(HelixTaskExecutor.java:866) [helix-core-0.9.1.509.jar:0.9.1.509]select * FROM foo where text_col LIKE 'a%'select * from foo where text_col CONTAINS 'bar'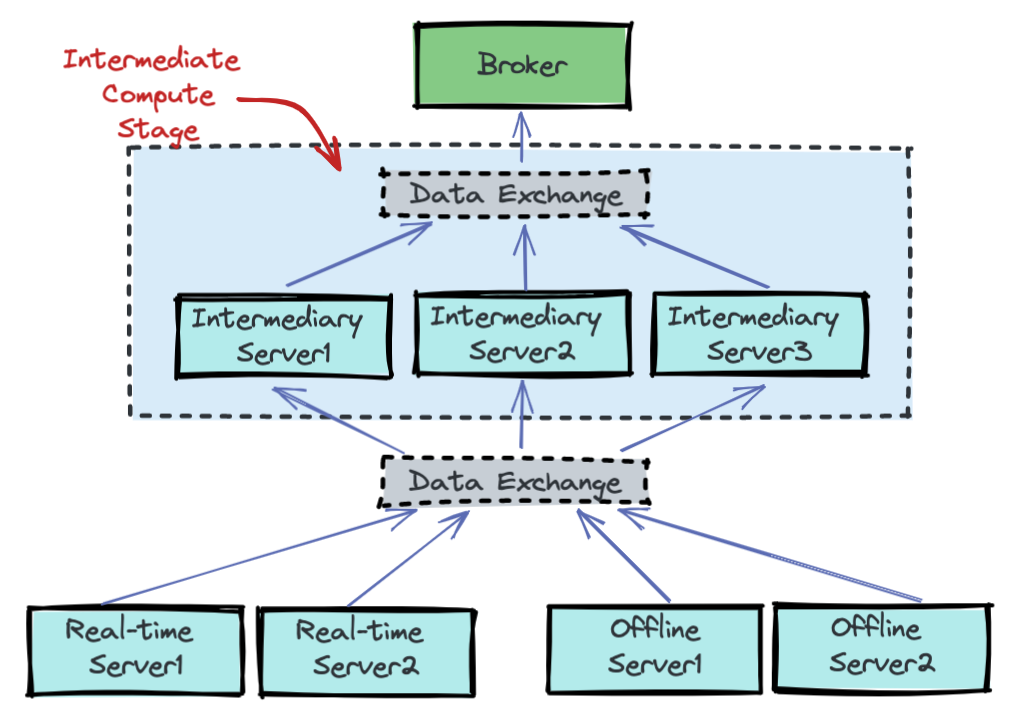
This page covers the latest changes included in the Apache Pinot™ 1.0.0 release, including new features, enhancements, and bug fixes.
pinot.broker.enable.bounded.http.async.executor
pinot.broker.http.async.executor.max.pool.size
pinot.broker.http.async.executor.core.pool.size
pinot.broker.http.async.executor.queue.sizeRelease Notes for version 1.1.0
UltraLogLog ()FrequentStringsSketch and FrequentLonsSketch aggregation functions ()DATETIMECONVERTWINDOWHOP function ()JSON_EXTRACT_INDEX transform function to leverage json index for json value extraction ()GenerateData command support for generating data in JSON format ()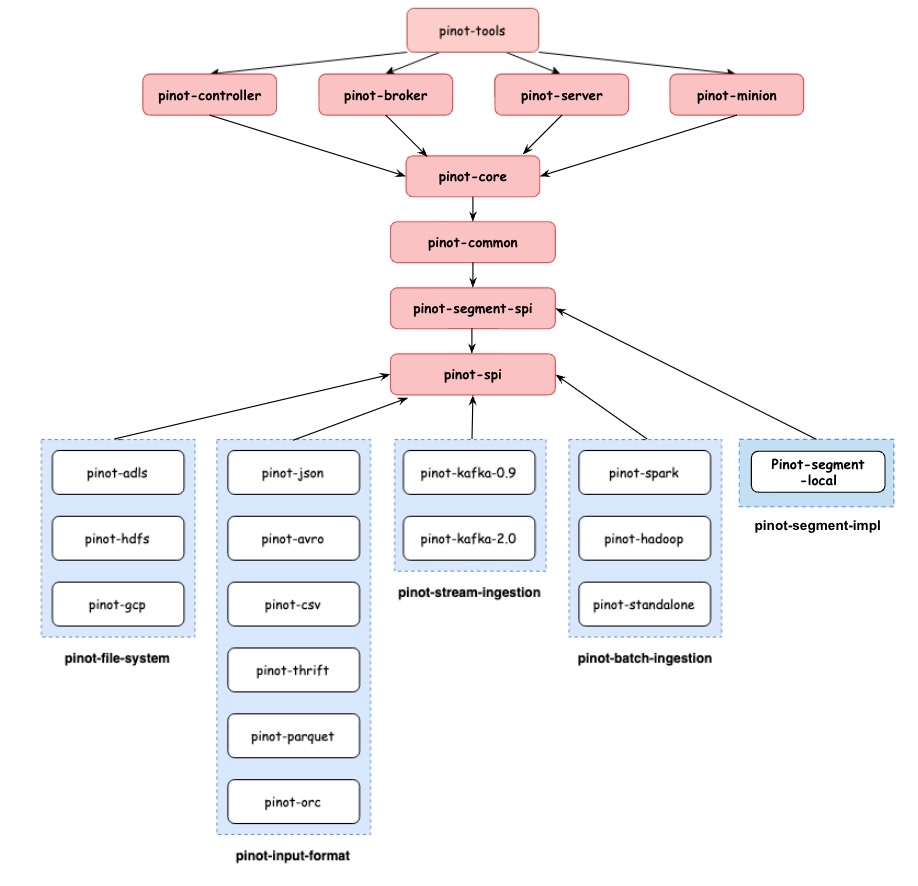
LONGFLOATDOUBLESTRINGTIMESTAMPArrayAgg(intCol, 'INT')ARRAY<INT>x64_32variantfunctionConfigx86_32FieldConfig:invalidDocIdsType to UpsertCompactionTask for advanced user.fromDateTime(colContainsMalformedStr, '<dateTimeFormat>', '<timezone>', <default_value>)"tableIndexConfig": {
..
"segmentPartitionConfig": {
"columnPartitionMap": {
"memberId": {
"functionName": "Murmur3",
"numPartitions": 3
},
..
}
}"tableIndexConfig": {
..
"segmentPartitionConfig": {
"columnPartitionMap": {
"memberId": {
"functionName": "Murmur3",
"numPartitions": 3,
"functionConfig": {
"seed": "9001"
},
},
..
}
} "tableIndexConfig": {
..
"segmentPartitionConfig": {
"columnPartitionMap": {
"memberId": {
"functionName": "Murmur3",
"numPartitions": 3,
"functionConfig" :{
"seed": "9001"
"variant": "x64_32"
},
},
..
}
}The overriding order of priority is:
1. QueryOption -> maxServerResponseSizeBytes
2. QueryOption -> maxQueryResponseSizeBytes
3. TableConfig -> maxServerResponseSizeBytes
4. TableConfig -> maxQueryResponseSizeBytes
5. BrokerConfig -> pinot.broker.max.server.response.size.bytes
6. BrokerConfig -> pinot.broker.max.query.response.size.bytes"task": {
"taskTypeConfigsMap": {
"<task_name>": {
"segmentMapperFileSizeThresholdInBytes": "1000000000"
}
}
}"routing": {
...
"useFixedReplica": true
}"stream.pulsar.issuerUrl": "https://auth.streamnative.cloud"
"stream.pulsar.credsFilePath": "file:///path/to/private_creds_file
"stream.pulsar.audience": "urn:sn:pulsar:test:test-cluster"SELECT ProductId, UserId, l2_distance(embedding, ARRAY[-0.0013143676,-0.011042999,...]) AS l2_dist, n_tokens, combined
FROM fineFoodReviews
WHERE VECTOR_SIMILARITY(embedding, ARRAY[-0.0013143676,-0.011042999,...], 5)
ORDER by l2_dist ASC
LIMIT 10fieldConfigList: [
{
"name": "columnName",
"indexType": "TEXT",
"indexTypes": [
"TEXT"
],
"properties": {
"luceneAnalyzerClass": "org.apache.lucene.analysis.core.KeywordAnalyzer"
},
}
]{
"schemaName": "blablabla",
"dimensionFieldSpecs": [
{
"dataType": "INT",
"name": "nullableField",
"notNull": false
},
{
"dataType": "INT",
"name": "notNullableField",
"notNull": true
},
{
"dataType": "INT",
"name": "defaultNullableField"
},
...
],
"enableColumnBasedNullHandling": true/false
}"starTreeIndexConfigs": [
{
"dimensionsSplitOrder": [
"a",
"b",
"c"
],
"skipStarNodeCreationForDimensions": [],
"functionColumnPairs": [],
"aggregationConfigs": [
{
"columnName": "column1",
"aggregationFunction": "SUM",
"compressionCodec": "SNAPPY"
},
{
"columnName": "column2",
"aggregationFunction": "distinctcounthll",
"compressionCodec": "LZ4"
}
],
"maxLeafRecords": 10000
}
]"instanceAssignmentConfigMap": {
"CONSUMING": {
"partitionSelector": "MIRROR_SERVER_SET_PARTITION_SELECTOR",
"replicaGroupPartitionConfig": { ... },
"tagPoolConfig": {
...
"tag": "mt1_REALTIME"
}
...
}
"COMPLETED": {
"partitionSelector": "MIRROR_SERVER_SET_PARTITION_SELECTOR",
"replicaGroupPartitionConfig": { ... },
"tagPoolConfig": {
...
"tag": "mt1_OFFLINE"
}
...
},
"instancePartitionsMap": {
"CONSUMING": “mt1_CONSUMING"
"COMPLETED": "mt1_OFFLINE"
},arrayIndexOfInt(int[] value, int valToFind)
arrayIndexOfLong(int[] value, long valToFind)
arrayIndexOfFloat(int[] value, float valToFind)
arrayIndexOfDouble(int[] value, double valToFind)
arrayIndexOfString(int[] value, String valToFind)
intersectIndices(int[] values1, int[] values2)FREQUENTLONGSSKETCH(col, maxMapSize=256) -> Base64 encoded sketch object
FREQUENTSTRINGSSKETCH(col, maxMapSize=256) -> Base64 encoded sketch object{
"totalSegments": 31,
"columnToIndexesCount":
{
"col1":
{
"dictionary": 31,
"bloom": 0,
"null": 0,
"forward": 31,
...
"inverted": 0,
"some-dynamically-injected-index-type": 31,
},
"col2":
{
...
}
...
}export PINOT_CONTROLLER_HOST=host
export PINOT_SERVER_PROPERTY_WHATEVER=whatever_property
export ANOTHER_VARIABLE=randomDISTINCTCOUNTHLLPLUS(some_id, 12){
"upsertConfig": {
"mode": "FULL",
"enableSnapshot": true
}
}
...
"task": {
"taskTypeConfigsMap": {
"UpsertCompactionTask": {
"schedule": "0 */5 * ? * *",
"bufferTimePeriod": "7d",
"invalidRecordsThresholdPercent": "30",
"invalidRecordsThresholdCount": "100000",
"invalidDocIdsType": "SNAPSHOT/IN_MEMORY/IN_MEMORY_WITH_DELETE"
}
}
}{
"name": "myCol",
"encodingType": "DICTIONARY",
"compressionCodec": "MV_ENTRY_DICT"
}{
"name": "myCol",
"encodingType": "DICTIONARY",
"indexes": {
"forward": {
"dictIdCompressionType": "MV_ENTRY_DICT"
}
}
}