
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
The following summarizes Pinot's releases, from the latest one to the earliest one.
Before upgrading from one version to another one, please read the release notes. While the Pinot committers strive to keep releases backward-compatible and introduce new features in a compatible manner, your environment may have a unique combination of configurations/data/schema that may have been somehow overlooked. Before you roll out a new release of Pinot on your cluster, it is best that you run the compatibility test suite that Pinot provides. The tests can be easily customized to suit the configurations and tables in your pinot cluster(s). As a good practice, you should build your own test suite, mirroring the table configurations, schema, sample data, and queries that are used in your cluster.
This release fixes the major issue of CVE-2021-44228 and a major bug fixing of pinot admin exit code issue(#7798).
The release is based on the release 0.9.0 with the following cherry-picks:
This is a bug fixing release contains:
Update Log4j to 2.17.0 to address CVE-2021-45105 (#7933)
The release is based on the release 0.9.2 with the following cherry-picks:
Upgrade swagger-ui to 3.23.11 to fix ()
Fix the bug that RealtimeToOfflineTask failed to progress with large time bucket gaps ().
The release is based on the release 0.9.1 with the following cherry-picks:
The 0.2.0 release is the first release after the initial one and includes several improvements, reported following.
Added support for Kafka 2.0
Table rebalancer now supports a minimum number of serving replicas during rebalance
Added support for UDF in filter predicates and selection
Added support to use hex string as the representation of byte array for queries (see PR )
Added support for parquet reader (see PR )
Introduced interface stability and audience annotations (see PR )
Refactor HelixBrokerStarter to separate constructor and start() - backwards incompatible (see PR )
Admin tool for listing segments with invalid intervals for offline tables
Migrated to log4j2 (see PR )
Added simple avro msg decoder
Added support for passing headers in Pinot client
Table rebalancer now supports a minimum number of serving replicas during rebalance
Support transform functions with AVG aggregation function (see PR )
Configurations additions/changes
Allow customized metrics prefix (see PR )
Controller.enable.batch.message.mode to false by default (see PR )
We are in the process of separating Helix and Pinot controllers, so that administrators can have the option of running independent Helix controllers and Pinot controllers.
We are in the process of moving towards supporting SQL query format and results.
We are in the process of separating instance and segment assignment using instance pools to optimize the number of Helix state transitions in Pinot clusters with thousands of tables.
Task management does not work correctly in this release, due to bugs in Helix. We will upgrade to Helix 0.9.2 (or later) version to get this fixed.
You must upgrade to this release before moving onto newer versions of Pinot release. The protocol between Pinot-broker and Pinot-server has been changed and this release has the code to retain compatibility moving forward. Skipping this release may (depending on your environment) cause query errors if brokers are upgraded and servers are in the process of being upgraded.
As always, we recommend that you upgrade controllers first, and then brokers and lastly the servers in order to have zero downtime in production clusters.
RetentionManager and OfflineSegmentIntervalChecker initial delays configurable (see PR )
Config to control kafka fetcher size and increase default (see PR )
Added a percent threshold to consider startup of services (see PR )
Make SingleConnectionBrokerRequestHandler as default (see PR )
Always enable default column feature, remove the configuration (see PR )
Remove redundant default broker configurations (see PR )
Removed some config keys in server(see PR )
Add config to disable HLC realtime segment (see PR )
Make RetentionManager and OfflineSegmentIntervalChecker initial delays configurable (see PR )
The following config variables are deprecated and will be removed in the next release:
pinot.broker.requestHandlerType will be removed, in favor of using the "singleConnection" broker request handler. If you have set this configuration, please remove it and use the default type ("singleConnection") for broker request handler.
Pull Request introduces a backwards incompatible change to Pinot broker. If you use the Java constructor on HelixBrokerStarter class, then you will face a compilation error with this version. You will need to construct the object and call start() method in order to start the broker.
Pull Request introduces a backwards incompatible change for log4j configuration. If you used a custom log4j configuration (log4j.xml), you need to write a new log4j2 configuration (log4j2.xml). In addition, you may need to change the arguments on the command line to start Pinot components.
If you used Pinot-admin command to start Pinot components, you don't need any change. If you used your own commands to start pinot components, you will need to pass the new log4j2 config as a jvm parameter (i.e. substitute -Dlog4j.configuration or -Dlog4j.configurationFile argument with -Dlog4j2.configurationFile=log4j2.xml).
This release includes many new features on Pinot ingestion and connectors, query capability and a revamped controller UI.
This release includes many new features on Pinot ingestion and connectors (e.g., support for filtering during ingestion which is configurable in table config; support for json during ingestion; proto buf input format support and a new Pinot JDBC client), query capability (e.g., a new GROOVY transform function UDF) and admin functions (a revamped Cluster Manager UI & Query Console UI). It also contains many key bug fixes. See details below.
The release was cut from the following commit: d1b4586 and the following cherry-picks:
Allowing update on an existing instance config: PUT /instances/{instanceName} with Instance object as the pay-load ()
Add PinotServiceManager to start Pinot components ()
Support for protocol buffers input format. ()
Changed the stream and metadata interface () — This PR concludes the work for the issue to extend offset support for other streams
TransformConfig: ingestion level column transformations. This was previously introduced in Schema (FieldSpec#transformFunction), and has now been moved to TableConfig. It continues to remain under schema, but we recommend users to set it in the TableConfig starting this release ().
Config key enable.case.insensitive.pql in Helix cluster config is deprecated, and replaced with enable.case.insensitive. (
Fix bug in distinctCountRawHLL on SQL path ()
Fix backward incompatibility for existing stream implementations ()
Fix backward incompatibility in StreamFactoryConsumerProvider ()
PQL queries with HAVING clause will no longer be accepted for the following reasons: () — HAVING clause does not apply to PQL GROUP-BY semantic where each aggregation column is ordered individually — The current behavior can produce inaccurate results without any notice — HAVING support will be added for SQL queries in the next release
Because of the standardization of the DistinctCountThetaSketch predicate strings, please upgrade Broker before Server. The new Broker can handle both standard and non-standard predicate strings for backward-compatibility. ()
0.4.0 release introduced the theta-sketch based distinct count function, an S3 filesystem plugin, a unified star-tree index implementation, migration from TimeFieldSpec to DateTimeFieldSpec, etc.
0.4.0 release introduced various new features, including the theta-sketch based distinct count aggregation function, an S3 filesystem plugin, a unified star-tree index implementation, deprecation of TimeFieldSpec in favor of DateTimeFieldSpec, etc. Miscellaneous refactoring, performance improvement and bug fixes were also included in this release. See details below.
Made DateTimeFieldSpecs mainstream and deprecated TimeFieldSpec (#2756)
Used time column from table config instead of schema (#5320)
Included dateTimeFieldSpec in schema columns of Pinot Query Console #5392
Do not release the PinotDataBuffer when closing the index (#5400)
Handled a no-arg function in query parsing and expression tree (#5375)
Fixed compatibility issues during rolling upgrade due to unknown json fields (#5376)
Upsert: support overriding data in the real-time table (#4261).
Add pinot upsert features to pinot common (#5175)
Enhancements for theta-sketch, e.g. multiValue aggregation support, complex predicates, performance tuning, etc
TableConfig no longer support de-serialization from json string of nested json string (i.e. no \" inside the json) (#5194)
The following APIs are changed in AggregationFunction (use TransformExpressionTree instead of String as the key of blockValSetMap) (#5371):
Add GenericTransformFunction wrapper for simple ScalarFunctions (PR#5440) — Adding support to invoke any scalar function via GenericTransformFunction
Add Support for SQL CASE Statement (PR#5461)
Support distinctCountRawThetaSketch aggregation that returns serialized sketch. (PR#5465)
Add multi-value support to SegmentDumpTool (PR#5487) — add segment dump tool as part of the pinot-tool.sh script
Add json_format function to convert json object to string during ingestion. (PR#5492) — Can be used to store complex objects as a json string (which can later be queries using jsonExtractScalar)
Support escaping single quote for SQL literal (PR#5501) — This is especially useful for DistinctCountThetaSketch because it stores expression as literal E.g. DistinctCountThetaSketch(..., 'foo=''bar''', ...)
Support expression as the left-hand side for BETWEEN and IN clause (PR#5502)
Add a new field IngestionConfig in TableConfig — FilterConfig: ingestion level filtering of records, based on filter function. (PR#5597) — TransformConfig: ingestion level column transformations. This was previously introduced in Schema (FieldSpec#transformFunction), and has now been moved to TableConfig. It continues to remain under schema, but we recommend users to set it in the TableConfig starting this release (PR#5681).
Allow star-tree creation during segment load (#PR5641) — Introduced a new boolean config enableDynamicStarTreeCreation in IndexingConfig to enable/disable star-tree creation during segment load.
Support for Pinot clients using JDBC connection (#PR5602)
Support customized accuracy for distinctCountHLL, distinctCountHLLMV functions by adding log2m value as the second parameter in the function. (#PR5564) —Adding cluster config: default.hyperloglog.log2m to allow user set default log2m value.
Add segment encryption on Controller based on table config (PR#5617)
Add a constraint to the message queue for all instances in Helix, with a large default value of 100000. (PR#5631)
Support order-by aggregations not present in SELECT (PR#5637) — Example: "select subject from transcript group by subject order by count() desc" This is equivalent to the following query but the return response should not contain count(). "select subject, count() from transcript group by subject order by count() desc"
Add geo support for Pinot queries (PR#5654) — Added geo-spatial data model and geospatial functions
Add Controller API to explore Zookeeper (PR#5687)
Support for ingestion job spec in JSON format (#PR5729)
Improvements to RealtimeProvisioningHelper command (#PR5737) — Improved docs related to ingestion and plugins
Added GROOVY transform function UDF (#PR5748) — Ability to run a groovy script in the query as a UDF. e.g. string concatenation: SELECT GROOVY('{"returnType": "INT", "isSingleValue": true}', 'arg0 + " " + arg1', columnA, columnB) FROM myTable
Change default segment load mode to MMAP. (PR#5539) —The load mode for segments currently defaults to heap.
Fix logic in isLiteralOnlyExpression. (#5611)
Fix double memory allocation during operator setup (#5619)
Allow segment download url in Zookeeper to be deep store uri instead of hardcoded controller uri (#5639)
Fix a backward compatible issue of converting BrokerRequest to QueryContext when querying from Presto segment splits (#5676)
Fix the issue that PinotSegmentToAvroConverter does not handle BYTES data type. (#5789)
Used DATE_TIME as the primary time column for Pinot tables (#5399)
Supported range queries using indexes (#5240)
Supported complex aggregation functions
Supported Aggregation functions with multiple arguments (#5261)
Added api in AggregationFunction to get compiled input expressions (#5339)
Added a simple PinotFS benchmark driver (#5160)
Supported default star-tree (#5147)
Added an initial implementation for theta-sketch based distinct count aggregation function (#5316)
One minor side effect: DataSchemaPruner won't work for DistinctCountThetaSketchAggregatinoFunction (#5382)
Added access control for Pinot server segment download api (#5260)
Added Pinot S3 Filesystem Plugin (#5249)
Text search improvement
Pruned stop words for text index (#5297)
Used 8byte offsets in chunk based raw index creator (#5285)
Derived num docs per chunk from max column value length for varbyte raw index creator (#5256)
Added inter segment tests for text search and fixed a bug for Lucene query parser creation (#5226)
Made text index query cache a configurable option (#5176)
Added Lucene DocId to PinotDocId cache to improve performance (#5177)
Removed the construction of second bitmap in text index reader to improve performance (#5199)
Tooling/usability improvement
Added template support for Pinot Ingestion Job Spec (#5341)
Allowed user to specify zk data dir and don't do clean up during zk shutdown (#5295)
Allowed configuring minion task timeout in the PinotTaskGenerator (#5317)
Update JVM settings for scripts (#5127)
Added Stream github events demo (#5189)
Moved docs link from gitbook to docs.pinot.apache.org (#5193)
Re-implemented ORCRecordReader (#5267)
Evaluated schema transform expressions during ingestion (#5238)
Handled count distinct query in selection list (#5223)
Enabled async processing in pinot broker query api (#5229)
Supported bootstrap mode for table rebalance (#5224)
Supported order-by on BYTES column (#5213)
Added Nightly publish to binary (#5190)
Shuffled the segments when rebalancing the table to avoid creating hotspot servers (#5197)
Supported inbuilt transform functions (#5312)
Added date time transform functions (#5326)
Deepstore by-pass in LLC: introduced segment uploader (#5277, #5314)
APIs Additions/Changes
Added a new server api for download of segments
/GET /segments/{tableNameWithType}/{segmentName}
Upgraded helix to 0.9.7 (#5411)
Added support to execute functions during query compilation (#5406)
Other notable refactoring
Moved table config into pinot-spi (#5194)
Cleaned up integration tests. Standardized the creation of schema, table config and segments (#5385)
Added jsonExtractScalar function to extract field from json object (#4597)
Added template support for Pinot Ingestion Job Spec #5372
Cleaned up AggregationFunctionContext (#5364)
Optimized real-time range predicate when cardinality is high (#5331)
Made PinotOutputFormat use table config and schema to create segments (#5350)
Tracked unavailable segments in InstanceSelector (#5337)
Added a new best effort segment uploader with bounded upload time (#5314)
In SegmentPurger, used table config to generate the segment (#5325)
Decoupled schema from RecordReader and StreamMessageDecoder (#5309)
Implemented ARRAYLENGTH UDF for multi-valued columns (#5301)
Improved GroupBy query performance (#5291)
Optimized ExpressionFilterOperator (#5132)
Fixed missing error message from pinot-admin command (#5305)
Fixed HDFS copy logic (#5218)
Fixed spark ingestion issue (#5216)
Fixed the capacity of the DistinctTable (#5204)
Fixed various links in the Pinot website
void aggregate(int length, AggregationResultHolder aggregationResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupBySV(int length, int[] groupKeyArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);
void aggregateGroupByMV(int length, int[][] groupKeysArray, GroupByResultHolder groupByResultHolder, Map<TransformExpressionTree, BlockValSet> blockValSetMap);This release introduced some excellent new features, including upsert, tiered storage, pinot-spark-connector, support of having clause, more validations on table config and schema, support of ordinals
This release introduced some excellent new features, including upsert, tiered storage, pinot-spark-connector, support of having clause, more validations on table config and schema, support of ordinals in GROUP BY and ORDER BY clause, array transform functions, adding push job type of segment metadata only mode, and some new APIs like updating instance tags, new health check endpoint. It also contains many key bug fixes. See details below.
The release was cut from the following commit: e5c9bec and the following cherry-picks:
Tiered storage ()
Upsert feature (, , , , )
Pre-generate aggregation functions in QueryContext ()
Brokers should be upgraded before servers in order to keep backward-compatible:
Change group key delimiter from '\t' to '\0' ()
Support for exact distinct count for non int data types ()
Improve performance of DistinctCountThetaSketch by eliminating empty sketches and unions. ()
Enhance VarByteChunkSVForwardIndexReader to directly read from data buffer for uncompressed data ()
Fixing backward-compatible issue of schema fetch call ()
Make realtime threshold property names less ambiguous ()
Enhance DistinctCountThetaSketchAggregationFunction ()
Deep Extraction Support for ORC, Thrift, and ProtoBuf Records ()
Adding controller healthcheck endpoint: /health (#5846)
Add pinot-spark-connector (#5787)
Support multi-value non-dictionary group by (#5851)
Support type conversion for all scalar functions (#5849)
Add additional datetime functionality (#5438)
Support post-aggregation in ORDER-BY (#5856)
Support post-aggregation in SELECT (#5867)
Add RANGE FilterKind to support merging ranges for SQL (#5898)
Add HAVING support (#58895889)
Support for exact distinct count for non int data types (#5872)
Add max qps bucket count (#5922)
Add Range Indexing support for raw values (#5853)
Add IdSet and IdSetAggregationFunction (#5926)
[Deepstore by-pass]Add a Deepstore bypass integration test with minor bug fixes. (#5857)
Add Hadoop counters for detecting schema mismatch (#5873)
Add RawThetaSketchAggregationFunction (#5970)
Instance API to directly updateTags (#5902)
Add streaming query handler (#5717)
Add InIdSetTransformFunction (#5973)
Add ingestion descriptor in the header (#5995)
Zookeeper put api (#5949)
Feature/#5390 segment indexing reload status api (#5718)
Segment processing framework (#5934)
Support streaming query in QueryExecutor (#6027)
Add list of allowed tables for emitting table level metrics (#6037)
Add FilterOptimizer which supports optimizing both PQL and SQL query filter (#6056)
Adding push job type of segment metadata only mode (#5967)
Adding array transform functions: array_average, array_max, array_min, array_sum (#6084)
Allow modifying/removing existing star-trees during segment reload (#6100)
Implement off-heap bloom filter reader (#6118)
Support for multi-threaded Group By reducer for SQL. (#6044)
Add OnHeapGuavaBloomFilterReader (#6147)
Support using ordinals in GROUP BY and ORDER BY clause (#6152)
Merge common APIs for Dictionary (#6176)
Add table level lock for segment upload ([#6165])
Added recursive functions validation check for group by (#6186)
Add StrictReplicaGroupInstanceSelector (#6208)
Add IN_SUBQUERY support (#6022)
Add IN_PARTITIONED_SUBQUERY support (#6043)
Pinot Components have to be deployed in the following order:
(PinotServiceManager -> Bootstrap services in role ServiceRole.CONTROLLER -> All remaining bootstrap services in parallel)
Starts Broker and Server in parallel when using ServiceManager (#5917)
New settings introduced and old ones deprecated:
Make realtime threshold property names less ambiguous ()
Change Signature of Broker API in Controller ()
This aggregation function is still in beta version. This PR involves change on the format of data sent from server to broker, so it works only when both broker and server are upgraded to the new version:
Enhance DistinctCountThetaSketchAggregationFunction (#6004)
Fix race condition in MetricsHelper (#5887)
Fixing the race condition that segment finished before ControllerLeaderLocator created. (#5864)
Fix CSV and JSON converter on BYTES column (#5931)
Fixing the issue that transform UDFs are parsed as function name 'OTHER', not the real function names (#5940)
Incorporating embedded exception while trying to fetch stream offset (#5956)
Use query timeout for planning phase (#5990)
Add null check while fetching the schema (#5994)
Validate timeColumnName when adding/updating schema/tableConfig (#5966)
Handle the partitioning mismatch between table config and stream (#6031)
Fix built-in virtual columns for immutable segment (#6042)
Refresh the routing when realtime segment is committed (#6078)
Add support for Decimal with Precision Sum aggregation (#6053)
Fixing the calls to Helix to throw exception if zk connection is broken (#6069)
Allow modifying/removing existing star-trees during segment reload (#6100)
Add max length support in schema builder (#6112)
Enhance star-tree to skip matching-all predicate on non-star-tree dimension (#6109)
0.3.0 release of Apache Pinot introduces the concept of plugins that makes it easy to extend and integrate with other systems.
The reason behind the architectural change from the previous release (0.2.0) and this release (0.3.0), is the possibility of extending Apache Pinot. The 0.2.0 release was not flexible enough to support new storage types nor new stream types. Basically, inserting a new functionality required to change too much code. Thus, the Pinot team went through an extensive refactoring and improvement of the source code.
For instance, the picture below shows the module dependencies of the 0.2.X or previous releases. If we wanted to support a new storage type, we would have had to change several modules. Pretty bad, huh?
In order to conquer this challenge, below major changes are made:
Refactored common interfaces to pinot-spi module
Concluded four types of modules:
Pinot input format: How to read records from various data/file formats: e.g. Avro
Now the architecture supports a plug-and-play fashion, where new tools can be supported with little and simple extensions, without affecting big chunks of code. Integrations with new streaming services and data formats can be developed in a much more simple and convenient way.
SQL Support
Added Calcite SQL compiler
Added SQL response format (, )
Fixed the bug of releasing the segment when there are still threads working on it. ()
Fixed the bug of uneven task distribution for threads ()
Fixed encryption for .tar.gz segment file upload ()
We are in the process of supporting text search query functionalities.
We are in the process of supporting null value (), currently limited query feature is supported
Added Presence Vector to represent null value ()
It’s a disruptive upgrade from version 0.1.0 to this because of the protocol changes between Pinot Broker and Pinot Server. Please ensure that you upgrade to release 0.2.0 first, then upgrade to this version.
If you build your own startable or war without using scripts generated in Pinot-distribution module. For Java 8, an environment variable “plugins.dir” is required for Pinot to find out where to load all the Pinot plugin jars. For Java 11, plugins directory is required to be explicitly set into classpath. Please see pinot-admin.sh as an example.
This release introduced several new features, including compatibility tests, enhanced complex type and Json support, partial upsert support, and new stream ingestion plugins.
This release introduced several awesome new features, including compatibility tests, enhanced complex type and Json support, partial upsert support, and new stream ingestion plugins (AWS Kinesis, Apache Pulsar). It contains a lot of query enhancements such as new timestamp and boolean type support and flexible numerical column comparison. It also includes many key bug fixes. See details below.
CSVJSONORCParquetThriftPinot filesystem: How to operate files on various filesystems: e.g. Azure Data Lake/Google Cloud Storage/S3/HDFS
Pinot stream ingestion: How to ingest data stream from various upstream systems, e.g. Kafka/Kinesis/Eventhub
Pinot batch ingestion: How to run Pinot batch ingestion jobs in various frameworks, like Standalone, Hadoop, Spark.
Built shaded jars for each individual plugin
Added support to dynamically load pinot plugins at server startup time
Added support for GROUP BY with ORDER BY (#4602)
Query console defaults to use SQL syntax (#4994)
Added SQL query endpoint: /query/sql (#4964)
Support arithmetic operators (#5018)
Support non-literal expressions for right-side operand in predicate comparison(#5070)
Added support for DISTINCT (#4535)
Added support default value for BYTES column (#4583)
JDK 11 Support
Added support to tune size vs accuracy for approximation aggregation functions: DistinctCountHLL, PercentileEst, PercentileTDigest (#4666)
Added Data Anonymizer Tool (#4747)
Deprecated pinot-hadoop and pinot-spark modules, replace with pinot-batch-ingestion-hadoop and pinot-batch-ingestion-spark
Support STRING and BYTES for no dictionary columns in realtime consuming segments (#4791)
Make pinot-distribution to build a pinot-all jar and assemble it (#4977)
Added support for PQL case insensitive (#4983)
Added experimental support for Text Search (#4993)
Upgraded Helix to version 0.9.4, task management now works as expected (#5020)
Added date_trunc transformation function. (#4740)
Support schema evolution for consuming segment. (#4954)
APIs Additions/Changes
Pinot Admin Command
Added -queryType option in PinotAdmin PostQuery subcommand ()
Added -schemaFile as option in AddTable command ()
Added OperateClusterConfig sub command in PinotAdmin ()
Pinot Controller Rest APIs
Get Table leader controller resource ()
Support HTTP POST/PUT to upload JSON encoded schema (
Configurations Additions/Changes
Config: controller.host is now optional in Pinot Controller
Added instance config: queriesDisabled to disable query sending to a running server (#4767)
Added broker config: pinot.broker.enable.query.limit.override configurable max query response size ()
Removed deprecated server configs ()
pinot.server.starter.enableSegmentsLoadingCheck
pinot.server.starter.timeoutInSeconds
Decouple server instance id with hostname/port config. ()
Add FieldConfig to encapsulate encoding, indexing info for a field.()
Fixed controller rest API to download segment from non local FS. (#4808)
Fixed the bug of not releasing segment lock if segment recovery throws exception (#4882)
Fixed the issue of server not registering state model factory before connecting the Helix manager (#4929)
Fixed the exception in server instance when Helix starts a new ZK session (#4976)
Fixed ThreadLocal DocIdSet issue in ExpressionFilterOperator (#5114)
Fixed the bug in default value provider classes (#5137)
Fixed the bug when no segment exists in RealtimeSegmentSelector (#5138)
Added null predicate support for leaf predicates (#4943)
Kafka 0.9 is no longer included in the release distribution.
Pull request #4806 introduces a backward incompatible API change for segments management.
Removed segment toggle APIs
Removed list all segments in cluster APIs
Deprecated below APIs:
GET /tables/{tableName}/segments
GET /tables/{tableName}/segments/metadata
Pull request #5054 deprecated below task related APIs:
GET:
/tasks/taskqueues: List all task queues
/tasks/taskqueuestate/{taskType} -> /tasks/{taskType}/state
/tasks/tasks/{taskType} -> /tasks/{taskType}/tasks
/tasks/taskstates/{taskType} -> /tasks/{taskType}/taskstates
/tasks/taskstate/{taskName} -> /tasks/task/{taskName}/taskstate
/tasks/taskconfig/{taskName} -> /tasks/task/{taskName}/taskconfig
PUT:
/tasks/scheduletasks -> POST /tasks/schedule
DELETE:
/tasks/taskqueue/{taskType} -> /tasks/{taskType}
Deprecated modules pinot-hadoop and pinot-spark and replaced with pinot-batch-ingestion-hadoop and pinot-batch-ingestion-spark.
Introduced new Pinot batch ingestion jobs and yaml based job specs to define segment generation jobs and segment push jobs.
You may see exceptions like below in pinot-brokers during cluster upgrade, but it's safe to ignore them.
and the following cherry-picks:
Extract time handling for SegmentProcessorFramework (#7158)
Add Apache Pulsar low level and high level connector (#7026)
Enable parallel builds for compat checker (#7149)
Add controller/server API to fetch aggregated segment metadata ()
Support Dictionary Based Plan For DISTINCT ()
Provide HTTP client to kinesis builder ()
Add datetime function with 2 arguments ()
Adding ability to check ingestion status for Offline Pinot table ()
Add timestamp datatype support in JDBC ()
Allow updating controller and broker helix hostname ()
Cancel running Kinesis consumer tasks when timeout occurs ()
Implement Append merger for partial upsert ()
`* SegmentProcessorFramework Enhancement ()
Added TaskMetricsEmitted periodic controler job ()
Support json path expressions in query. ()
Support data preprocessing for AVRO and ORC formats ()
Add partial upsert config and mergers ()
Add support for range index rule recommendation(#7034) ()
Allow reloading consuming segment by default ()
Add LZ4 Compression Codec (#6804) ([#7035](
))
Make Pinot JDK 11 Compilable (\
Introduce in-Segment Trim for GroupBy OrderBy Query ()
Produce GenericRow file in segment processing mapper ()
Add ago() scalar transform function ()
Add Bloom Filter support for IN predicate(#7005) ()
Add genericRow file reader and writer ()
Normalize LHS and RHS numerical types for >, >=, <, and <= operators. ()
Add Kinesis Stream Ingestion Plugin ()
feature/#6766 JSON and Startree index information in API ()
Support null value fields in generic row ser/de ()
Implement PassThroughTransformOperator to optimize select queries(#6972) ()
Optimize TIME_CONVERT/DATE_TIME_CONVERT predicates ()
Prefetch call to fetch buffers of columns seen in the query ()
Enabling compatibility tests in the script ()
Add collectionToJsonMode to schema inference ()
Add the complex-type support to decoder/reader ()
Adding a new Controller API to retrieve ingestion status for realtime… ()
Add support for Long in Modulo partition function. ()
Enhance PinotSegmentRecordReader to preserve null values ()
add complex-type support to avro-to-pinot schema inference ()
Add correct yaml files for real time data(#6787) ()
Add complex-type transformation to offline segment creation ()
Add config File support(#6787) ()
Enhance JSON index to support nested array ()
Add debug endpoint for tables. ()
JSON column datatype support. ()
Allow empty string in MV column ()
Add Zstandard compression support with JMH benchmarking(#6804) ()
Normalize LHS and RHS numerical types for = and != operator. ()
Change ConcatCollector implementation to use off-heap ()
[PQL Deprecation] Clean up the old BrokerRequestOptimizer ()
[PQL Deprecation] Do not compile PQL broker request for SQL query ()
Add TIMESTAMP and BOOLEAN data type support ()
Add admin endpoint for Pinot Minon. ()
Remove the usage of PQL compiler ()
Add endpoints in Pinot Controller, Broker and Server to get system and application configs. ()
Support IN predicate in ColumnValue SegmentPruner(#6756) ()
Enable adding new segments to a upsert-enabled realtime table ()
Interface changes for Kinesis connector ()
Pinot Minion SegmentGenerationAndPush task: PinotFS configs inside taskSpec is always temporary and has higher priority than default PinotFS created by the minion server configs ()
DataTable V3 implementation and measure data table serialization cost on server ()
add uploadLLCSegment endpoint in TableResource ()
File-based SegmentWriter implementation ()
Basic Auth for pinot-controller ()
UI integration with Authentication API and added login page ()
Support data ingestion for offline segment in one pass ()
SumPrecision: support all data types and star-tree ()
complete compatibility regression testing ()
Kinesis implementation Part 1: Rename partitionId to partitionGroupId ()
Make Pinot metrics pluggable ()
Recover the segment from controller when LLC table cannot load it ()
Adding a new API for validating specified TableConfig and Schema ()
Introduce a metric for query/response size on broker. ()
Adding a controller periodic task to clean up dead minion instances ()
Adding new validation for Json, TEXT indexing ()
Always return a response from query execution. ()
After the 0.8.0 release, we will officially support jdk 11, and can now safely start to use jdk 11 features. Code is still compilable with jdk 8 (#6424)
RealtimeToOfflineSegmentsTask config has some backward incompatible changes (#7158)
— timeColumnTransformFunction is removed (backward-incompatible, but rollup is not supported anyway)
— Deprecate collectorType and replace it with mergeType
— Add roundBucketTimePeriod and partitionBucketTimePeriod to config the time bucket for round and partition
Regex path for pluggable MinionEventObserverFactory is changed from org.apache.pinot.*.event.* to org.apache.pinot.*.plugin.minion.tasks.* ()
Moved all pinot built-in minion tasks to the pinot-minion-builtin-tasks module and package them into a shaded jar ()
Reloading consuming segment flag pinot.server.instance.reload.consumingSegment will be true by default ()
Move JSON decoder from pinot-kafka to pinot-json package. ()
Backward incompatible schema change through controller rest API PUT /schemas/{schemaName} will be blocked. ()
Deprecated /tables/validateTableAndSchema in favor of the new configs/validate API and introduced new APIs for /tableConfigs to operate on the realtime table config, offline table config and schema in one shot. ()
Fix race condition in MinionInstancesCleanupTask (#7122)
Fix custom instance id for controller/broker/minion (#7127)
Fix UpsertConfig JSON deserialization. (#7125)
Fix the memory issue for selection query with large limit ()
Fix the deleted segments directory not exist warning ()
Fixing docker build scripts by providing JDK_VERSION as parameter ()
Misc fixes for json data type ()
Fix handling of date time columns in query recommender(#7018) ()
fixing pinot-hadoop and pinot-spark test ()
Fixing HadoopPinotFS listFiles method to always contain scheme ()
fixed GenericRow compare for different _fieldToValueMap size ()
Fix NPE in NumericalFilterOptimizer due to IS NULL and IS NOT NULL operator. ()
Fix the race condition in realtime text index refresh thread (#6858) ()
Fix deep store directory structure ()
Fix NPE issue when consumed kafka message is null or the record value is null. ()
Mitigate calcite NPE bug. ()
Fix the exception thrown in the case that a specified table name does not exist (#6328) ()
Fix CAST transform function for chained transforms ()
Fixed failing pinot-controller npm build ()
2020/03/09 23:37:19.879 ERROR [HelixTaskExecutor] [CallbackProcessor@b808af5-pinot] [pinot-broker] [] Message cannot be processed: 78816abe-5288-4f08-88c0-f8aa596114fe, {CREATE_TIMESTAMP=1583797034542, MSG_ID=78816abe-5288-4f08-88c0-f8aa596114fe, MSG_STATE=unprocessable, MSG_SUBTYPE=REFRESH_SEGMENT, MSG_TYPE=USER_DEFINE_MSG, PARTITION_NAME=fooBar_OFFLINE, RESOURCE_NAME=brokerResource, RETRY_COUNT=0, SRC_CLUSTER=pinot, SRC_INSTANCE_TYPE=PARTICIPANT, SRC_NAME=Controller_hostname.domain,com_9000, TGT_NAME=Broker_hostname,domain.com_6998, TGT_SESSION_ID=f6e19a457b80db5, TIMEOUT=-1, segmentName=fooBar_559, tableName=fooBar_OFFLINE}{}{}
java.lang.UnsupportedOperationException: Unsupported user defined message sub type: REFRESH_SEGMENT
at org.apache.pinot.broker.broker.helix.TimeboundaryRefreshMessageHandlerFactory.createHandler(TimeboundaryRefreshMessageHandlerFactory.java:68) ~[pinot-broker-0.2.1172.jar:0.3.0-SNAPSHOT-c9d88e47e02d799dc334d7dd1446a38d9ce161a3]
at org.apache.helix.messaging.handling.HelixTaskExecutor.createMessageHandler(HelixTaskExecutor.java:1096) ~[helix-core-0.9.1.509.jar:0.9.1.509]
at org.apache.helix.messaging.handling.HelixTaskExecutor.onMessage(HelixTaskExecutor.java:866) [helix-core-0.9.1.509.jar:0.9.1.509]Table rebalance API now requires both table name and type as parameters. (#4824)
Refactored Segments APIs (#4806)
Added segment batch deletion REST API (#4828)
Update schema API to reload table on schema change when applicable (#4838)
Enhance the task related REST APIs (#5054)
Added PinotClusterConfig REST APIs (#5073)
GET /cluster/configs
POST /cluster/configs
DELETE /cluster/configs/{configName}
pinot.server.instance.enable.shutdown.delay
pinot.server.instance.starter.maxShutdownWaitTime
pinot.server.instance.starter.checkIntervalTime
GET /tables/{tableName}/segments/crcGET /tables/{tableName}/segments/{segmentName}
GET /tables/{tableName}/segments/{segmentName}/metadata
GET /tables/{tableName}/segments/{segmentName}/reload
POST /tables/{tableName}/segments/{segmentName}/reload
GET /tables/{tableName}/segments/reload
POST /tables/{tableName}/segments/reload
/tasks/cleanuptasks/{taskType} -> /tasks/{taskType}/cleanup/tasks/taskqueue/{taskType}: Toggle a task queue

This release introduced several awesome new features, including JSON index, lookup-based join support, geospatial support, TLS support for pinot connections, and various performance optimizations.
This release introduced several awesome new features, including JSON index, lookup-based join support, geospatial support, TLS support for pinot connections, and various performance optimizations and improvements.
It also adds several new APIs to better manage the segments and upload data to the offline table. It also contains many key bug fixes. See details below.
and the following cherry-picks:
Add a server metric: queriesDisabled to check if queries disabled or not. (#6586)
Support validation for jsonExtractKey and jsonExtractScalar functions () ()
Real Time Provisioning Helper tool improvement to take data characteristics as input instead of an actual segment ()
Add the isolation level config isolation.level to Kafka consumer (2.0) to ingest transactionally committed messages only ()
Enhance StarTreeIndexViewer to support multiple trees ()
Improves ADLSGen2PinotFS with service principal based auth, auto create container on initial run. It's backwards compatible with key based auth. ()
Add metrics for minion tasks status ()
Use minion data directory as tmp directory for SegmentGenerationAndPushTask to ensure directory is always cleaned up ()
Add optional HTTP basic auth to pinot broker, which enables user- and table-level authentication of incoming queries. ()
Add Access Control for REST endpoints of Controller ()
Add date_trunc to scalar functions to support date_trunc during ingestion ()
Allow tar gz with > 8gb size ()
Add Lookup UDF Join support (), (), () ()
Add cron scheduler metrics reporting ()
Support generating derived column during segment load, so that derived columns can be added on-the-fly ()
Support chained transform functions ()
Add scalar function JsonPathArray to extract arrays from json ()
Add a guard against multiple consuming segments for same partition ()
Remove the usage of deprecated range delimiter ()
Handle scheduler calls with proper response when it's disabled. ()
Simplify SegmentGenerationAndPushTask handling getting schema and table config ()
Add a cluster config to config number of concurrent tasks per instance for minion task: SegmentGenerationAndPushTaskGenerator ()
Replace BrokerRequestOptimizer with QueryOptimizer to also optimize the PinotQuery ()
Add additional string scalar functions ()
Add additional scalar functions for array type ()
Add CRON scheduler for Pinot tasks ()
Set default Data Type while setting type in Add Schema UI dialog ()
Add ImportData sub command in pinot admin ()
H3-based geospatial index () ()
Add JSON index support () () ()
Make minion tasks pluggable via reflection ()
Add compatibility test for segment operations upload and delete ()
Add segment reset API that disables and then enables the segment ()
Add Pinot minion segment generation and push task. ()
Add a version option to pinot admin to show all the component versions ()
Add FST index using lucene lib to speedup REGEXP_LIKE operator on text ()
Add APIs for uploading data to an offline table. ()
Allow the use of environment variables in stream configs ()
Enhance task schedule api for single type/table support ()
Add broker time range based pruner for routing. Query operators supported: RANGE, =, <, <=, >, >=, AND, OR()
Add json path functions to extract values from json object ()
Create a pluggable interface for Table config tuner ()
Add a Controller endpoint to return table creation time ()
Add tooltips, ability to enable-disable table state to the UI ()
Add Pinot Minion client ()
Add more efficient use of RoaringBitmap in OnHeapBitmapInvertedIndexCreator and OffHeapBitmapInvertedIndexCreator ()
Add decimal percentile support. ()
Add API to get status of consumption of a table ()
Add support to add offline and realtime tables, individually able to add schema and schema listing in UI ()
Improve performance for distinct queries ()
Allow adding custom configs during the segment creation phase ()
Use sorted index based filtering only for dictionary encoded column ()
Enhance forward index reader for better performance ()
Support for text index without raw ()
Add api for cluster manager to get table state ()
Perf optimization for SQL GROUP BY ORDER BY ()
Add support using environment variables in the format of ${VAR_NAME:DEFAULT_VALUE} in Pinot table configs. ()
Pinot controller metrics prefix is fixed to add a missing dot (#6499). This is a backward-incompatible change that JMX query on controller metrics must be updated
Legacy group key delimiter (\t) was removed to be backward-compatible with release 0.5.0 (#6589)
Upgrade zookeeper version to 3.5.8 to fix ZOOKEEPER-2184: Zookeeper Client should re-resolve hosts when connection attempts fail. (#6558)
Add TLS-support for client-pinot and pinot-internode connections () Upgrades to a TLS-enabled cluster can be performed safely and without downtime. To achieve a live-upgrade, go through the following steps:
First, configure alternate ingress ports for https/netty-tls on brokers, controllers, and servers. Restart the components with a rolling strategy to avoid cluster downtime.
Second, verify manually that https access to controllers and brokers is live. Then, configure all components to prefer TLS-enabled connections (while still allowing unsecured access). Restart the individual components.
PQL endpoint on Broker is deprecated ()
Apache Pinot has adopted SQL syntax and semantics. Legacy PQL (Pinot Query Language) is deprecated and no longer supported. Please use SQL syntax to query Pinot on broker endpoint /query/sql and controller endpoint /sql
Fix the SIGSEGV for large index (#6577)
Handle creation of segments with 0 rows so segment creation does not fail if data source has 0 rows. (#6466)
Fix QueryRunner tool for multiple runs (#6582)
Use URL encoding for the generated segment tar name to handle characters that cannot be parsed to URI. ()
Fix a bug of miscounting the top nodes in StarTreeIndexViewer ()
Fix the raw bytes column in real-time segment ()
Fixes a bug to allow using JSON_MATCH predicate in SQL queries ()
Fix the overflow issue when loading the large dictionary into the buffer ()
Fix empty data table for distinct query ()
Fix the default map return value in DictionaryBasedGroupKeyGenerator ()
Fix log message in ControllerPeriodicTask ()
Fix bug : RealtimeTableDataManager shuts down SegmentBuildTimeLeaseExtender for all tables in the host ()
Fix license headers and plugin checks
Third, disable insecure connections via configuration. You may also have to set controller.vip.protocol and controller.vip.port and update the configuration files of any ingestion jobs. Restart components a final time and verify that insecure ingress via http is not available anymore.
Apache Pinot 0.11.0 has introduced many new features to extend the query abilities, e.g. the Multi-Stage query engine enables Pinot to do distributed joins, more sql syntax(DML support), query functions and indexes(Text index, Timestamp index) supported for new use cases. And as always, more integrations with other systems(E.g. Spark3, Flink).
Note: there is a major upgrade for Apache Helix to 1.0.4, so please make sure you upgrade the system in the order of:
Helix Controller -> Pinot Controller -> Pinot Broker -> Pinot server
The new multi-stage query engine (a.k.a V2 query engine) is designed to support more complex SQL semantics such as JOIN, OVER window, MATCH_RECOGNIZE and eventually, make Pinot support closer to full ANSI SQL semantics. More to read:
Pinot operators can pause realtime consumption of events while queries are being executed, and then resume consumption when ready to do so again.
More to read:
The gapfilling functions allow users to interpolate data and perform powerful aggregations and data processing over time series data. More to read:
Long waiting feature for segment generation on Spark 3.x.
Similar to the Spark Pinot connector, this allows Flink users to dump data from the Flink application to Pinot.
This feature allows better fine-grained control on pinot queries.
This allows users to have better query performance on the timestamp column for lower granularity. See:
Wanna search text in realtime? The new text indexing engine in Pinot supports the following capabilities:
New operator: LIKE
New operator: CONTAINS
Native text index, built from the ground up, focusing on Pinot’s time series use cases and utilizing existing Pinot indices and structures(inverted index, bitmap storage).
Real Time Text Index
Read more:
Now you can use INSERT INTO [database.]table FROM FILE dataDirURI OPTION ( k=v ) [, OPTION (k=v)]* to load data into Pinot from a file using Minion. See:
This feature supports enabling deduplication for realtime tables, via a top-level table config. At a high level, primaryKey (as defined in the table schema) hashes are stored into in-memory data structures, and each incoming row is validated against it. Duplicate rows are dropped.
The expectation while using this feature is for the stream to be partitioned by the primary key, strictReplicaGroup routing to be enabled, and the configured stream consumer type to be low level. These requirements are therefore mandated via table config API's input validations.
Add support for functions arrayConcatLong, arrayConcatFloat, arrayConcatDouble ()
Add support for regexpReplace scalar function ()
Add support for Base64 Encode/Decode Scalar Functions ()
add query cancel APIs on controller backed by those on brokers ()
Add an option to search input files recursively in ingestion job. The default is set to true to be backward compatible. ()
Adding endpoint to download local log files for each component ()
Pinot has resolved all the high-level vulnerabilities issues:
Add a new workflow to check vulnerabilities using trivy ()
Disable Groovy function by default ()
Upgrade netty due to security vulnerability ()
Nested arrays and map not handled correctly for complex types ()
Fix empty data block not returning schema ()
Allow mvn build with development webpack; fix instances default value ()
This release introduces a new features: Segment Merge and Rollup to simplify users day to day operational work. A new metrics plugin is added to support dropwizard. As usual, new functionalities and many UI/ Performance improvements.
The release was cut from the following commit: 13c9ee9 and the following cherry-picks: 668b5e0, ee887b9
LinkedIn operates a large multi-tenant cluster that serves a business metrics dashboard, and noticed that their tables consisted of millions of small segments. This was leading to slow operations in Helix/Zookeeper, long running queries due to having too many tasks to process, as well as using more space because of a lack of compression.
To solve this problem they added the Segment Merge task, which compresses segments based on timestamps and rolls up/aggregates older data. The task can be run on a schedule or triggered manually via the Pinot REST API.
At the moment this feature is only available for offline tables, but will be added for real-time tables in a future release.
Major Changes:
Integrate enhanced SegmentProcessorFramework into MergeRollupTaskExecutor ()
Merge/Rollup task scheduler for offline tables. ()
Fix MergeRollupTask uploading segments not updating their metadata ()
This release also sees improvements to Pinot’s query console UI.
Cmd+Enter shortcut to run query in query console ()
Showing tooltip in SQL Editor ()
Make the SQL Editor box expandable ()
There have also been improvements and additions to Pinot’s SQL implementation.
IN ()
LASTWITHTIME ()
ID_SET on MV columns ()
LIKE()
REGEXP_EXTRACT()
FILTER()
Infer data type for Literal ()
Support logical identifier in predicate ()
Support JSON queries with top-level array path expression. ()
This release contains many performance improvement, you may sense it for you day to day queries. Thanks to all the great contributions listed below:
Reduce the disk usage for segment conversion task ()
Simplify association between Java Class and PinotDataType for faster mapping ()
Avoid creating stateless ParseContextImpl once per jsonpath evaluation, avoid varargs allocation ()
Human Readable Controller Configs ()
Add the support of geoToH3 function ()
Add Apache Pulsar as Pinot Plugin () ()
Fix null pointer exception for non-existed metric columns in schema for JDBC driver ()
Fix the config key for TASK_MANAGER_FREQUENCY_PERIOD ()
Fixed pinot java client to add zkClient close ()
MergeRollupTask integration tests (#7283)
Add mergeRollupTask delay metrics (#7368)
MergeRollupTaskGenerator enhancement: enable parallel buckets scheduling (#7481)
Use maxEndTimeMs for merge/roll-up delay metrics. (#7617)
Fix tables ordering by number of segments (#7564)
Raw results for Percentile TDigest and Est (#7226),
Add timezone as argument in function toDateTime (#7552)
Support configurable group by trim size to improve results accuracy (#7241)
Replace MINUS with STRCMP (#7394)
Bit-sliced range index for int, long, float, double, dictionarized SV columns (#7454)
Use MethodHandle to access vectorized unsigned comparison on JDK9+ (#7487)
Add option to limit thread usage per query (#7492)
Improved range queries (#7513)
Faster bitmap scans (#7530)
Optimize EmptySegmentPruner to skip pruning when there is no empty segments (#7531)
Map bitmaps through a bounded window to avoid excessive disk pressure (#7535)
Allow RLE compression of bitmaps for smaller file sizes (#7582)
Support raw index properties for columns with JSON and RANGE indexes (#7615)
Introduce LZ4_WITH_LENGTH chunk compression type (#7655)
Enhance ColumnValueSegmentPruner and support bloom filter prefetch (#7654)
Apply the optimization on dictIds within the segment to DistinctCountHLL aggregation func (#7630)
During segment pruning, release the bloom filter after each segment is processed (#7668)
Fix JSONPath cache inefficient issue (#7409)
Optimize getUnpaddedString with SWAR padding search (#7708)
Lighter weight LiteralTransformFunction, avoid excessive array fills (#7707)
Inline binary comparison ops to prevent function call overhead (#7709)
Memoize literals in query context in order to deduplicate them (#7720)
Add dropwizard metrics plugin (#7263)
Introduce OR Predicate Execution On Star Tree Index (#7184)
Allow to extract values from array of objects with jsonPathArray (#7208)
Add Realtime table metadata and indexes API. (#7169)
Support array with mixing data types (#7234)
Support force download segment in reload API (#7249)
Show uncompressed znRecord from zk api (#7304)
Add debug endpoint to get minion task status. (#7300)
Validate CSV Header For Configured Delimiter (#7237)
Add auth tokens and user/password support to ingestion job command (#7233)
Add option to store the hash of the upsert primary key (#7246)
Add null support for time column (#7269)
Add mode aggregation function (#7318)
Support disable swagger in Pinot servers (#7341)
Delete metadata properly on table deletion (#7329)
Add basic Obfuscator Support (#7407)
Mask credentials in debug endpoint /appconfigs (#7452)
Fix /sql query endpoint now compatible with auth (#7230)
Fix case sensitive issue in BasicAuthPrincipal permission check (#7354)
Fix auth token injection in SegmentGenerationAndPushTaskExecutor (#7464)
Add segmentNameGeneratorType config to IndexingConfig (#7346)
Support trigger PeriodicTask manually (#7174)
Add endpoint to check minion task status for a single task. (#7353)
Showing partial status of segment and counting CONSUMING state as good segment status (#7327)
Add "num rows in segments" and "num segments queried per host" to the output of Realtime Provisioning Rule (#7282)
Check schema backward-compatibility when updating schema through addSchema with override (#7374)
Optimize IndexedTable (#7373)
Support indices remove in V3 segment format (#7301)
Optimize TableResizer (#7392)
Introduce resultSize in IndexedTable (#7420)
Offset based realtime consumption status checker (#7267)
Add causes to stack trace return (#7460)
Create controller resource packages config key (#7488)
Enhance TableCache to support schema name different from table name (#7525)
Add validation for realtimeToOffline task (#7523)
Unify CombineOperator multi-threading logic (#7450)
Support no downtime rebalance for table with 1 replica in TableRebalancer (#7532)
Introduce MinionConf, move END_REPLACE_SEGMENTS_TIMEOUT_MS to minion config instead of task config. (#7516)
Adjust tuner api (#7553)
Adding config for metrics library (#7551)
Add geo type conversion scalar functions (#7573)
Add BOOLEAN_ARRAY and TIMESTAMP_ARRAY types (#7581)
Add MV raw forward index and MV BYTES data type (#7595)
Enhance TableRebalancer to offload the segments from most loaded instances first (#7574)
Improve get tenant API to differentiate offline and realtime tenants (#7548)
Refactor query rewriter to interfaces and implementations to allow customization (#7576)
In ServiceStartable, apply global cluster config in ZK to instance config (#7593)
Make dimension tables creation bypass tenant validation (#7559)
Allow Metadata and Dictionary Based Plans for No Op Filters (#7563)
Reject query with identifiers not in schema (#7590)
Round Robin IP addresses when retry uploading/downloading segments (#7585)
Support multi-value derived column in offline table reload (#7632)
Support segmentNamePostfix in segment name (#7646)
Add select segments API (#7651)
Controller getTableInstance() call now returns the list of live brokers of a table. (#7556)
Allow MV Field Support For Raw Columns in Text Indices (#7638)
Allow override distinctCount to segmentPartitionedDistinctCount (#7664)
Add a quick start with both UPSERT and JSON index (#7669)
Add revertSegmentReplacement API (#7662)
Smooth segment reloading with non blocking semantic (#7675)
Clear the reused record in PartitionUpsertMetadataManager (#7676)
Replace args4j with picocli (#7665)
Allow adding JSON data type for dimension column types (#7718)
Separate SegmentDirectoryLoader and tierBackend concepts (#7737)
Implement size balanced V4 raw chunk format (#7661)
Add presto-pinot-driver lib (#7384)
Ignore query json parse errors (#7165)
Make STRING to BOOLEAN data type change as backward compatible schema change (#7259)
Replace gcp hardcoded values with generic annotations (#6985)
Fix segment conversion executor for in-place conversion (#7265)
Fix reporting consuming rate when the Kafka partition level consumer isn't stopped (#7322)
Fix the issue with concurrent modification for segment lineage (#7343)
Fix TableNotFound error message in PinotHelixResourceManager (#7340)
Fix upload LLC segment endpoint truncated download URL (#7361)
Fix task scheduling on table update (#7362)
Fix metric method for ONLINE_MINION_INSTANCES metric (#7363)
Fix JsonToPinotSchema behavior to be consistent with AvroSchemaToPinotSchema (#7366)
Fix currentOffset volatility in consuming segment(#7365)
Fix misleading error msg for missing URI (#7367)
Fix the correctness of getColumnIndices method (#7370)
Fix SegmentZKMetadta time handling (#7375)
Fix retention for cleaning up segment lineage (#7424)
Fix segment generator to not return illegal filenames (#7085)
Fix missing LLC segments in segment store by adding controller periodic task to upload them (#6778)
Fix parsing error messages returned to FileUploadDownloadClient (#7428)
Fix manifest scan which drives /version endpoint (#7456)
Fix missing rate limiter if brokerResourceEV becomes null due to ZK connection (#7470)
Fix race conditions between segment merge/roll-up and purge (or convertToRawIndex) tasks: (#7427)
Fix pql double quote checker exception (#7485)
Fix minion metrics exporter config (#7496)
Fix segment unable to retry issue by catching timeout exception during segment replace (#7509)
Add Exception to Broker Response When Not All Segments Are Available (Partial Response) (#7397)
Fix segment generation commands (#7527)
Return non zero from main with exception (#7482)
Fix parquet plugin shading error (#7570)
Fix the lowest partition id is not 0 for LLC (#7066)
Fix star-tree index map when column name contains '.' (#7623)
Fix cluster manager URLs encoding issue(#7639)
Fix fieldConfig nullable validation (#7648)
Fix verifyHostname issue in FileUploadDownloadClient (#7703)
Fix TableCache schema to include the built-in virtual columns (#7706)
Fix DISTINCT with AS function (#7678)
Fix SDF pattern in DataPreprocessingHelper (#7721)
Fix fields missing issue in the source in ParquetNativeRecordReader (#7742)
Optimize like to regexp conversion to do not include unnecessary ^._ and ._$ (#8893)
Support DISTINCT on multiple MV columns (#8873)
Support DISTINCT on single MV column (#8857)
Add histogram aggregation function (#8724)
Optimize dateTimeConvert scalar function to only parse the format once (#8939)
Support conjugates for scalar functions, add more scalar functions (#8582)
Add PercentileSmartTDigestAggregationFunction (#8565)
Simplify the parameters for DistinctCountSmartHLLAggregationFunction (#8566)
add scalar function for cast so it can be calculated at compile time (#8535)
Scalable Gapfill Implementation for Avg/Count/Sum (#8647)
Add commonly used math, string and date scalar functions in Pinot (#8304)
Datetime transform functions (#8397)
Scalar function for url encoding and decoding (#8378)
Add support for IS NULL and NOT IS NULL in transform functions (#8264)
Support st_contains using H3 index (#8498)
Add metrics to track controller segment download and upload requests in progress (#9258)
add a freshness based consumption status checker (#9244)
Force commit consuming segments (#9197)
Adding kafka offset support for period and timestamp (#9193)
Make upsert metadata manager pluggable (#9186)
Adding logger utils and allow change logger level at runtime (#9180)
Proper null handling in equality, inequality and membership operators for all SV column data types (#9173)
support to show running queries and cancel query by id (#9171)
Enhance upsert metadata handling (#9095)
Proper null handling in Aggregation functions for SV data types (#9086)
Add support for IAM role based credentials in Kinesis Plugin (#9071)
Task genrator debug api (#9058)
[colocated-join] Adds Support for instancePartitionsMap in Table Config (#8989)
Support pause/resume consumption of realtime tables (#8986)
Add Protocol Buffer Stream Decoder (#8972)
Update minion task metadata ZNode path (#8959)
add /tasks/{taskType}/{tableNameWithType}/debug API (#8949)
Defined a new broker metric for total query processing time (#8941)
Proper null handling in SELECT, ORDER BY, DISTINCT, and GROUP BY (#8927)
fixing REGEX OPTION parser (#8905)
Enable key value byte stitching in PulsarMessageBatch (#8897)
Add property to skip adding hadoop jars to package (#8888)
Support DISTINCT on multiple MV columns (#8873)
Implement Mutable FST Index (#8861)
Support DISTINCT on single MV column (#8857)
Add controller API for reload segment task status (#8828)
Spark Connector, support for TIMESTAMP and BOOLEAN fields (#8825)
allow up to 4GB per bitmap index (#8796)
Deprecate debug options and always use query options (#8768)
Streamed segment download & untar with rate limiter to control disk usage (#8753)
Improve the Explain Plan accuracy (#8738)
allow to set https as the default scheme (#8729)
Add histogram aggregation function (#8724)
Allow table name with dots by a PinotConfiguration switch (#8713)
Disable Groovy function by default (#8711)
Deduplication (#8708)
Add pluggable client auth provider (#8670)
Adding pinot file system command (#8659)
Allow broker to automatically rewrite expensive function to its approximate counterpart (#8655)
allow to take data outside the time window by negating the window filter (#8640)
Support BigDecimal raw value forward index; Support BigDecimal in many transforms and operators (#8622)
Ingestion Aggregation Feature (#8611)
Enable uploading segments to realtime tables (#8584)
Package kafka 0.9 shaded jar to pinot-distribution (#8569)
Simplify the parameters for DistinctCountSmartHLLAggregationFunction (#8566)
Add PercentileSmartTDigestAggregationFunction (#8565)
Add support for Spark 3.x (#8560)
Adding DML definition and parse SQL InsertFile (#8557)
endpoints to get and delete minion task metadata (#8551)
Add query option to use more replica groups (#8550)
Only discover public methods annotated with @ScalarFunction (#8544)
Support single-valued BigDecimal in schema, type conversion, SQL statements and minimum set of transforms. (#8503)
Add connection based FailureDetector (#8491)
Add endpoints for some finer control on minion tasks (#8486)
Add adhoc minion task creation endpoint (#8465)
Rewrite PinotQuery based on expression hints at instance/segment level (#8451)
Allow disabling dict generation for High cardinality columns (#8398)
add segment size metric on segment push (#8387)
Implement Native Text Operator (#8384)
Change default memory allocation for consuming segments from on-heap to off-heap (#8380)
New Pinot storage metrics for compressed tar.gz and table size w/o replicas (#8358)
add a experiment API for upsert heap memory estimation (#8355)
Timestamp type index (#8343)
Upgrade Helix to 1.0.4 in Pinot (#8325)
Allow overriding expression in query through query config (#8319)
Always handle null time values (#8310)
Add prefixesToRename config for renaming fields upon ingestion (#8273)
Added multi column partitioning for offline table (#8255)
Automatically update broker resource on broker changes (#8249)
Upgrade protobuf as the current version has security vulnerability (#8287)
Upgrade to hadoop 2.10.1 due to cves (#8478)
Upgrade Helix to 1.0.4 (#8325)
Upgrade thrift to 0.15.0 (#8427)
Upgrade jetty due to security issue (#8348)
Upgrade netty (#8346)
Upgrade snappy version (#8494)
Fix the race condition of reflection scanning classes (#9167)
Fix ingress manifest for controller and broker (#9135)
Fix jvm processors count (#9138)
Fix grpc query server not setting max inbound msg size (#9126)
Fix upsert replace (#9132)
Fix the race condition for partial upsert record read (#9130)
Fix log msg, as it missed one param value (#9124)
Fix authentication issue when auth annotation is not required (#9110)
Fix segment pruning that can break server subquery (#9090)
Fix the NPE for ADLSGen2PinotFS (#9088)
Fix cross merge (#9087)
Fix LaunchDataIngestionJobCommand auth header (#9070)
Fix catalog skipping (#9069)
Fix adding util for getting URL from InstanceConfig (#8856)
Fix string length in MutableColumnStatistics (#9059)
Fix instance details page loading table for tenant (#9035)
Fix thread safety issue with java client (#8971)
Fix allSegmentLoaded check (#9010)
Fix bug in segmentDetails table name parsing; style the new indexes table (#8958)
Fix pulsar close bug (#8913)
Fix REGEX OPTION parser (#8905)
Avoid reporting negative values for server latency. (#8892)
Fix getConfigOverrides in MinionQuickstart (#8858)
Fix segment generation error handling (#8812)
Fix multi stage engine serde (#8689)
Fix server discovery (#8664)
Fix Upsert config validation to check for metrics aggregation (#8781)
Fix multi value column index creation (#8848)
Fix grpc port assignment in multiple server quickstart (#8834)
Spark Connector GRPC reader fix for reading realtime tables (#8824)
Fix auth provider for minion (#8831)
Fix metadata push mode in IngestionUtils (#8802)
Misc fixes on segment validation for uploaded real-time segments (#8786)
Fix a typo in ServerInstance.startQueryServer() (#8794)
Fix the issue of server opening up query server prematurely (#8785)
Fix regression where case order was reversed, add regression test (#8748)
Fix dimension table load when server restart or reload table (#8721)
Fix when there're two index filter operator h3 inclusion index throw exception (#8707)
Fix the race condition of reading time boundary info (#8685)
Fix pruning in expressions by max/min/bloom (#8672)
Fix GcsPinotFs listFiles by using bucket directly (#8656)
Fix column data type store for data table (#8648)
Fix the potential NPE for timestamp index rewrite (#8633)
Fix on timeout string format in KinesisDataProducer (#8631)
Fix bug in segment rebalance with replica group segment assignment (#8598)
Fix the upsert metadata bug when adding segment with same comparison value (#8590)
Fix the deadlock in ClusterChangeMediator (#8572)
Fix BigDecimal ser/de on negative scale (#8553)
Fix table creation bug for invalid realtime consumer props (#8509)
Fix the bug of missing dot to extract sub props from ingestion job filesytem spec and minion segmentNameGeneratorSpec (#8511)
Fix ChildTraceId when using multiple child threads, make them unique (#8443)
Fix the group-by reduce handling when query times out (#8450)
Fix a typo in BaseBrokerRequestHandler (#8448)
Fix TIMESTAMP data type usage during segment creation (#8407)
Fix async-profiler install (#8404)
Fix ingestion transform config bugs. (#8394)
Fix upsert inconsistency by snapshotting the validDocIds before reading the numDocs (#8392)
Fix bug when importing files with the same name in different directories (#8337)
Fix the missing NOT handling (#8366)
Fix setting of metrics compression type in RealtimeSegmentConverter (#8350)
Fix segment status checker to skip push in-progress segments (#8323)
Fix datetime truncate for multi-day (#8327)
Fix redirections for routes with access-token (#8285)
Fix CSV files surrounding space issue (#9028)
Fix suppressed exceptions in GrpcBrokerRequestHandler(#8272)
Left join ()
In-equi join ()
Full join ()
Right join ()
Semi join ()
Using keyword ()
Having ()
Order by ()
In/NotIn clause ()
Thread safe query planning ()
Partial query execution and round robin scheduling ()
Improve data table serde ()
Force commit consuming segments by in
add a freshness based consumption status checker by in
Add metrics to track controller segment download and upload requests in progress by in
Show most recent scheduling errors by in
Do not use aggregation result for distinct query in IntermediateResultsBlock by in
Emit metrics for ratio of actual consumption rate to rate limit in realtime tables by in
Allow hiding query console tab based on cluster config ()
Allow hiding pinot broker swagger UI by config ()
Add UI to show fine-grained minion task progress ()
Upgrade h3 lib from 3.7.2 to 4.0.0 to lower glibc requirement ()
Upgrade ZK version to 3.6.3 ()
Upgrade snakeyaml from 1.30 to 1.33 ()
Fix bug with logging request headers by in
Fix a UT that only shows up on host with more cores by in
Fix message count by in
select * FROM foo where text_col LIKE 'a%'select * from foo where text_col CONTAINS 'bar'Cast ()
LIke/Rexlike ()
Range predicate ()
Adding endpoint to download local log files for each component by in
[Feature] Add an option to search input files recursively in ingestion job. The default is set to true to be backward compatible. by in
add query cancel APIs on controller backed by those on brokers by in
Add Spark Job Launcher tool by in
Enable Consistent Data Push for Standalone Segment Push Job Runners by in
Allow server to directly return the final aggregation result by in
TierBasedSegmentDirectoryLoader to keep segments in multi-datadir by in
Adaptive Server Selection by in
[Feature] Support IsDistinctFrom and IsNotDistinctFrom by in
Allow ingestion of errored records with incorrect datatype by in
Allow setting custom time boundary for hybrid table queries by in
skip late cron job with max allowed delay by in
Do not allow implicit cast for BOOLEAN and TIMESTAMP by in
Add missing properties in CSV plugin by in
set MDC so that one can route minion task logs to separate files cleanly by in
Add a new API to fix segment date time in metadata by in
Update get bytes to return raw bytes of string and support getBytesMV by in
Exposing consumer's record lag in /consumingSegmentsInfo by in
Do not create dictionary for high-cardinality columns by in
get task runtime configs tracked in Helix by in
Add more options to json index by in
add SegmentTierAssigner and refine restful APIs to get segment tier info by in
Add segment level debug API by in
Add record availability lag for Kafka connector by in
notify servers that need to move segments to new tiers via SegmentReloadMessage by in
Allow to configure multi-datadirs as instance configs and a Quickstart example about them by in
Customize stopword for Lucene Index by in
Add memory optimized dimension table by in
ADLS file system upgrade by in
Added Delete Schema/Table pinot admin commands by in
Adding new ADLSPinotFS auth type: DEFAULT by in
Add rate limit to Kinesis requests by in
Adding configs for zk client timeout by in
add metrics entry offlineTableCount by in
refine query cancel resp msg by in
add @ManualAuthorization annotation for non-standard endpoints by in
Optimize ser/de to avoid using output stream by in
Add Support for Covariance Function by in
Throw an exception when MV columns are present in the order-by expression list in selection order-by only queries by in
Improve server query cancellation and timeout checking during execution by in
Add capabilities to ingest from another stream without disabling the realtime table by in
Add minMaxInvalid flag to avoid unnecessary needPreprocess by in
Add array cardinality function by in
TierBasedSegmentDirectoryLoader to keep segments in multi-datadir by in
Add support for custom null values in CSV record reader by in
Infer parquet reader type based on file metadata by in
Add Support for Cast Function on MV Columns by in
Allow ingestion of errored records with incorrect datatype by in
[Feature] Not Operator Transformation by in
Handle null string in CSV decoder by in
[Feature] Not scalar function by in
Add support for EXTRACT syntax and converts it to appropriate Pinot expression by in
Add support for Auth in controller requests in java query client by in
delete all related minion task metadata when deleting a table by in
BloomFilterRule should only recommend for supported column type by in
Support all the types in ParquetNativeRecordReader by in
Improve segment name check in metadata push by in
Allow expression transformer cotinue on error by in
skip late cron job with max allowed delay by in
Enhance and filter predicate evaluation efficiency by in
Deprecate instanceId Config For Broker/Minion Specific Configs by in
Optimize combine operator to fully utilize threads by in
Terminate the query after plan generation if timeout by in
[Feature] Support IsDistinctFrom and IsNotDistinctFrom by in
[Feature] Support Coalesce for Column Names by in
Disable logging for interrupted exceptions in kinesis by in
Benchmark thread cpu time by in
Use ISODateTimeFormat as default for SIMPLE_DATE_FORMAT by in
Extract the common logic for upsert metadata manager by in
Make minion task metadata manager methods more generic by in
Always pass clientId to kafka's consumer properties by in
Adaptive Server Selection by in
Refine IndexHandler methods a bit to make them reentrant by in
use MinionEventObserver to track finer grained task progress status on worker by in
Allow spaces in input file paths by in
Add support for gracefully handling the errors while transformations by in
Cache Deleted Segment Names in Server to Avoid SegmentMissingError by in
Handle Invalid timestamps by in
refine minion worker event observer to track finer grained progress for tasks by in
spark-connector should use v2/brokers endpoint by in
Remove netty server query support from presto-pinot-driver to remove pinot-core and pinot-segment-local dependencies by in
Adaptive Server Selection: Address pending review comments by in
track progress from within segment processor framework by in
Decouple ser/de from DataTable by in
collect file info like mtime, length while listing files for free by in
Extract record keys, headers and metadata from Stream sources by in
[pinot-spark-connector] Bump spark connector max inbound message size by in
refine the minion task progress api a bit by in
add parsing for AT TIME ZONE by in
Eliminate explosion of metrics due to gapfill queries by in
ForwardIndexHandler: Change compressionType during segmentReload by in
Introduce Segment AssignmentStrategy Interface by in
Add query interruption flag check to broker groupby reduction by in
adding optional client payload by in
[feature] distinct from scalar functions by in
Check data table version on server only for null handling by in
Add docId and column name to segment read exception by in
Sort scanning based operators by cardinality in AndDocIdSet evaluation by in
Do not fail CI when codecov upload fails by in
[Upsert] persist validDocsIndex snapshot for Pinot upsert optimization by in
broker filter by in
[feature] coalesce scalar by in
Allow setting custom time boundary for hybrid table queries by in
[GHA] add cache timeout by in
Optimize PinotHelixResourceManager.hasTable() by in
Include exception when upsert metadata manager cannot be created by in
allow to config task expire time by in
expose task finish time via debug API by in
Remove the wrong warning log in KafkaPartitionLevelConsumer by in
starting http server for minion worker conditionally by in
Make StreamMessage generic and a bug fix by in
Improve primary key serialization performance by in
[Upsert] Skip removing upsert metadata when shutting down the server by in
add array element at function by in
Handle the case when enableNullHandling is true and an aggregation function is used w/ a column that has an empty null bitmap by in
Support segment storage format without forward index by in
Adding SegmentNameGenerator type inference if not explicitly set in config by in
add version information to JMX metrics & component logs by in
remove unused RecordTransform/RecordFilter classes by in
Support rewriting forward index upon changing compression type for existing raw MV column by in
Support Avro's Fixed data type by in
[feature] [kubernetes] add loadBalancerSourceRanges to service-external.yaml for controller and broker by in
Limit up to 10 unavailable segments to be printed in the query exception by in
remove more unused filter code by in
Do not cache record reader in segment by in
make first part of user agent header configurable by in
optimize order by sorted ASC, unsorted and order by DESC cases by in
Enhance cluster config update API to handle non-string values properly by in
Reverts recommender REST API back to PUT (reverts PR ) by in
Remove invalid pruner names from server config by in
Using usageHelp instead of deprecated help in picocli commands by in
Handle unique query id on server by in
stateless group marker missing several by in
Support reloading consuming segment using force commit by in
Improve star-tree to use star-node when the predicate matches all the non-star nodes by in
add FetchPlanner interface to decide what column index to prefetch by in
Improve star-tree traversal using ArrayDeque by in
Handle errors in combine operator by in
return different error code if old version is not on master by in
Support creating dictionary at runtime for an existing column by in
check mutable segment explicitly instead of checking existence of indexDir by in
Remove leftover file before downloading segmentTar by in
add index key and size map to segment metadata by in
Use ideal state as source of truth for segment existence by in
Close Filesystem on exit with Minion Tasks by in
render the tables list even as the table sizes are loading by in
Add Support for IP Address Function by in
bubble up error messages from broker by in
Add support to disable the forward index for existing columns by in
show table metadata info in aggregate index size form by in
Preprocess immutable segments from REALTIME table conditionally when loading them by in
revert default timeout nano change in QueryConfig by in
AdaptiveServerSelection: Update stats for servers that have not responded by in
Add null value index for default column by in
[MergeRollupTask] include partition info into segment name by in
Adding a consumer lag as metric via a periodic task in controller by in
Deserialize Hyperloglog objects more optimally by in
Download offline segments from peers by in
Thread Level Usage Accounting and Query Killing on Server by in
Add max merger and min mergers for partial upsert by in
added pinot helm 0.2.6 with secure version pinot 0.11.0 by in
Combine the read access for replication config by in
add v1 ingress in helm chart by in
Optimize AdaptiveServerSelection for replicaGroup based routing by in
Do not sort the instances in InstancePartitions by in
Merge new columns in existing record with default merge strategy by in
Support disabling dictionary at runtime for an existing column by in
support BOOL_AND and BOOL_OR aggregate functions by in
Use Pulsar AdminClient to delete unused subscriptions by in
add table sort function for table size by in
In Kafka consumer, seek offset only when needed by in
fallback if no broker found for the specified table name by in
Allow liveness check during server shutting down by in
Allow segment upload via Metadata in MergeRollup Minion task by in
Add back the Helix workaround for missing IS change by in
Allow uploading realtime segments via CLI by in
Add capability to update and delete table config via CLI by in
default to TAR if push mode is not set by in
load startree index via segment reader interface by in
Allow collections for MV transform functions by in
Construct new IndexLoadingConfig when loading completed realtime segments by in
Make GET /tableConfigs backwards compatible in case schema does not match raw table name by in
feat: add compressed file support for ORCRecordReader by in
Add Variance and Standard Deviation Aggregation Functions by in
enable MergeRollupTask on realtime tables by in
Update cardinality when converting raw column to dict based by in
Add back auth token for UploadSegmentCommand by in
Improving gz support for avro record readers by in
Default column handling of noForwardIndex and regeneration of forward index on reload path by in
[Feature] Support coalesce literal by in
Ability to initialize S3PinotFs with serverSideEncryption properties when passing client directly by in
handle pending minion tasks properly when getting the task progress status by in
allow gauge stored in metric registry to be updated by in
support case-insensitive query options in SET syntax by in
pin versions-maven-plugin to 2.13.0 by in
Pulsar Connection handler should not spin up a consumer / reader by in
Handle in-memory segment metadata for index checking by in
Support the cross-account access using IAM role for S3 PinotFS by in
report minion task metadata last update time as metric by in
support SKEWNESS and KURTOSIS aggregates by in
emit minion task generation time and error metrics by in
Use the same default time value for all replicas by in
Reduce the number of segments to wait for convergence when rebalancing by in
Add UI to track segment reload progress ()
Show minion task runtime config details in UI ()
Redefine the segment status ()
Show an option to reload the segments during edit schema ()
Load schema UI async ()
Fix blank screen when redirect to unknown app route ()
Upgrade RoaringBitmap from 0.9.28 to 0.9.35 ()
Upgrade spotless-maven-plugin from 2.9.0 to 2.28.0 ()
Upgrade decode-uri-component from 0.2.0 to 0.2.2 ()
Fix issue with auth AccessType in Schema REST endpoints by in
Fix PerfBenchmarkRunner to skip the tmp dir by in
Fix thrift deserializer thread safety issue by in
Fix transformation to string for BOOLEAN and TIMESTAMP by in
[hotfix] Add VARBINARY column to switch case branch by in
Fix annotation for "/recommender" endpoint by in
Fix jdk8 build issue due to missing pom dependency by in
Fix pom to use pinot-common-jdk8 for pinot-connector jkd8 java client by in
Fix log to reflect job type by in
[Bugfix] schema update bug fix by in
fix histogram null pointer exception by in
Fix thread safety issues with SDF (WIP) by in
Bug fix: failure status in ingestion jobs doesn't reflect in exit code by in
Fix skip segment logic in MinMaxValueBasedSelectionOrderByCombineOperator by in
Fix the bug of hybrid table request using the same request id by in
Fix the range check for range index on raw column by in
Fix Data-Correctness Bug in GTE Comparison in BinaryOperatorTransformFunction by in
extend PinotFS impls with listFilesWithMetadata and some bugfix by in
fix null transform bound check by in
Fix JsonExtractScalar when no value is extracted by in
Fix AddTable for realtime tables by in
Fix some type convert scalar functions by in
fix spammy logs for ConfluentSchemaRegistryRealtimeClusterIntegrationTest [MINOR] by in
Fix timestamp index on column of preserved key by in
Fix record extractor when ByteBuffer can be reused by in
Fix explain plan ALL_SEGMENTS_PRUNED_ON_SERVER node by in
Fix time validation when data type needs to be converted by in
UI: fix incorrect task finish time by in
Fix the bug where uploaded segments cannot be deleted on real-time table by in
[bugfix] correct the dir for building segments in FileIngestionHelper by in
Fix NonAggregationGroupByToDistinctQueryRewriter by in
fix distinct result return by in
Fix GcsPinotFS by in
fix DataSchema thread-safe issue by in
Bug fix: Add missing table config fetch for /tableConfigs list all by in
Fix re-uploading segment when the previous upload failed by in
Fix string split which should be on whole separator by in
Fix server request sent delay to be non-negative by in
bugfix: Add missing BIG_DECIMAL support for GenericRow serde by in
Fix extra restlet resource test which should be stateless by in
AdaptiveServerSelection: Fix timer by in
fix PinotVersion to be compatible with prometheus by in
Fix the setup for ControllerTest shared cluster by in
[hotfix]groovy class cache leak by in
Fix TIMESTAMP index handling in SegmentMapper by in
Fix the server admin endpoint cache to reflect the config changes by in
[bugfix] fix case-when issue by in
[bugfix] Let StartControllerCommand also handle "pinot.zk.server", "pinot.cluster.name" in default conf/pinot-controller.conf by in
[hotfix] semi-join opt by in
Fixing the rebalance issue for real-time table with tier by in
UI: show segment debug details when segment is in bad state by in
Fix the replication in segment assignment strategy by in
fix potential fd leakage for SegmentProcessorFramework by in
Fix NPE when reading ZK address from controller config by in
have query table list show search bar; fix InstancesTables filter by in
[pinot-spark-connector] Fix empty data table handling in GRPC reader by in
[bugfix] fix mergeRollupTask metrics by in
Bug fix: Get correct primary key count by in
Fix issues for realtime table reload by in
UI: fix segment status color remains same in different table page by in
Fix bloom filter creation on BYTES by in
[hotfix] broker selection not using table name by in
Fix race condition when 2 segment upload occurred for the same segment by in
fix timezone_hour/timezone_minute functions by in
[Bugfix] Move brokerId extraction to BaseBrokerStarter by in
Fix ser/de for StringLongPair by in
bugfix dir check for HadoopPinotFS.copyFromLocalDir by in
Bugfix: Use correct exception import in TableRebalancer. by in
Fix NPE in AbstractMetrics From Race Condition by in
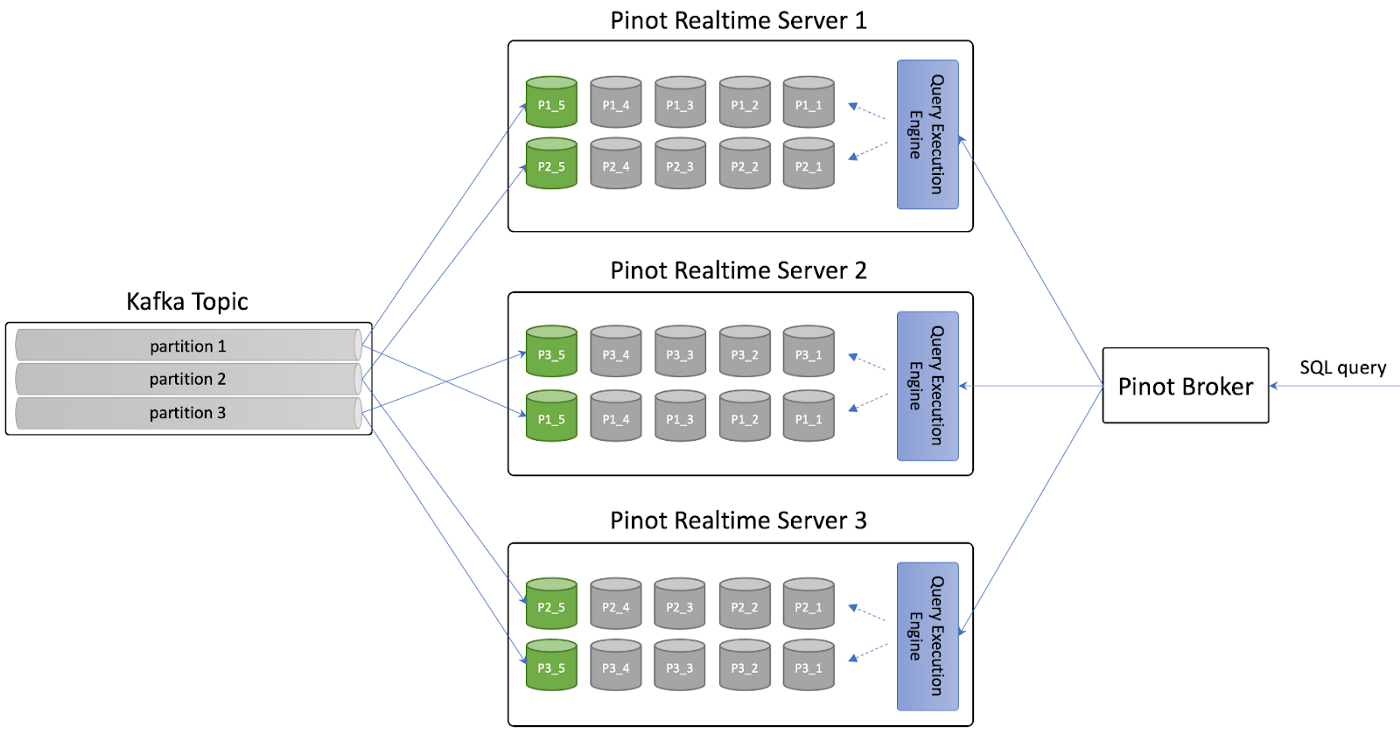
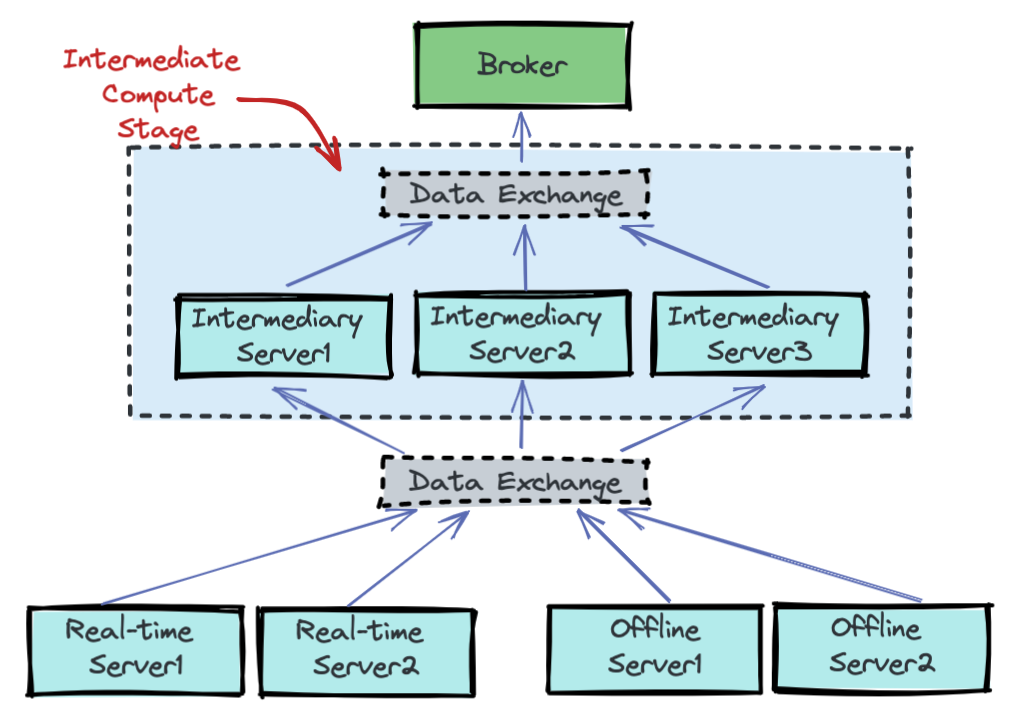
This release introduces some new great features, performance enhancements, UI improvements, and bug fixes which are described in details in the following sections. The release was cut from this commit fd9c58a.
The dependency graph for plug-and-play architecture that was introduced in release has been extended and now it contains new nodes for Pinot Segment SPI.
Implement NOT Operator
Add DistinctCountSmartHLLAggregationFunction which automatically store distinct values in Set or HyperLogLog based on cardinality
Add LEAST and GREATEST functions
Show Reported Size and Estimated Size in human readable format in UI
Make query console state URL based
Improve query console to not show query result when multiple columns have the same name
Reuse regex matcher in dictionary based LIKE queries
Early terminate orderby when columns already sorted
Do not do another pass of Query Automaton Minimization
Adding NoopPinotMetricFactory and corresponding changes
Allow to specify fixed segment name for SegmentProcessorFramework
Move all prestodb dependencies into a separated module
Fix string comparisons
Bugfix for order-by all sorted optimization
Fix dockerfile
Fix the issue with HashCode partitioning function
Fix the issue with validation on table creation
Change PinotFS API's
Handle SELECT * with extra columns
Add FILTER clauses for aggregates
Add ST_Within function
Handle semicolon in query
Add EXPLAIN PLAN
Improve Pinot dashboard tenant view to show correct amount of servers and brokers
Fix issue with opening new tabs from Pinot Dashboard
Fix issue with Query console going blank on syntax error
Make query stats always show even there's error
Implement OIDC auth workflow in UI
Add tooltip and modal for table status
Add option to wrap lines in custom code mirror
Add ability to comment out queries with cmd + /
Return exception when unavailable segments on empty broker response
Properly handle the case where segments are missing in externalview
Add TIMESTAMP to datetime column Type
Improve RangeBitmap by upgrading RoaringBitmap
Optimize geometry serializer usage when literal is available
Improve performance of no-dictionary group by
Allocation free DataBlockCache lookups
Prune unselected THEN statements in CaseTransformFunction
Aggregation delay conversion to double
Reduce object allocation rate in ExpressionContext or FunctionContext
Lock free DimensionDataTableManager
Improve json path performance during ingestion by upgrading JsonPath
Reduce allocations and speed up StringUtil.sanitizeString
Faster metric scans - ForwardIndexReader
Unpeel group by 3 ways to enable vectorization
Power of 2 fixed size chunks
Don't use mmap for compression except for huge chunks
Exit group-by marking loop early
Improve performance of base chunk forward index write
Cache JsonPaths to prevent compilation per segment
Use LZ4 as default compression mode
Peel off special case for 1 dimensional groupby
Bump roaringbitmap version to improve range queries performance
Include docIds in Projection and Transform block
Automatically update broker resource on broker changes
Update ScalarFunction annotation from name to names to support function alias.
Implemented BoundedColumnValue partition function
Add copy recursive API to pinotFS
Add Support for Getting Live Brokers for a Table (without type suffix)
Pinot docker image - cache prometheus rules
In BrokerRequestToQueryContextConverter, remove unused filterExpressionContext
Adding retention period to segment delete REST API
Pinot docker image - upgrade prometheus and scope rulesets to components
Allow segment name postfix for SegmentProcessorFramework
Superset docker image - update pinotdb version in superset image
Add retention period to deleted segment files and allow table level overrides
Remove incubator from pinot and superset
Adding table config overrides for disabling groovy
Optimise sorted docId iteration order in mutable segments
Adding secure grpc query server support
Move Tls configs and utils from pinot-core to pinot-common
Reduce allocation rate in LookupTransformFunction
Allow subclass to customize what happens pre/post segment uploading
Enable controller service auto-discovery in Jersey framework
Add support for pushFileNamePattern in pushJobSpec
Add additionalMatchLabels to helm chart
Simulate rsvps after meetup.com retired the feed
Adding more checkstyle rules
Add persistence.extraVolumeMounts and persistence.extraVolumes to Kubernetes statefulsets
Adding scala profile for kafka 2.x build and remove root pom scala dependencies
Allow realtime data providers to accept non-kafka producers
Enhance revertReplaceSegments api
Adding broker level config for disabling Pinot queries with Groovy
Make presto driver query pinot server with SQL
Adding controller config for disabling Groovy in ingestionConfig
Adding main method for LaunchDataIngestionJobCommand for spark-submit command
Add auth token for segment replace rest APIs
Add allowRefresh option to UploadSegment
Add Ingress to Broker and Controller helm charts
Improve progress reporter in SegmentCreationMapper
St_* function error messages + support literal transform functions
Add schema and segment crc to SegmentDirectoryContext
Extend enableParallePushProtection support in UploadSegment API
Support BOOLEAN type in Config Recommendation Engine
Add a broker metric to distinguish exception happens when acquire channel lock or when send request to server
Add pinot.minion prefix on minion configs for consistency
Enable broker service auto-discovery in Jersey framework
Timeout if waiting server channel lock takes a long time
Wire EmptySegmentPruner to routing config
Support for TIMESTAMP data type in Config Recommendation Engine
Listener TLS customization
Add consumption rate limiter for LLConsumer
Implement Real Time Mutable FST
Allow quickstart to get table files from filesystem
Add support for instant segment deletion
Add a config file to override quickstart configs
Add pinot server grpc metadata acl
Move compatibility verifier to a separate module
Move hadoop and spark ingestion libs from plugins directory to external-plugins
Add global strategy for partial upsert
Upgrade kafka to 2.8.1
Created EmptyQuickstart command
Allow SegmentPushUtil to push realtime segment
Add ignoreMerger for partial upsert
Make task timeout and concurrency configurable
Return 503 response from health check on shut down
Pinot-druid-benchmark: set the multiValueDelimiterEnabled to false when importing TPC-H data
Cleanup: Remove remaining occurrences of incubator.
Refactor segment loading logic in BaseTableDataManager to decouple it with local segment directory
Improving segment replacement/revert protocol
PinotConfigProvider interface
Enhance listSegments API to exclude the provided segments from the output
Remove outdated broker metric definitions
Add skip key for realtimeToOffline job validation
Upgrade async-http-client
Allow Reloading Segments with Multiple Threads
Ignore query options in commented out queries
Remove TableConfigCache which does not listen on ZK changes
Switch to zookeeper of helm 3.0x
Use a single react hook for table status modal
Add debug logging for realtime ingestion
Separate the exception for transform and indexing for consuming records
Disable JsonStatementOptimizer
Make index readers/loaders pluggable
Make index creator provision pluggable
Support loading plugins from multiple directories
Update helm charts to honour readinessEnabled probes flags on the Controller, Broker, Server and Minion StatefulSets
Support non-selection-only GRPC server request handler
GRPC broker request handler
Add validator for SDF
Support large payload in zk put API
Push JSON Path evaluation down to storage layer
When upserting new record, index the record before updating the upsert metadata
Add Post-Aggregation Gapfilling functionality.
Clean up deprecated fields from segment metadata
Remove deprecated method from StreamMetadataProvider
Obtain replication factor from tenant configuration in case of dimension table
Use valid bucket end time instead of segment end time for merge/rollup delay metrics
Make pinot start components command extensible
Make upsert inner segment update atomic
Clean up deprecated ZK metadata keys and methods
Add extraEnv, envFrom to statefulset help template
Make openjdk image name configurable
Add getPredicate() to PredicateEvaluator interface
Make split commit the default commit protocol
Pass Pinot connection properties from JDBC driver
Add Pinot client connection config to allow skip fail on broker response exception
Change default range index version to v2
Put thread timer measuring inside of wall clock timer measuring
Add getRevertReplaceSegmentRequest method in FileUploadDownloadClient
Add JAVA_OPTS env var in docker image
Split thread cpu time into three metrics
Add config for enabling realtime offset based consumption status checker
Add timeColumn, timeUnit and totalDocs to the json segment metadata
Set default Dockerfile CMD to -help
Add getName() to PartitionFunction interface
Support Native FST As An Index Subtype for FST Indices
Add forceCleanup option for 'startReplaceSegments' API
Add config for keystore types, switch tls to native implementation, and add authorization for server-broker tls channel
Extend FileUploadDownloadClient to send post request with json body
Ensure partition function never return negative partition
Handle indexing failures without corrupting inverted indexes
Fixed broken HashCode partitioning
Fix segment replace test
Fix filtered aggregation when it is mixed with regular aggregation
Fix FST Like query benchmark to remove SQL parsing from the measurement
Do not identify function types by throwing exceptions
Fix regression bug caused by sharing TSerializer across multiple threads
Fix validation before creating a table
Check cron schedules from table configs after subscribing child changes
Disallow duplicate segment name in tar file
Fix storage quota checker NPE for Dimension Tables
Fix TraceContext NPE issue
Update gcloud libraries to fix underlying issue with api's with CMEK
Fix error handling in jsonPathArray
Fix error handling in json functions with default values
Fix controller config validation failure for customized TLS listeners
Validate the numbers of input and output files in HadoopSegmentCreationJob
Broker Side validation for the query with aggregation and col but without group by
Improve the proactive segment clean-up for REVERTED
Allow JSON forward indexes
Fix the PinotLLCRealtimeSegmentManager on segment name check
Always use smallest offset for new partitionGroups
Fix RealtimeToOfflineSegmentsTaskExecutor to handle time gap
Refine segment consistency checks during segment load
Fixes for various JDBC issues
Delete tmp- segment directories on server startup
Fix ByteArray datatype column metadata getMaxValue NPE bug and expose maxNumMultiValues
Fix the issues that Pinot upsert table's uploaded segments get deleted when a server restarts.
Fixed segment upload error return
Fix QuerySchedulerFactory to plug in custom scheduler
Fix the issue with grpc broker request handler not started correctly
Fix realtime ingestion when an entire batch of messages is filtered out
Move decode method before calling acquireSegment to avoid reference count leak
Fix semaphore issue in consuming segments
Add bootstrap mode for PinotServiceManager to avoid glitch for health check
Fix the broker routing when segment is deleted
Fix obfuscator not capturing secretkey and keytab
Fix segment merge delay metric when there is empty bucket
Fix QuickStart by adding types for invalid/missing type
Use oldest offset on newly detected partitions
Fix javadoc to compatible with jdk8 source
Handle null segment lineage ZNRecord for getSelectedSegments API
Handle fields missing in the source in ParquetNativeRecordReader
