docker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=manual-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-d bitnami/kafka:latestdocker exec \
-t kafka \
/opt/kafka/bin/kafka-topics.sh \
--zookeeper manual-zookeeper:2181/kafka \
--partitions=1 --replication-factor=1 \
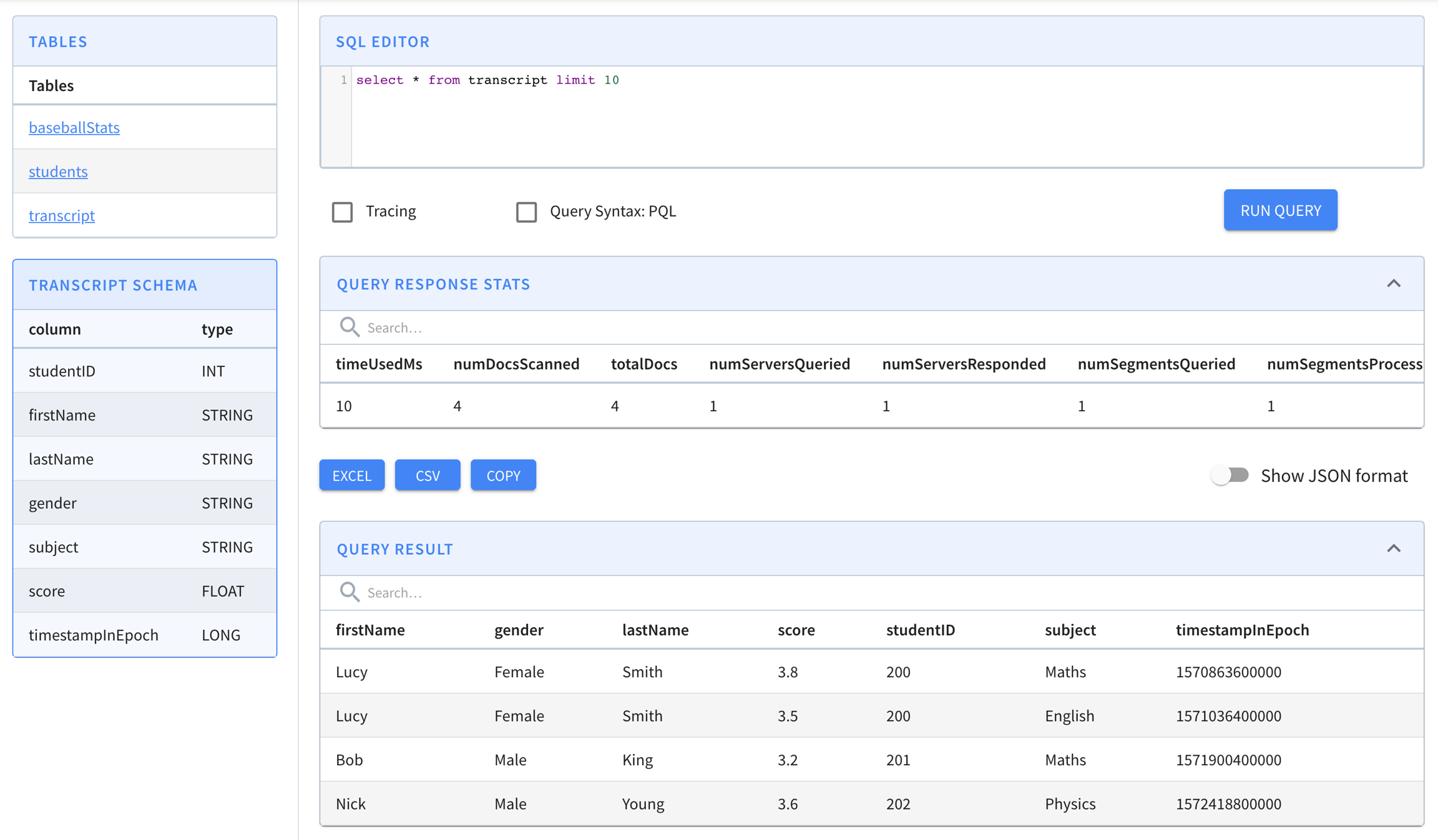
--create --topic transcript-topicbin/pinot-admin.sh StartKafka -zkAddress=localhost:2123/kafka -port 9876{
"tableName": "transcript",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"schemaName": "transcript",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "50M",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}docker run \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost manual-pinot-controller \
-controllerPort 9000 \
-execbin/pinot-admin.sh AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-exec{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestampInEpoch":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestampInEpoch":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestampInEpoch":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestampInEpoch":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestampInEpoch":1572854400000}bin/kafka-console-producer.sh \
--broker-list localhost:9876 \
--topic transcript-topic < /tmp/pinot-quick-start/rawData/transcript.jsonbin/kafka-topics.sh --create --bootstrap-server localhost:9876 --replication-factor 1 --partitions 1 --topic transcript-topic